速递|Buildots完成4500万美元D轮融资,用AI模型+计算机视觉破解建筑业“信息脱节”难题
速递|Buildots完成4500万美元D轮融资,用AI模型+计算机视觉破解建筑业“信息脱节”难题在建筑行业中,管理人员很容易与现场实际情况脱节。他们需要同时处理多项任务,包括掌握成本动态、与所有利益相关方沟通,以及评估与承包商账单和绩效等方面相关的风险。
来自主题: AI资讯
9179 点击 2025-05-30 20:11
 搜索
搜索
在建筑行业中,管理人员很容易与现场实际情况脱节。他们需要同时处理多项任务,包括掌握成本动态、与所有利益相关方沟通,以及评估与承包商账单和绩效等方面相关的风险。

AI生图新突破!一个模型同时接受文本和图像输入。
提质不加价,可灵新版视频生成模型正式登场!新版本依然是一石激起千层浪,不到24小时就有超过72万次阅读。我们也带来了新鲜实测!

多模态大模型(MLLM)在静态图像上已经展现出卓越的 OCR 能力,能准确识别和理解图像中的文字内容。MME-VideoOCR 致力于系统评估并推动MLLM在视频OCR中的感知、理解和推理能力。

来和机器狗一起运动不?你的羽毛球搭子来了!无需人工协助,仅靠强化学习,机器狗子就学会了羽毛球哐哐对打。基于强化学习,研究人员开发了机器狗的全身视觉运动控制策略,同步控制腿部(18个自由度)移动,和手臂挥拍动作。

多AI智能体系统的复杂构建与优化,长期以来是用智能体解决科研问题和场景落地的瓶颈。来自英国格拉斯哥大学的研究团队发布了全球首个AI智能体自进化开源框架EvoAgentX,通过引入自我进化机制,打破了传统多智能体系统在构建和优化中的限制!
人类在面对简单提问时常常不假思索直接回答,只有遇到复杂难题才会认真推理。

Cursor放出了一个接近1小时的内部团队讨论视频,深度分析了他们用到的技术和思考,使得我们有机会深入了解了 Cursor 团队内部关于训练超人级编程模型的讨论,他们的观点让我重新思考了 AI 辅助编程的未来。这些来自一线研究者和工程师的见解,揭示了当前 AI 编程领域最前沿的挑战和突破方向。
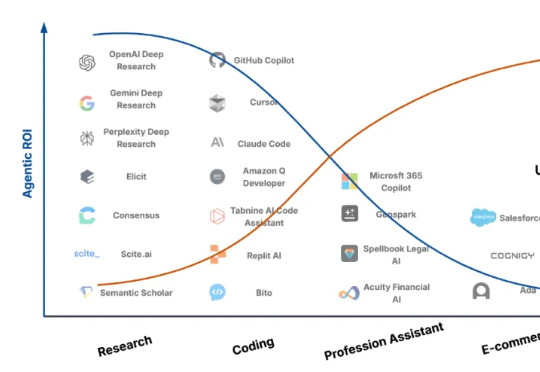
上海交通大学联合中科大在本文中指出:现阶段大模型智能体的主要障碍不在于模型能力不足,而在于其「Agentic ROI」尚未达到实用化门槛。研究团队提出 Agentic ROI(Agentic Return on Investment)这一核心指标,用于衡量一个大模型智能体在真实使用场景中所带来的「信息收益」与其「使用成本」之间的比值:

昨晚,终于等到了DeepSeek-R1-0528官宣。升级后的模型性能直逼o3和Gemini 2.5 Pro。如今,DeepSeek真正坐实了全球开源王者的称号,并成为了第二大AI实验室。