
为什么 Qwen3,让我看到了 AI 应用落地的重大利好
为什么 Qwen3,让我看到了 AI 应用落地的重大利好各位有没有发现,最近大家对大模型已经有些看麻了?反正我是看到相关话题的文章流量、社交平台上的热度,对模型的关注度明显有点降下来了。 比如最近 Qwen3、Gemini2.5、GPT-4.1 和 Grok-3 等这么密集的有明显新进展的优秀模型发布,要是放到 2 年前,铁定是个炸裂的一个月。
来自主题: AI资讯
8162 点击 2025-05-20 16:26
 搜索
搜索
各位有没有发现,最近大家对大模型已经有些看麻了?反正我是看到相关话题的文章流量、社交平台上的热度,对模型的关注度明显有点降下来了。 比如最近 Qwen3、Gemini2.5、GPT-4.1 和 Grok-3 等这么密集的有明显新进展的优秀模型发布,要是放到 2 年前,铁定是个炸裂的一个月。
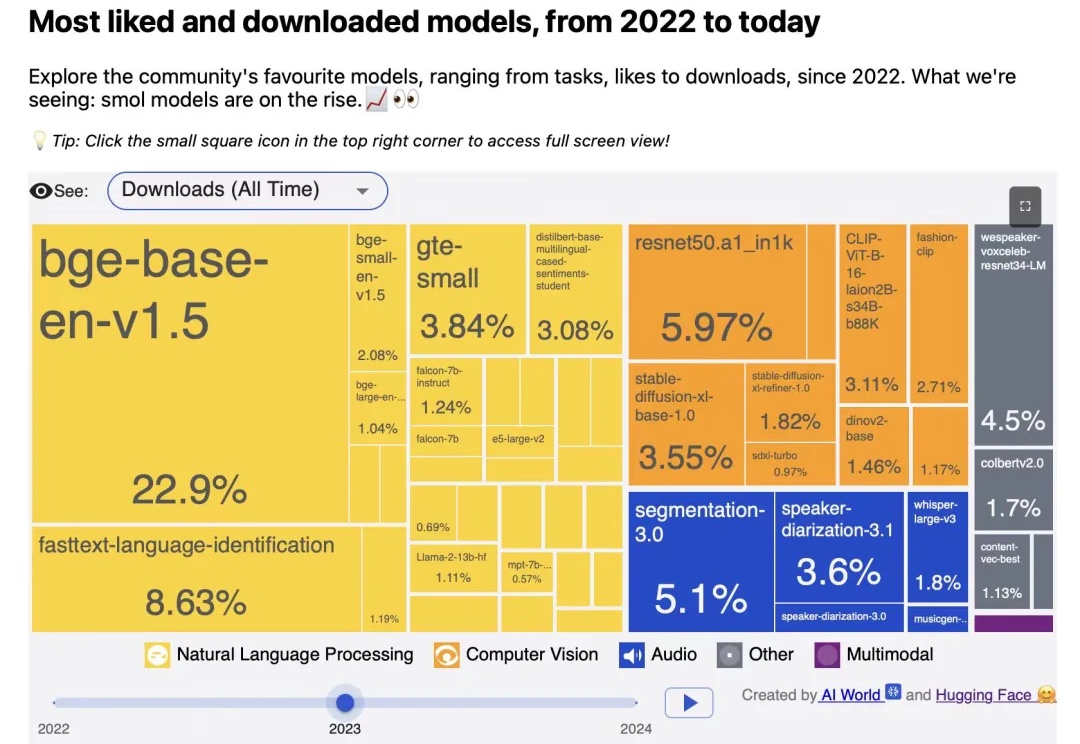
检索增强技术在代码及多模态场景中的发挥着重要作用,而向量模型是检索增强体系中的重要组成部分。

在基本物理任务上,前沿AI模型仍会失败!ML研究院的测试案例显示白领将被Ai替代,而制造业等蓝领工作不受影响。未来已来,只是分布得不均匀。

要问最近哪个模型最火,混合专家模型(MoE,Mixture of Experts)绝对是榜上提名的那一个。
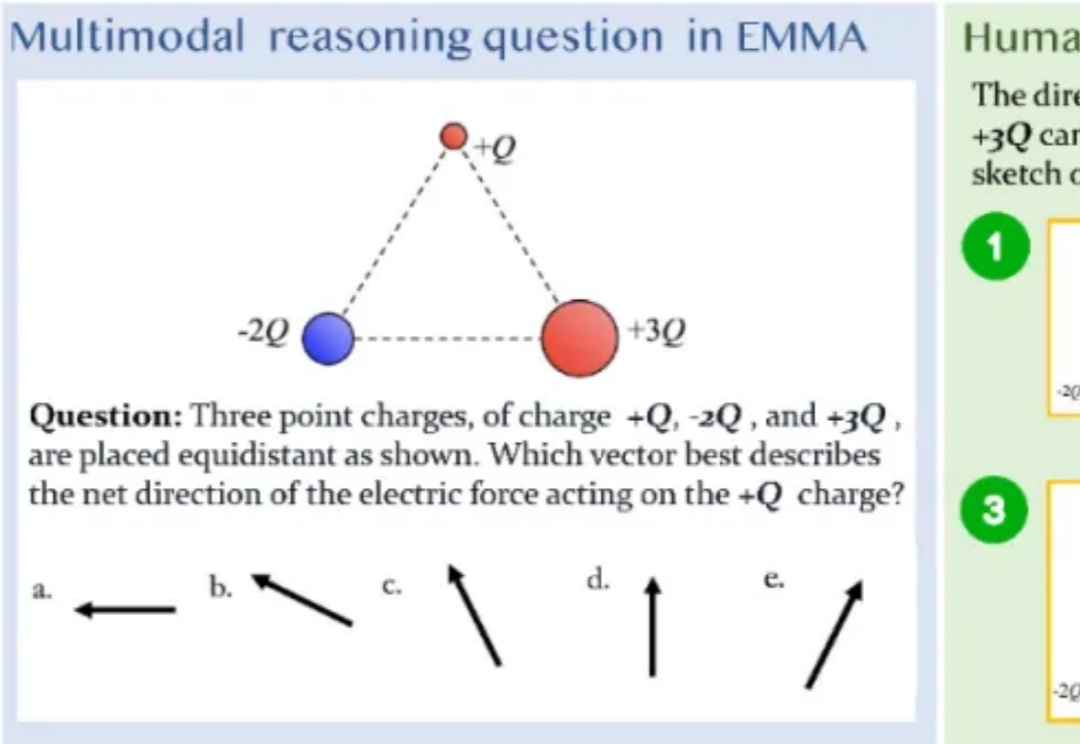
「三个点电荷 + Q、-2Q 和 + 3Q 等距放置,哪个向量最能描述作用在 + Q 电荷上的净电力方向?」
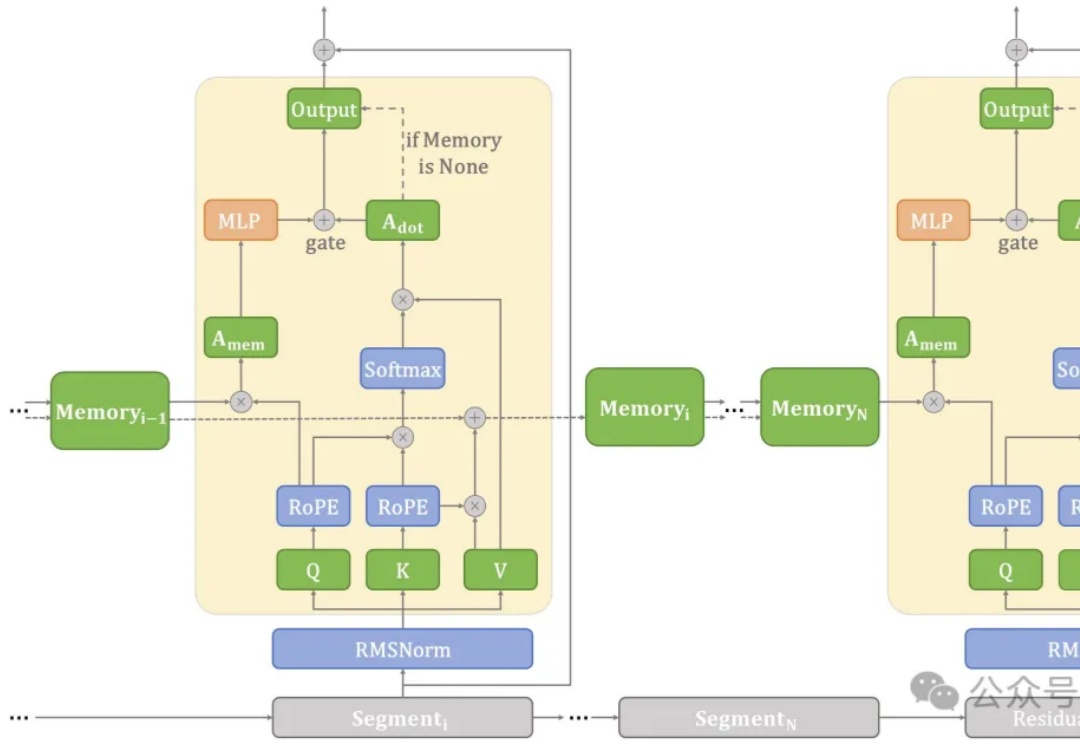
在端侧设备上处理长文本常常面临计算和内存瓶颈。
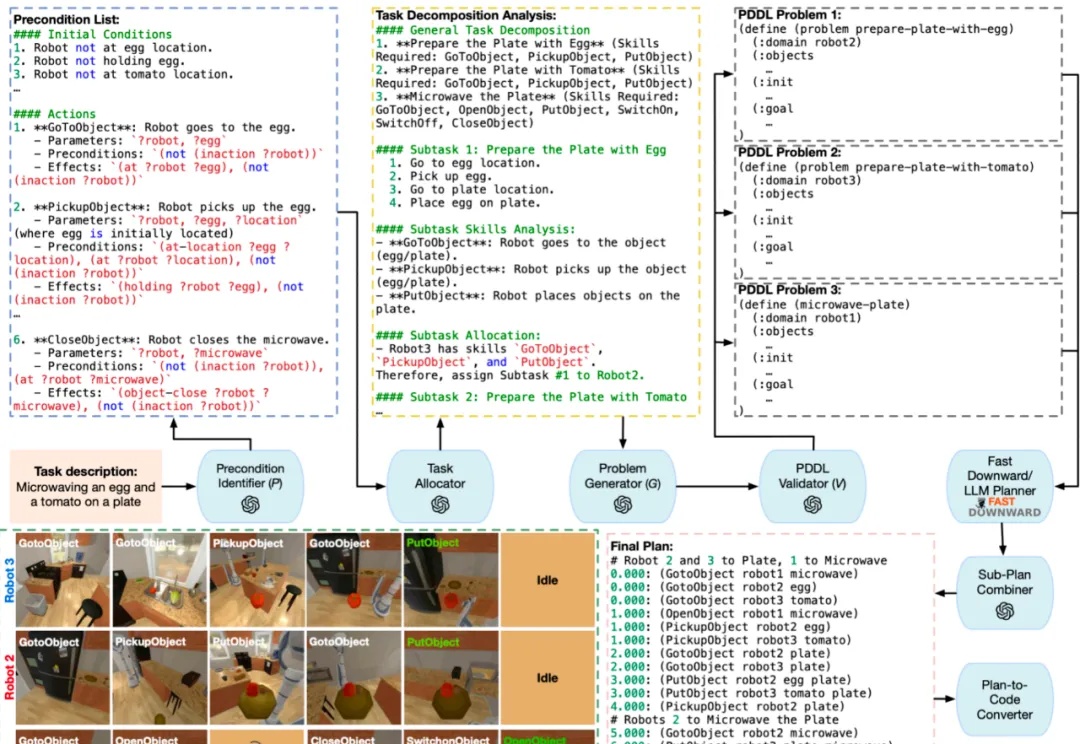
2025 年 5 月,美国加州大学河滨分校 (UC Riverside) 与宾夕法尼亚州立大学 (Penn State University) 联合团队在机器人领域顶级会议 ICRA 2025 上发布最新研究成果 LaMMA-P。

就在刚刚,智源研究员联合多所高校开放三款向量模型,以大优势登顶多项测试基准。其中,BGE-Code-v1直接击穿代码检索天花板,百万行级代码库再也不用怕了!
微软Build 2025全面转向AI Agent,整合OpenAI及xAI模型

拷打AI的难度还在升级?这不,图像推理又出现了新难题。