
DeepSeek们越来越聪明,却也越来越不听话了。
DeepSeek们越来越聪明,却也越来越不听话了。在今年,DeepSeek R1火了之后。
来自主题: AI资讯
7056 点击 2025-05-20 10:44
 搜索
搜索
在今年,DeepSeek R1火了之后。
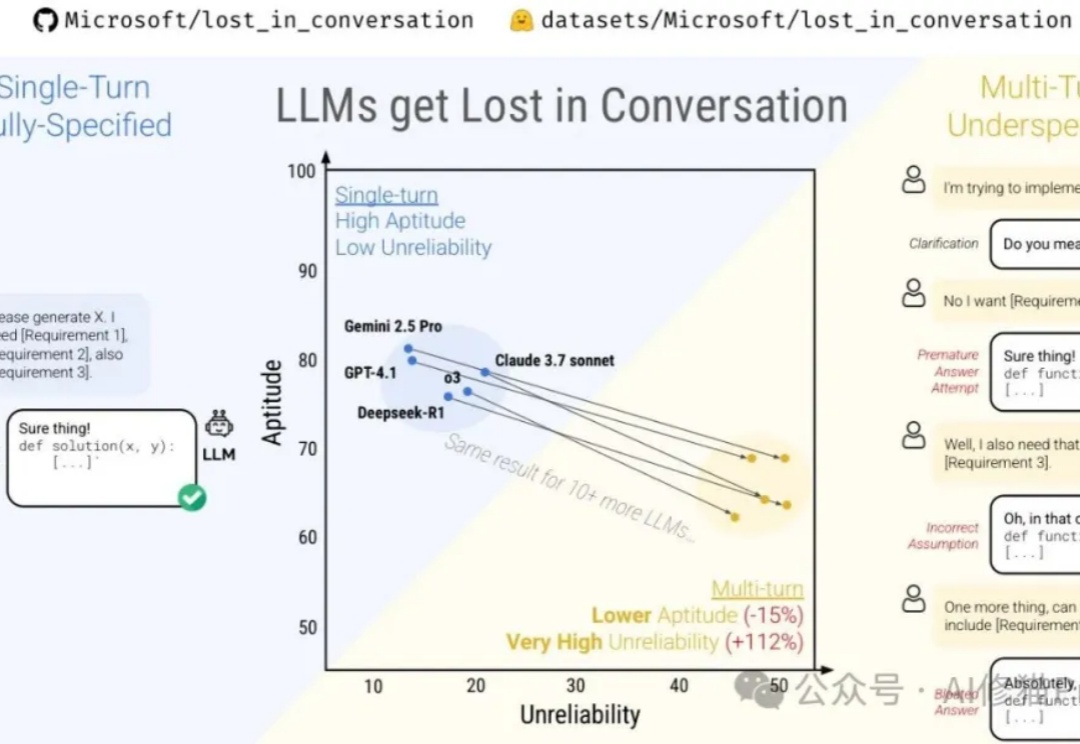
微软最近与Salesforce Research联合发布了一篇名为《Lost in Conversation》的研究,说当前最先进的LLM在多轮对话中表现会大幅下降,平均降幅高达39%。这一现象被称为对话中的"迷失"。文章分析了各大模型(包括Claude 3.7-Sonnet、Deepseek-R1等)在多轮对话中的表现差异,还解析了模型"迷失"的根本原因及有效缓解策略。
MCP 是一种开放的技术协议,旨在标准化大型语言模型(LLM)与外部工具和服务的交互方式。你可以把 MCP 理解成像是一个 AI 世界的通用翻译官,让 AI 模型能够与各种各样的外部工具"对话"。
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
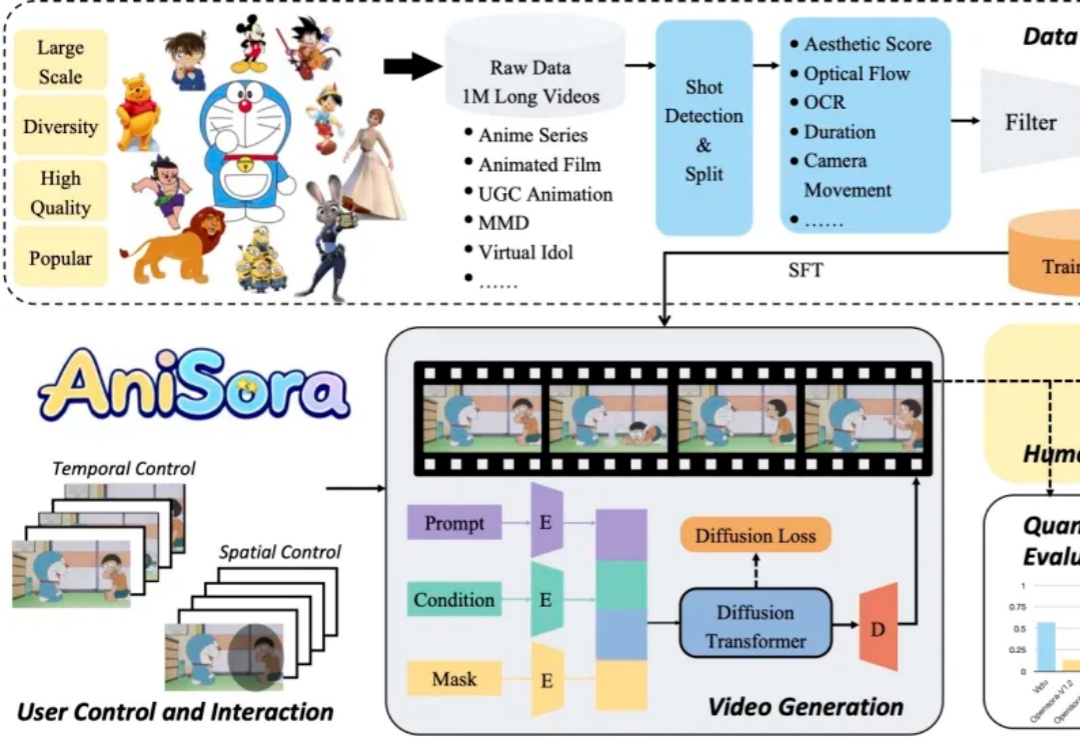
B 站开源动画视频生成模型 Index-AniSora,支持番剧、国创、漫改动画、VTuber、动画 PV、鬼畜动画等多种二次元风格视频镜头一键生成!

部署超大规模MoE这件事,国产芯片的推理性能,已经再创新高了—— 不仅是“英伟达含量为0”这么简单,更是性能全面超越英伟达Hopper架构!

AI能写论文、画图、考高分,但连「看表读时间」「今天是星期几」都错得离谱?最新研究揭示了背后惊人的认知缺陷,提醒我们:AI很强大,但精确推理还离不开人类。
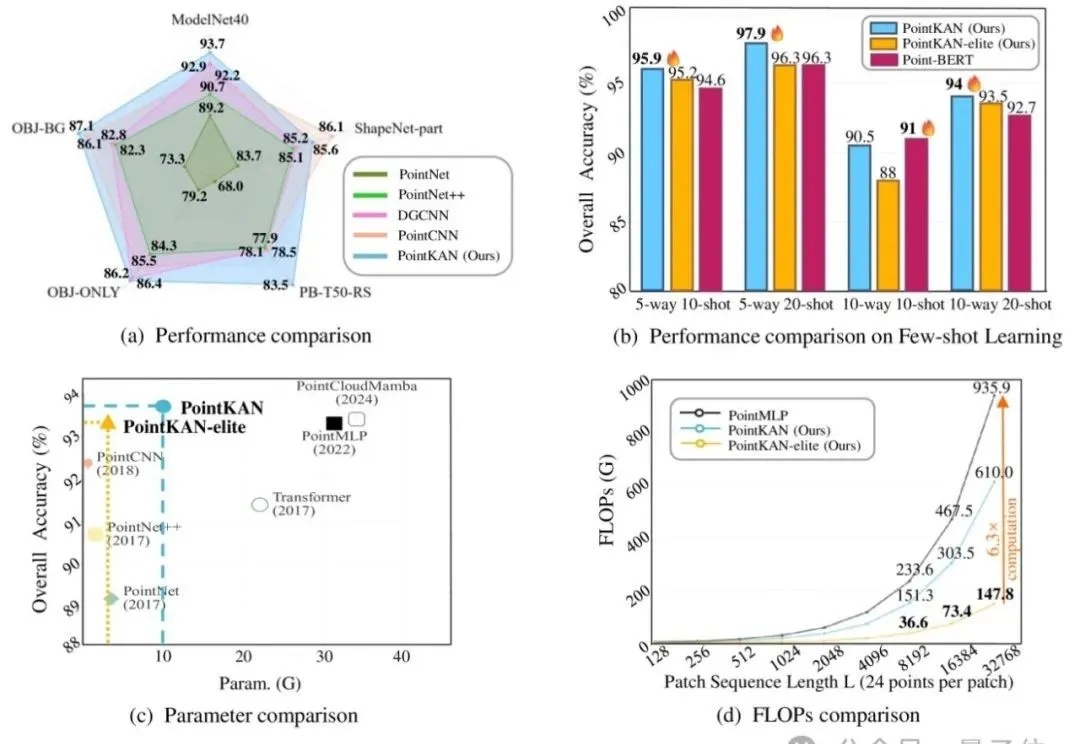
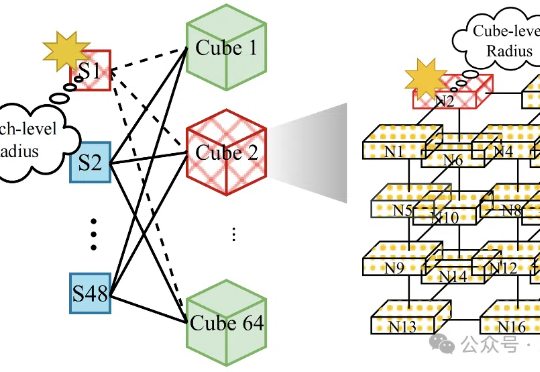
新架构选择用KAN做3D感知,点云分析有了新SOTA!
随着大模型的参数规模不断扩大,分布式训练已成为人工智能发展的中心技术路径。

本文由匹兹堡大学智能系统实验室(Intelligent Systems Laboratory)的研究团队完成。第一作者为匹兹堡大学的一年级博士生薛琪耀。