
中国团队让AI拥有「视觉想象力」,像人类一样脑补画面来思考
中国团队让AI拥有「视觉想象力」,像人类一样脑补画面来思考在人类的认知过程中,视觉思维(Visual Thinking)扮演着不可替代的核心角色,这一现象贯穿于各个专业领域和日常生活的方方面面。
来自主题: AI技术研报
11030 点击 2025-05-30 12:53
 搜索
搜索
在人类的认知过程中,视觉思维(Visual Thinking)扮演着不可替代的核心角色,这一现象贯穿于各个专业领域和日常生活的方方面面。

在最新的 LangChain Interrupt 峰会上,AI Fund 创始人吴恩达与 LangChain 联合创始人 Harrison Chase 展开了一场对话。

斯坦福Hazy实验室推出新一代低延迟推理引擎「Megakernel」,将Llama-1B模型前向传播完整融合进单一GPU内核,实现推理时间低于1毫秒。在B200上每次推理仅需680微秒,比vLLM快3.5倍。

近日,NVIDIA 联合香港大学、MIT 等机构重磅推出 Fast-dLLM,以无需训练的即插即用加速方案,实现了推理速度的突破!通过创新的技术组合,在不依赖重新训练模型的前提下,该工作为扩散模型的推理加速带来了突破性进展。本文将结合具体技术细节与实验数据,解析其核心优势。
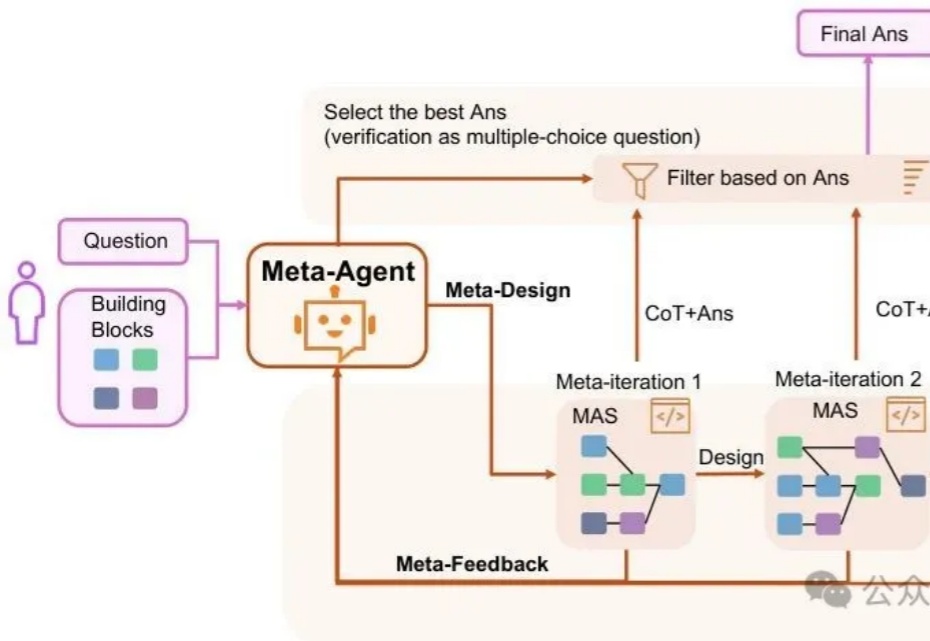
主席在《矛盾论》中强调"具体问题具体分析,是Marxism的活的灵魂"。而在AI领域,我们终于有了一个能够践行这一哲学思想的技术框架——MAS-ZERO,帮我们构建能够因地制宜、因时制宜的智能系统。
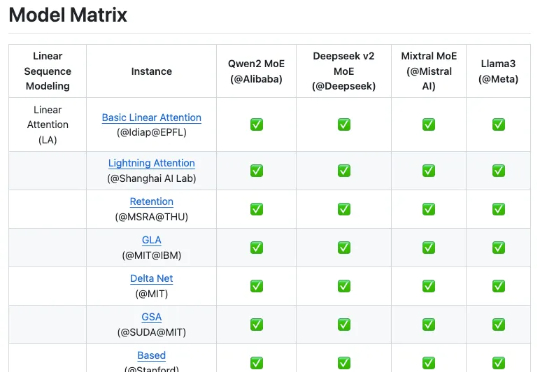
来自上海人工智能实验室团队的最新成果 Linear-MoE,首次系统性地实现了线性序列建模与 MoE 的高效结合,并开源了完整的技术框架,包括 Modeling 和 Training 两大部分,并支持层间混合架构。为下一代基础模型架构的研发提供了有价值的工具和经验。

文章探讨人们对AI生成内容的鉴定行为本质:技术层面无意义,因AI可精准模仿人类风格,而内容价值应取决于质量而非来源。分析鉴定行为源于人类中心主义偏见和社会表演需求,预测未来实质性鉴定将消失,但表演性鉴定会因社交攀比持续存在。

“今天的寒门,是不懂AI的家庭”,这个观点一落入眼帘,就抓住了海淀妈妈郑瑞虹的注意。
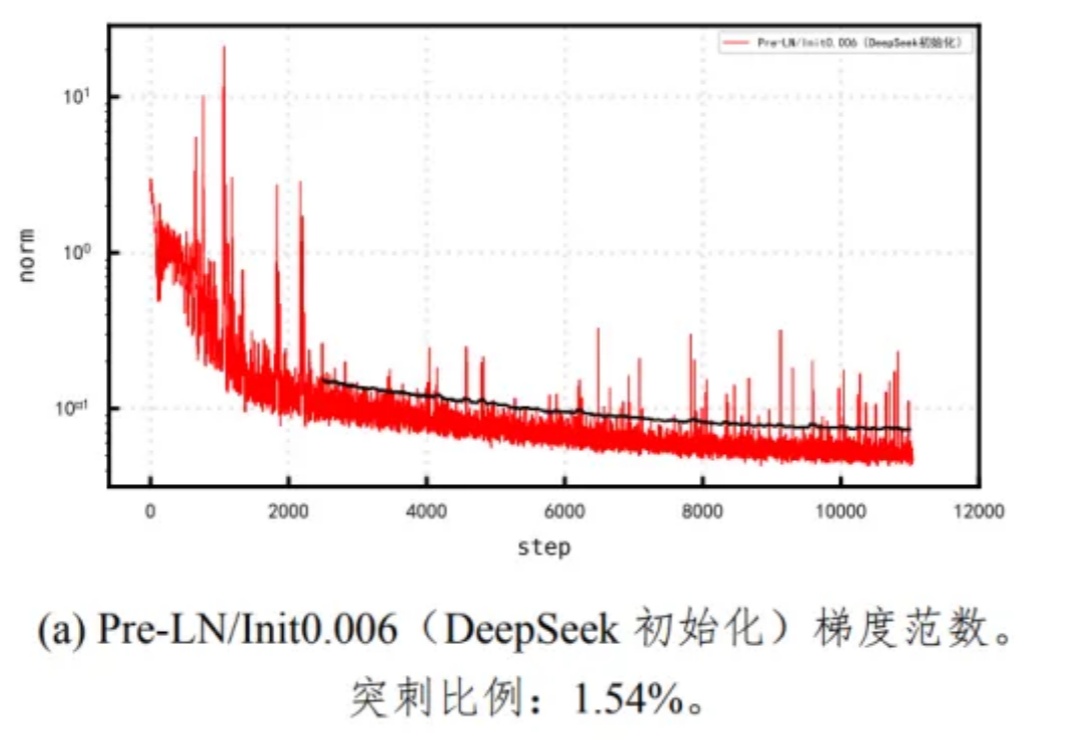
Pangu Ultra MoE 是一个全流程在昇腾 NPU 上训练的准万亿 MoE 模型,此前发布了英文技术报告[1]。最近华为盘古团队发布了 Pangu Ultra MoE 模型架构与训练方法的中文技术报告,进一步披露了这个模型的细节。
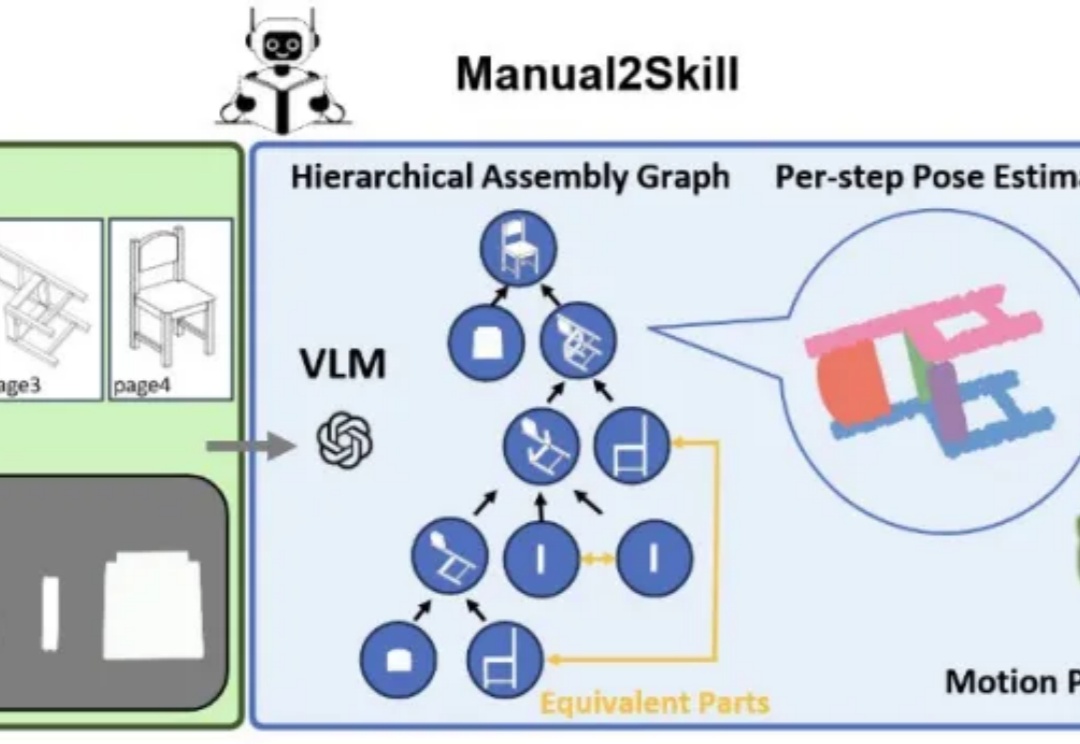
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。