
翁荔最新万字长文:Why We Think
翁荔最新万字长文:Why We Think《Why We Think》。 这就是北大校友、前OpenAI华人VP翁荔所发布的最新万字长文—— 围绕“测试时计算”(Test-time Compute)和“思维链”(Chain-of-Thought,CoT),讨论了如何通过这些技术显著提升模型性能。
来自主题: AI资讯
9485 点击 2025-05-19 13:15
 搜索
搜索
《Why We Think》。 这就是北大校友、前OpenAI华人VP翁荔所发布的最新万字长文—— 围绕“测试时计算”(Test-time Compute)和“思维链”(Chain-of-Thought,CoT),讨论了如何通过这些技术显著提升模型性能。

硅谷终极野心:AI+机器人吞噬全球六十万亿美元工资;马斯克、盖茨、Hinton等科技大佬同声预言,白领到蓝领都将被算法与机械手臂取代。这场变革的背后,是提高生活水平的美好愿景,还是少数人掌控生产资料的逐利游戏?
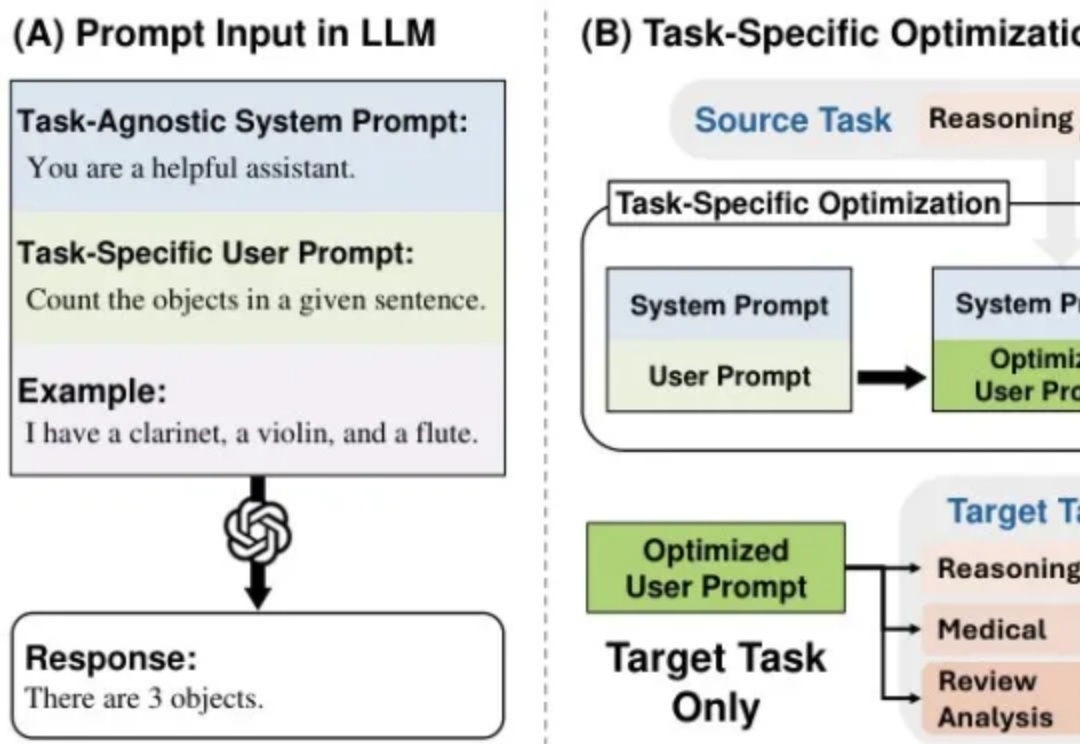
每次更换语言模型就要重新优化提示词?资源浪费且效率低下!本文介绍MetaSPO框架,首个专注模型迁移系统提示优化的元学习方法,让一次优化的提示可跨模型通用。我在儿童教育场景的实验验证了效果:框架自动生成了五种不同教育范式的系统提示,最优的"苏格拉底式"提示成功由DeepSeek-V3迁移到通义千问模型,评分从0.3920提升至0.4362。
,即使是最强大的大语言模型也有"健忘症"!但现在,Supermemory提出的创新解决方案横空出世,声称只需一行代码,就能让任何AI拥有"无限记忆"能力。这到底是怎么回事?今天我们就来一探究竟!
学习大模型的优质博客又更新了!

近年来,生成式人工智能的快速发展,在文本和图像生成领域都取得了很大的成功。

你以为GPT-4已经够强了?那只是AI的「预热阶段」。真正的革命,才刚刚开始——推理模型的时代,来了。这场范式革命,正深刻影响企业命运和个人前途。这不是一场模型参数的升级,而是一次认知逻辑的彻底重写。

我们发现,当模型在测试阶段花更多时间思考时,其推理表现会显著提升,这打破了业界普遍依赖预训练算力的传统认知。
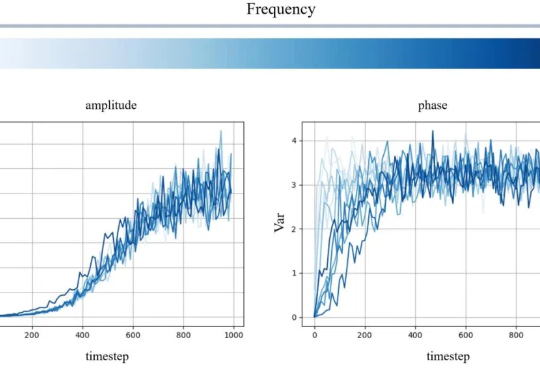
本文作者分别来自中国科学院大学和中国科学院计算技术研究所。第一作者裴高政为中国科学院大学博士二年级学生,本工作共同通讯作者是中国科学院大学马坷副教授和黄庆明教授。
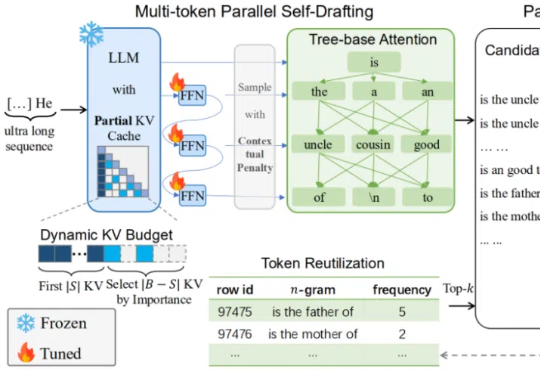
在当前大模型推理愈发复杂的时代,如何快速、高效地产生超长文本,成为了模型部署与优化中的一大核心挑战。