无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归
无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归。曾因llya离职OpenAI,在互联网上掀起讨论飓风的柏拉图表示假说提出:所有足够大规模的图像模型都具有相同的潜在表示。
来自主题: AI技术研报
9395 点击 2025-05-24 11:46
 搜索
搜索
无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归。曾因llya离职OpenAI,在互联网上掀起讨论飓风的柏拉图表示假说提出:所有足够大规模的图像模型都具有相同的潜在表示。

5 月 23 日,Plaud AI 创始人许高与《时代》杂志特约编辑 Charlie Campbell 在 Beyond Expo 展开了深度交流 —— 围绕“语音交互与人类智慧传递”、“生成式 AI 在工作流中的价值”、“个性化模型的演进”以及“AI 安全与地缘政治挑战”等多个维度展开探讨,还分享了 Plaud AI 在消费级 AI 硬件与人机协同方面的最新进展与长期愿景。

丹麦研究显示,生成式AI推出两年半后尚未显著改变劳动力市场,员工收入与工作时长无明显变化。尽管AI工具提升了部分工作效率(平均节省2.8%时间),但转化为薪资涨幅不足1%。工作内容出现新任务调整,但未减少原有职责,且多数企业将节省时间转化为其他工作量。

刚刚发布的Claude 4被发现,它可能会自主判断用户行为,如果用户做的事情极其邪恶,且模型有对工具的访问权限,它可能就要通过邮件联系相关部门,把你锁出系统。这事儿,Anthropic团队负责模型对齐工作的一位老哥亲口说的。

刚刚,全球规模最大的单细胞基础大模型来了,而且是纯国产!近日,中山大学杨跃东教授团队联合重庆大学、华为、新格元生物科技,研发单细胞基础大模型CellFM,成果发表在Nature Communications上。
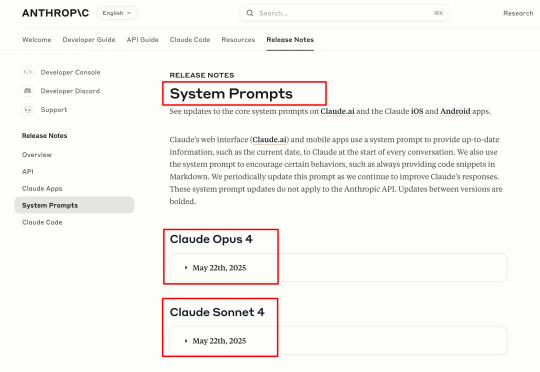
时隔 3 个月,Anthropic 上新了 Claude 4 模型。并同步了 Claude 4 Opus 和 Sonnet 两个模型的最新系统提示词。(Opus 是旗舰版、Sonnet 是主力版)经过对照,Claude 4 Opus 与 Sonnet 版本的系统提示词,基本没有区别,所以只需要看 Opus 的提示词即可:

英伟达,亲手打破了自己的天花板!刚刚,Blackwell单用户每秒突破了1000个token,在Llama 4 Maverick模型上,再次创下了AI推理的世界纪录。在官博中,团队放出了不少绝密武器。

上月,ChatGPT-4o无条件跪舔用户,被OpenAI紧急修复。然而,ICLR 2025的文章揭示LLM不止会「跪舔」,还有另外5种「套路」。
咱就是说啊,视觉基础模型这块儿,国产AI真就是上了个大分——Glint-MVT,来自格灵深瞳的最新成果。Glint-MVT,来自格灵深瞳的最新成果先来看下成绩——线性探测(LinearProbing):

来自香港科技大学、腾讯西雅图AI Lab、爱丁堡大学、Miniml.AI、英伟达的研究者联合提出了MMLongBench,旨在全面评估多模态模型的长文本理解能力。