# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI生成的人物和场景转头就变样,缺乏一致性?
nonono,这回不一样了,康康下面的demo!
游戏地图:《塞尔达传说》中的绿色田野

建筑:《黑神话悟空》里的废弃寺庙

角色模型:《原神》里的云堇

无论镜头怎么晃,场景里的元素都乖乖不动,一致性满分。
这一惊艳效果就来自香港大学和快手可灵的研究团队提出的全新框架——“上下文即记忆”(Context-as-Memory)。

该方法直接将完整的历史上下文帧(context frames)作为记忆,并通过记忆检索高效利用相关历史帧,极大地优化了交互式长视频生成中的场景一致性。
他们是怎么做的?快来一起看看吧。
在聊新方法之前,咱们先来简单梳理一下视频生成里的两类“记忆”类型:
一类是处理短期运动和行为模式的动态记忆,例如视频中的角色动画、车辆轨迹、粒子效果以及天气变化等。
另一类就是这篇论文针对的静态记忆,包括场景级和物体级的记忆,例如游戏地图、建筑、角色模型和物体外观。
明确了动态与静态记忆的区别后,我们就可以更清晰地理解本论文提出的核心思路:Context-as-Memory。
总体来看,Context-as-Memory的核心思想有以下三点:
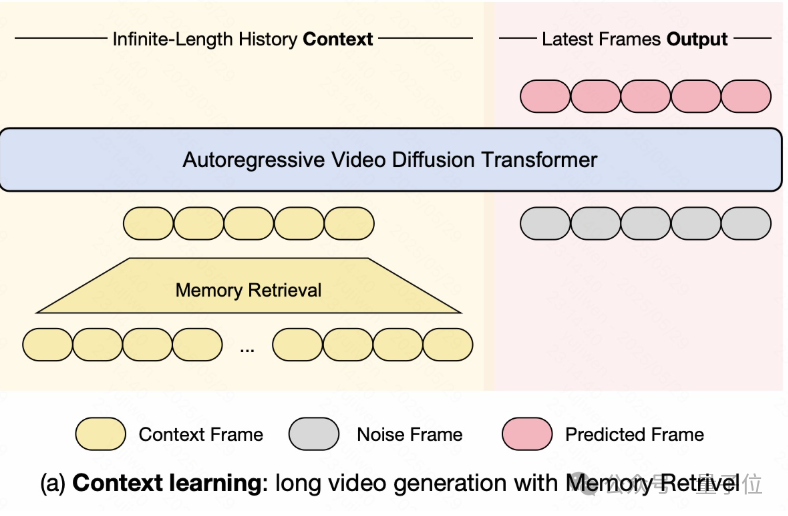
具体来说,模型从一个无限长度的历史上下文中开始,利用一个“记忆检索”模块从中筛选出那些真正有用的、与当前生成最相关的上下文帧。
这些被筛选出的上下文帧随后与带噪声的待预测帧拼接在一起,作为核心的“自回归视频扩散Transformer”的输入。
模型处理这个拼接后的输入,利用历史记忆作为条件来指导去噪过程,最终生成一系列最新的预测帧。
通过这种方式,Context-as-Memory避免了直接处理全部历史上下文的巨大计算开销,同时也避免了仅依赖短期上下文导致场景不一致的问题,从而实现了高效且具有场景连贯性的长视频生成。
那么,模型是如何进行帧选取,从而进行记忆检索的呢?
在这里,研究提出了一个不同于随机、就近选取与压缩的方法——基于摄像机轨迹搜索。

这一方法通过已知的摄像机轨迹,选择与当前生成帧可视区域高度重叠的上下文帧。 通过计算过去帧和未来帧之间的视场重叠,并仅选择重叠度较高的帧作为上下文,从而能在保证计算效率的同时,也保持一致性。
此外,为了获取包含摄像机位姿标注的视频数据,团队还利用Unreal Engine 5制作了一个包含长时序视频、摄像机位姿和字幕标注的数据集。
这一数据集包含100个视频,共涵盖12种不同风格的场景。每个视频由7601帧组成,并且每隔77帧就由一个多模态大模型生成对应的字幕。
值得注意的是,正如我们在开头的demo中所见,摄像机的运动仅表现为左右摇镜。这一设计是为了简化位姿处理,将摄像机的控制限制在二维平面上,包括xy方向上移动以及z轴上的旋转。
为了评估Context-as-Memory方法,研究团队在相同的基础模型、数据集和训练配置下将其与下列视频生成方法进行了对比。
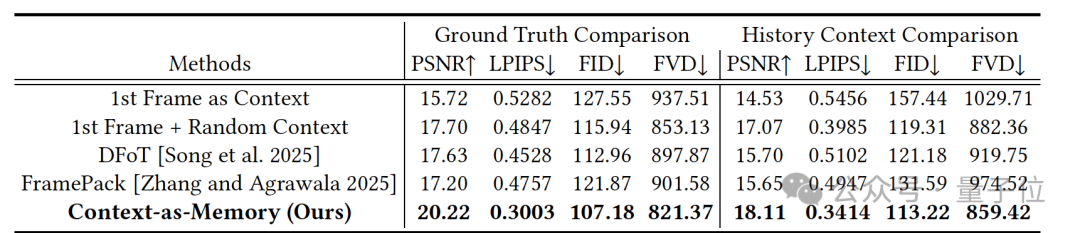
实验结果表明,Context-as-Memory方法在记忆能力和生成质量上都显著优于基线和SOTA方法,这表明它能够有效利用历史上下文,避免冗余和历史信息丢失,从而保持长视频生成的一致性。
最后,为了测试方法的泛化性,团队还从互联网选取了不同风格的图像作为首帧来生成长视频,并采用“旋转远离再旋转返回”(左右摇镜)的轨迹进行验证。

研究结果表明,在开放域场景中,Context-as-Memory也展现出了强大的记忆能力。
这篇论文由香港大学、浙江大学和快手可灵团队联合完成,这篇论文的第一作者余济闻,是香港大学的在读博士生,师从刘希慧教授。目前,他在快手可灵团队担任研究实习生,接受王鑫涛博士的指导。
在此之前,他曾在北京大学获得硕士学位,师从张健教授。
值得一提的是,这篇关于“上下文记忆”的工作,是他在交互式视频生成、世界模型和具身人工智能方向上的延续。
他此前在视频生成与世界模型方向的研究成果GameFactory: Creating New Games with Generative Interactive Videos,曾入选ICCV 2025Highlight。
参考链接
[1]https://x.com/yujiwenHK/status/1957663719347089613
[2]https://arxiv.org/pdf/2506.03141
[3]A Survey of Interactive Generative Video. https://arxiv.org/pdf/2504.21853
[4]Position: Interactive Generative Video as Next-Generation Game Engine. https://arxiv.org/pdf/2503.17359
文章来自于微信公众号“量子位”,作者是“henry”。



