Correlations:氛围测试你的向量模型
Correlations:氛围测试你的向量模型在今年 ICLR 会议上,我们被问到最多且最有意思的问题是:像 Jina AI 这样的向量搜索模型提供商,除了在 MTEB 上做基准测试,会不会做些氛围测试 (Vibe-testing)?
来自主题: AI技术研报
10777 点击 2025-05-31 15:20
 搜索
搜索
在今年 ICLR 会议上,我们被问到最多且最有意思的问题是:像 Jina AI 这样的向量搜索模型提供商,除了在 MTEB 上做基准测试,会不会做些氛围测试 (Vibe-testing)?

好家伙,AI意外生成的内核(kernel),性能比人类专家专门优化过的还要好!
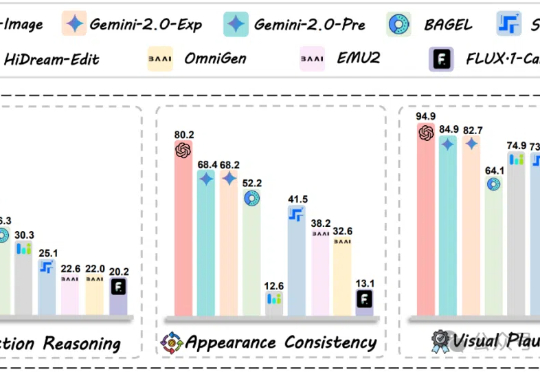
GPT-4o-Image也只能完成28.9%的任务,图像编辑评测新基准来了!360个全部由人类专家仔细思考并校对的高质量测试案例,暴露多模态模型在结合推理能力进行图像编辑时的短板。

FLUX.1 Kontext是一款融合即时文本图像编辑与文本到图像生成的新一代模型,支持文本与图像提示,角色一致性强,速度快达GPT-Image-1的8倍。

现在,请大家一起数一下“1”、“2”。OK,短短2秒钟时间,一个准万亿MoE大模型就已经吃透如何解一道高等数学大题了!而且啊,这个大模型还是不用GPU来训练,全流程都是大写的“国产”的那种。
字节跳动开源了一个口碑还不错的模型——BAGEL (ByteDance Agnostic Generation and Empathetic Language model), 一个统一多模态基础模型。啥叫“统一”?一个模型就能同时理解和生成文本、图像、视频!
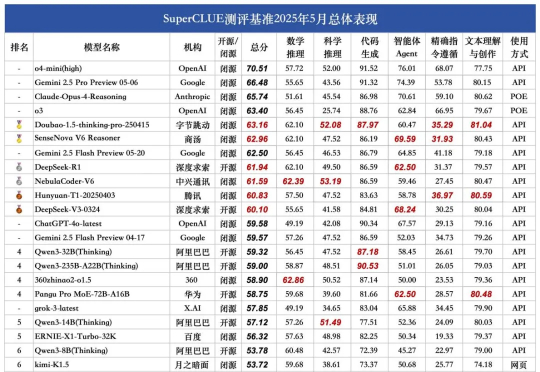
就在刚刚,中兴通讯星云大模型获推理榜总分第一,总榜并列第二!而在数学推理、科学推理、代码生成的细分赛道上,它同样表现抢眼。更难得的是,它是业内少数通过国家级权威安全认证的大模型。

文章以第一人称视角,讲述一名AI自媒体博主因行业竞争与技术迭代陷入深度焦虑的过程,最终通过反思意识到焦虑源于攀比与生存恐惧,而非技术本身。核心观点是接纳自身局限、明确独特价值、转向合作与好奇驱动,并提出三条实用建议,强调应对AI焦虑需聚焦个人定位而非盲目追赶。

豆包、文心一言、DeepSeek、元宝……这些国产AI工具,正在大规模进入职场内容流里。我们以为它们是工具,其实它们更像是一种“说得太像真的语气”,让每个使用者都可能在不经意间交出判断力。

文章探讨AI时代深度思考的困境:大语言模型使人类思维系统萎缩,即时生成内容取代有机思考过程,削弱直觉与思辨力。作者以自身创作瓶颈为例,指出依赖AI导致认知基础流失,廉价知识无法替代深层理解,强调原始思考过程的价值,认为未经修饰的人类思考仍有独特意义。