
金融大模型升级决策平台!马上消费发布“天镜”3.0破解经验碎片化难题
金融大模型升级决策平台!马上消费发布“天镜”3.0破解经验碎片化难题6月6日, 由中共重庆市委金融委员会办公室、重庆市商务委员会、重庆两江新区管理委员会共同指导,由消费金融服务联盟、打击金融领域黑产联盟(AIF)联合主办,马上消费等19家金融机构、重庆广播电视(总台)第1眼TV等协办的“2025消费金融生态大会”在重庆举行。
来自主题: AI资讯
9031 点击 2025-06-07 11:24
 搜索
搜索
6月6日, 由中共重庆市委金融委员会办公室、重庆市商务委员会、重庆两江新区管理委员会共同指导,由消费金融服务联盟、打击金融领域黑产联盟(AIF)联合主办,马上消费等19家金融机构、重庆广播电视(总台)第1眼TV等协办的“2025消费金融生态大会”在重庆举行。

AI 开始从理解文字,全面进化到建模世界、操控实体、模拟大脑、解构分子。

自ChatGPT问世,李明顺成了“网红”。他没有下场做大模型,而是密集地通过短视频平台输出对AI的看法。
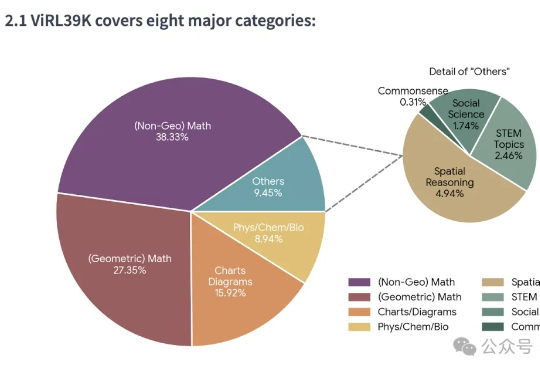
在文本推理领域,以GPT-o1、DeepSeek-R1为代表的 “慢思考” 模型凭借显式反思机制,在数学和科学任务上展现出远超 “快思考” 模型(如 GPT-4o)的优势。
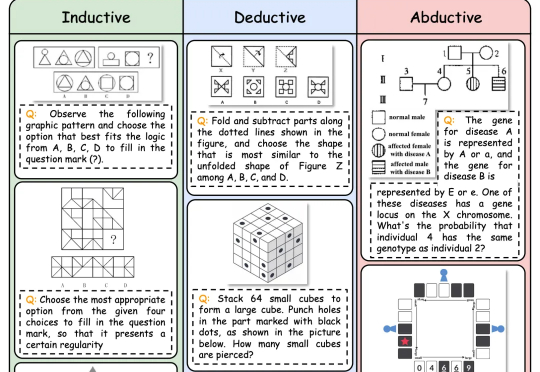
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)

这500天里,AI视频模型,从寥寥星火,也到如今满眼璀璨星河。这500天里,天翻地覆,绣口一吐,就是近半个盛唐。 从孤舟一叶,到如今千帆竞渡如潮。
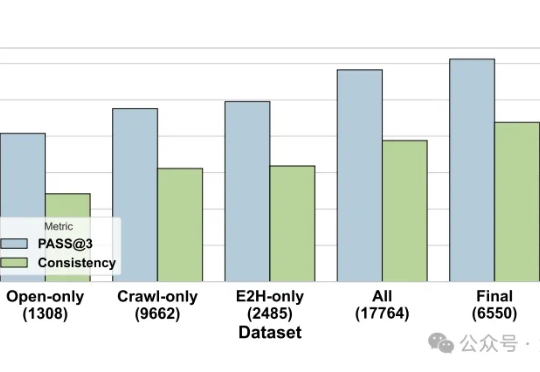
能够完成多步信息检索任务,涵盖多轮推理与连续动作执行的智能体来了。通义实验室推出WebWalker(ACL2025)续作自主信息检索智能体WebDancer。
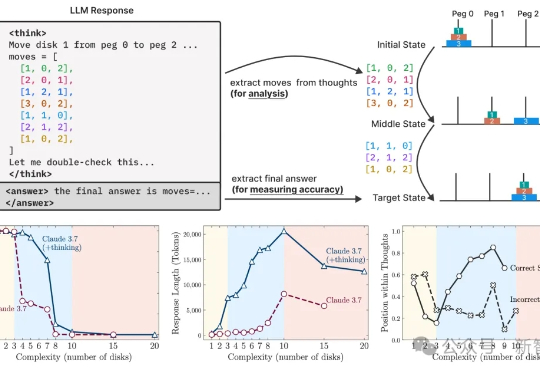
苹果最新研究揭示大推理模型(LRM)在高复杂度任务中普遍「推理崩溃」:思考路径虽长,却常在关键时刻放弃。即便给予明确算法提示,模型亦无法稳定执行,暴露推理机制的局限性。
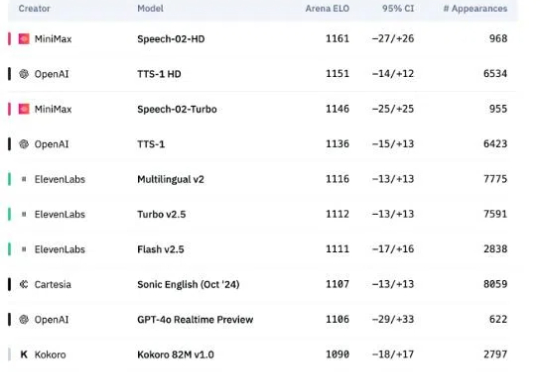
2 月份,我们在《AI 语音,真的有感情了?》选题中,选取了知名影视剧《甄嬛传》中的片段来测试 4 款 AI 语音合成模型在情感表达上的表现。当时的结论是,AI 语音模型们的表现力依然不足,仍有待加强。
相信大家已经听过很多 AI 在生命科学领域的一次次革命性进展,甚至 2024 年的诺贝尔化学奖都颁给了计算生物学领域的科学家们。