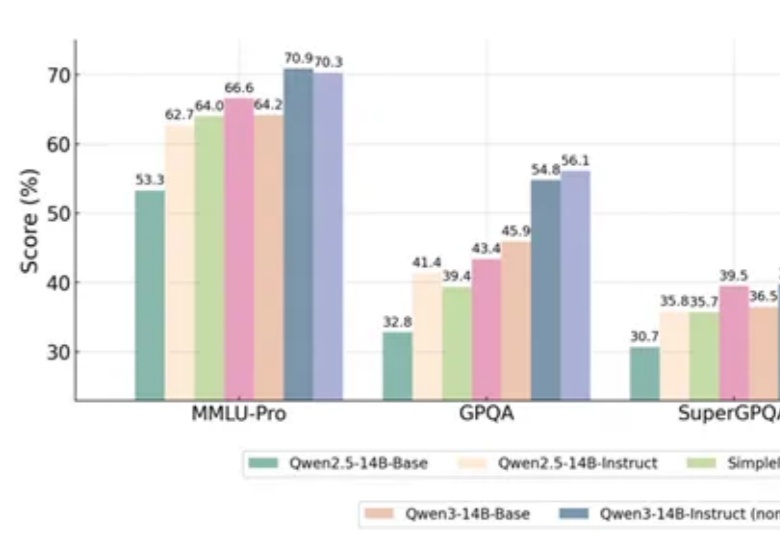
超越GPT-4o!华人团队新框架让Qwen跨领域推理提升10%,刷新12项基准测试
超越GPT-4o!华人团队新框架让Qwen跨领域推理提升10%,刷新12项基准测试一项新的强化学习方法,直接让Qwen性能大增,GPT-4o被赶超!
来自主题: AI技术研报
7277 点击 2025-06-04 10:50
 搜索
搜索
一项新的强化学习方法,直接让Qwen性能大增,GPT-4o被赶超!
不用换模型、不用堆参数,靠 SUGAR 模型性能大增!

想象一下,你在一个陌生的房子里寻找合适的礼物盒包装泰迪熊,需要记住每个房间里的物品特征、位置关系,并根据反馈调整行动。
最近AI圈子里有两个特别有意思的项目,一个是谷歌DeepMind的AlphaEvolve,另一个是UBC大学的Darwin Gödel Machine(简称DGM)。
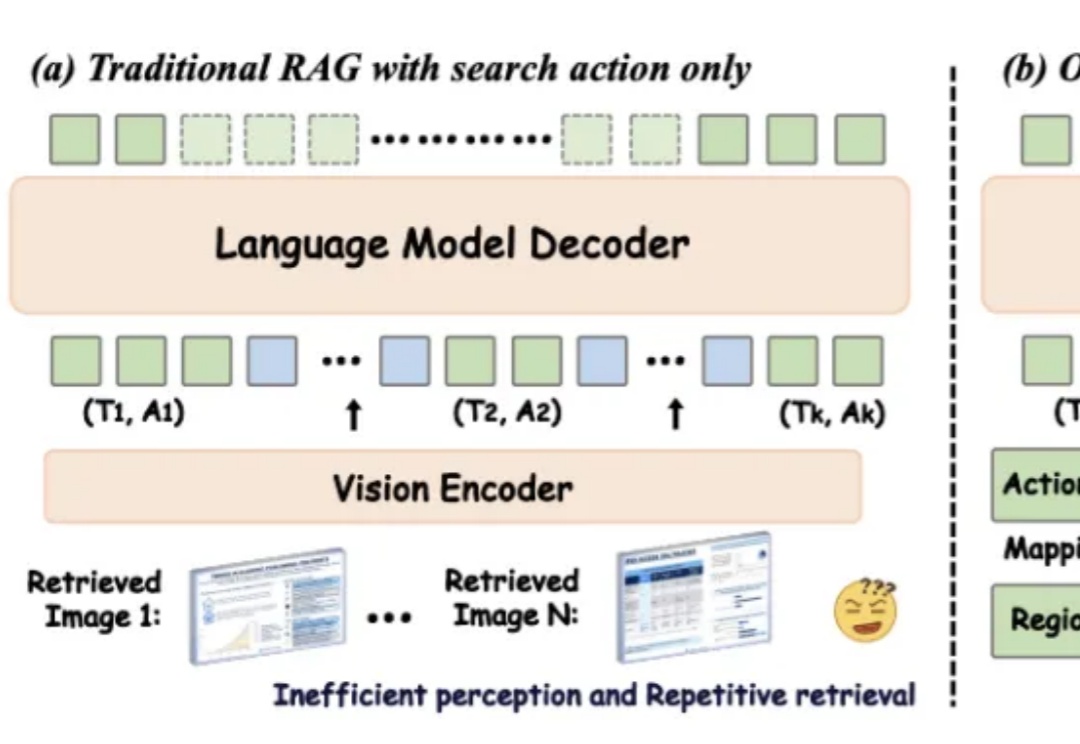
在数字化时代,视觉信息在知识传递和决策支持中的重要性日益凸显。然而,传统的检索增强型生成(RAG)方法在处理视觉丰富信息时面临着诸多挑战。一方面,传统的基于文本的方法无法处理视觉相关数据;另一方面,现有的视觉 RAG 方法受限于定义的固定流程,难以有效激活模型的推理能力。
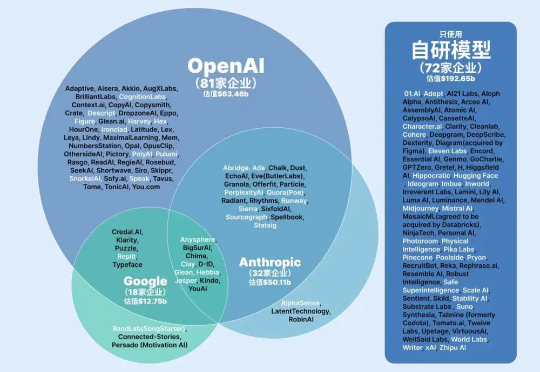
全球AI原生企业围绕OpenAI、Anthropic和谷歌三大生态阵营发展,形成开放多元、安全导向和技术闭环的差异化格局。企业通过多模型接入、自研模型及垂直深耕等策略竞争,生态构建聚焦开发者工具、行业渗透和价格策略,当前行业仍处动态演变阶段,尚未形成最终格局。
《智能涌现》从多名独立信源处得知,大模型“六小虎”之一的阶跃星辰,C端AI应用布局,近半年来出现了以下调整:2024年12月,角色扮演类Agent产品“冒泡鸭”停止大范围投入,团队合并至对话产品“跃问”(现更名为“阶跃AI”),目前仅留部分员工运维。

智源研究院发布开源模型Video-XL-2,显著提升长视频理解能力。该模型在效果、处理长度与速度上全面优化,支持单卡处理万帧视频,编码2048帧仅需12秒。

发展教育大模型需要新的数据和评估体系!北京理工大学高扬老师团队推出EduBench,是首个专为教育场景打造的综合评估基准,涵盖9大教育场景、12个多视角评估维度、超4000个教育情境。通过多维度评估指标体系和人工标注一致性计算,确保评估可靠性,助力教育大模型发展,推动教育智能化。

首个专为ALLMs(音频大语言模型)设计的多维度可信度评估基准来了。