# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI能像人类一样理解长视频。
港理工、新加坡国立团队推出VideoMind框架,核心创新在于角色化推理(Role-based Reasoning)和链式LoRA(Chain-of-LoRA)策略。
相关论文已上传arXiv,代码和数据全部开源。

随着视频数据量的激增,如何理解和推理长视频中的复杂场景和事件成为了多模态人工智能研究的热点。不同于静态图像,视频不仅包含视觉信息,还包含时间维度上的动态变化,这要求模型在理解视频时不仅要识别画面中的物体和场景,还要理解这些物体和场景如何随时间变化和相互作用。
传统的基于文本和图像的推理模型(如OpenAI o1, DeepSeek R1等)往往无法应对这种复杂的时间维度推理任务。
区别于文本和图片,长视频理解难以用传统的单次感知 + 纯文字推理实现。
相比之下,人类在理解长视频(如教学视频、故事类视频)时往往会寻找相关片段并反复观看,以此获取更可靠的结论。
受该现象启发,作者根据视频理解所需要的4种核心能力(制定计划、搜索片段、验证片段、回答问题),为VideoMind定义了4个角色,并构建了一个角色化的工作流,有效地解决了长视频中的时序推理问题。
根据问题动态制定计划,决定如何调用其他角色(如先定位,再验证,最后回答问题);
根据给定的问题或查询,精确定位与之相关的视频片段;
对定位得到的多个时间片段进行验证,确保其准确性;
基于选定的视频片段进行理解,生成最终答案。
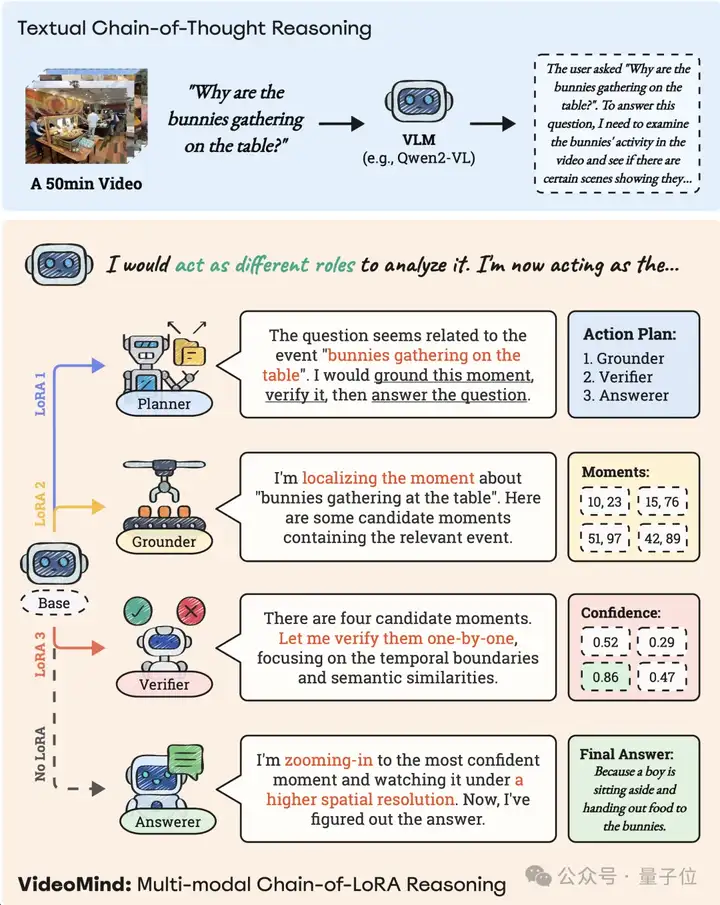
△图1:传统纯文字推理和VideoMind的角色化推理
为了高效整合以上角色,作者进一步提出了链式LoRA(Chain-of-LoRA)策略,在一个统一的Base模型(如Qwen2-VL)上同时加载多个轻量的LoRA Adapter,并在推理时根据需要进行动态切换,以实现不同角色间的转换。该策略仅需要在Base模型上添加少量可学习参数,即可实现多个角色/功能间的无缝切换,既获得了比单一模型显著更优的性能,也避免了多模型并行带来的计算开销,从而在确保性能的同时大幅提高了计算效率。
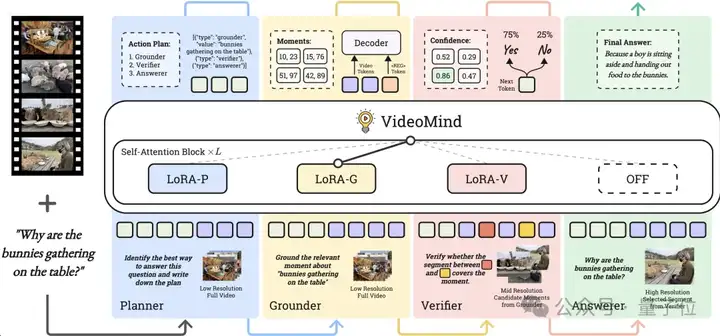
△图2: VideoMind的整体架构和推理流程
如图2所示,模型接收一个视频和一个用户提出的问题作为输入,通过切换多个角色来推理出最终答案。其中,Planner首先对视频和问题进行分析,执行后续推理的计划,其结果以JSON list的形式呈现。推理计划主要可分为以下三种:

△图3:VideoMind的三种推理模式
其中(i)主要针对长视频问答任务(Grounded VideoQA),需要使用Grounder + Verifier + Answerer三个角色进行作业;(ii)针对视频时序定位任务(Video Temporal Grounding),使用Grounder + Verifier来进行相关片段的精准查找;(iii)针对短视频问答,该场景下由于视频较短,无需对其进行裁剪,故直接使用Answerer进行推理。
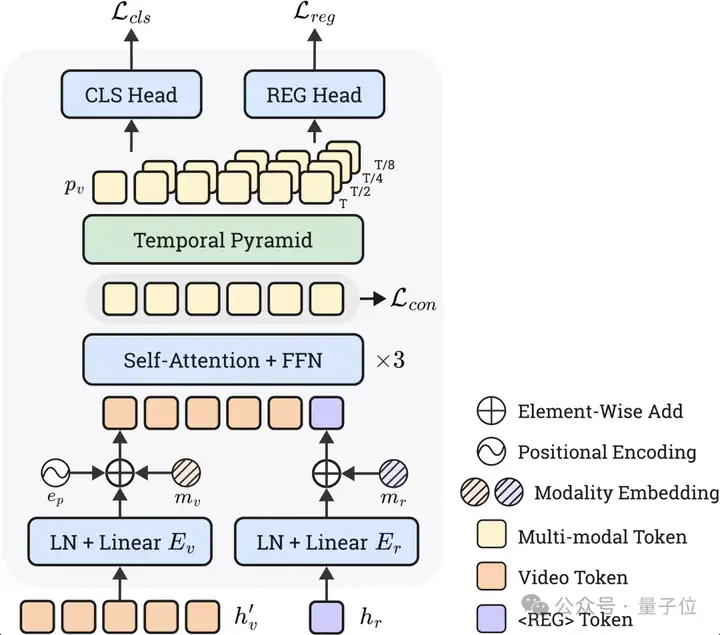
△图4:Timestamp Decoder模块
Grounder负责接收一个自然语言查询,并在视频中定位相关片段。针对这一复杂任务,研究团队提出了Timestamp Decoder模块,将离散的Token预测任务和连续的时间回归任务解耦开来,并使LLM通过Special Token进行调用,实现了强大的Zero-shot时序定位性能。
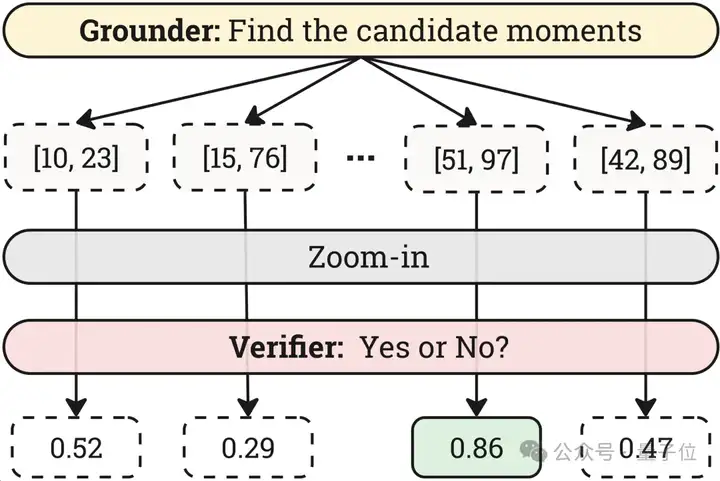
△图5:Verifier的验证策略
为保证时间分辨率,Grounder往往工作在较低的空间分辨率下,因此获得的时间片段可能会不准确。针对此问题,作者设计了Verifier角色来对每个片段进行放大验证,并从多个候选片段中选取置信度最高的作为目标片段。试验证明该策略可以进一步显著提高Temporal Grounding任务的性能。
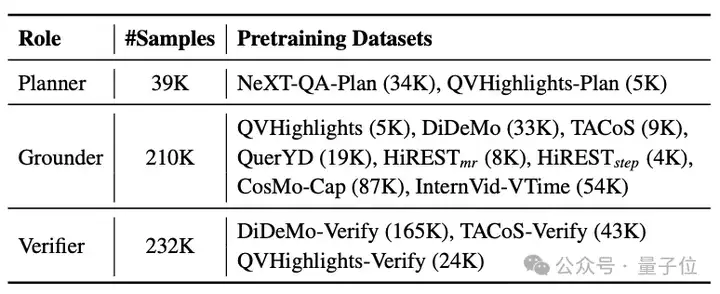
△表1:VideoMind的训练数据集
为训练VideoMind,作者针对不同角色收集/制作了多个数据集,共计包含接近50万个样本。不同角色使用不同数据集进行训练,并在推理时合并加载,以确保每个角色的性能最大化。所有训练数据(包括前期探索使用的更多数据集)全部公开可用。
为了验证VideoMind的有效性,作者在14个公开基准测试集上进行了广泛的实验,涵盖了长视频定位 + 问答(Grounded VideoQA)、视频时序定位(Video Temporal Grounding)和普通视频问答(General VideoQA)等任务。
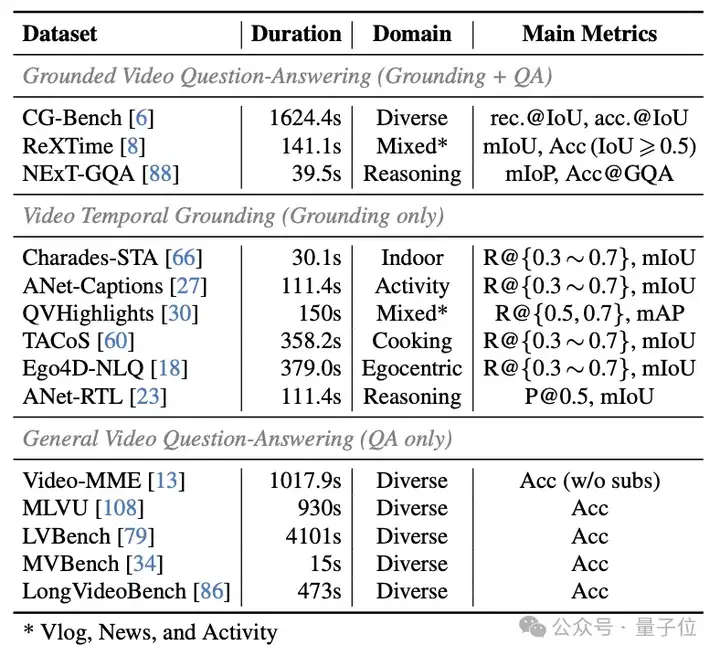
△表2:用于VideoMind评测的基准测试集
(1)视频定位 + 问答(Grounded VideoQA)
在CG-Bench、ReXTime、NExT-GQA等长视频基准上,VideoMind在答案精确度和时序定位准确性方面表现出了领先优势。特别的,在平均视频长度约为27分钟的CG-Bench中,较小的VideoMind-2B模型在时序定位和问答任务上超越了GPT-4o、Gemini-1.5-Pro等最先进的模型。
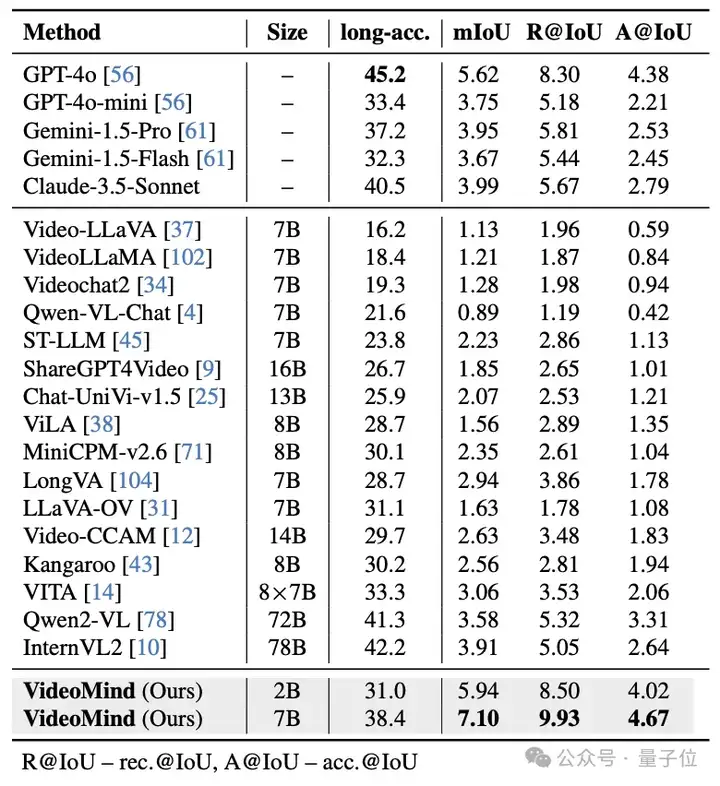
△表3:CG-Bench数据集的测试结果
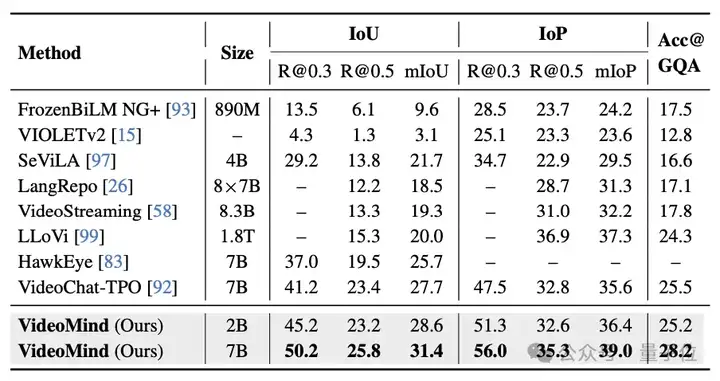
△表4:NExT-GQA数据集的测试结果
(2)视频时序定位(Video Temporal Grounding)
VideoMind的Grounder通过创新的Timestamp Decoder和Temporal Feature Pyramid设计,显著提高了视频时序定位的准确性。Verifier的设计进一步提升了高精度定位的性能。VideoMind在Charades-STA、ActivityNet-Captions、QVHighlights等基准上都取得了最佳性能。此外,VideoMind也是首个支持多片段grounding的多模态大模型,因此可以在QVHighlights数据集上跟现有模型公平对比。
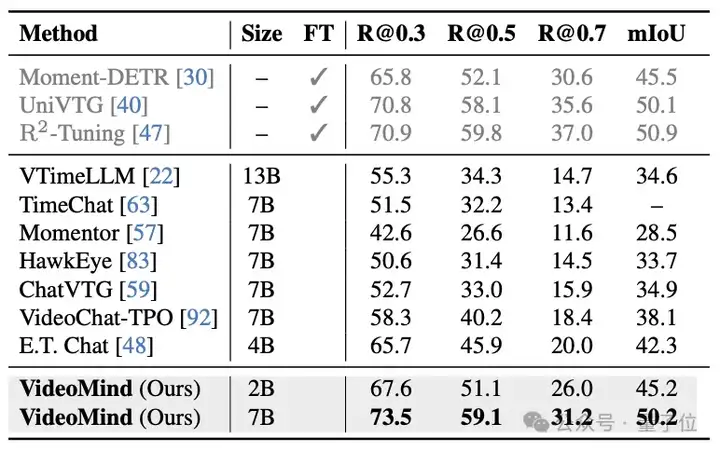
△表5:Charades-STA数据集的测试结果
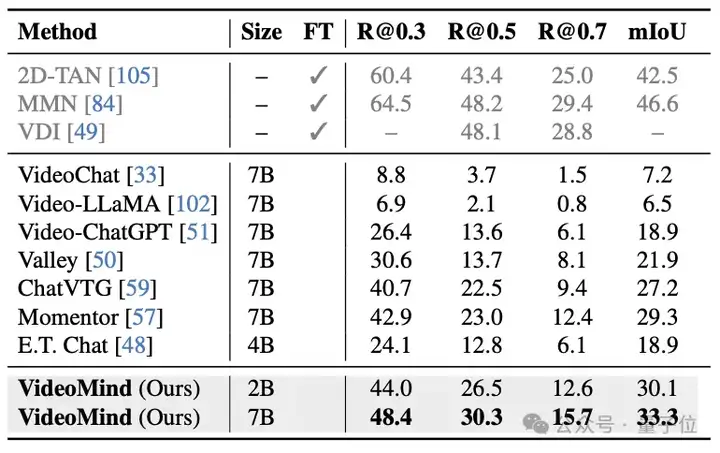
△表6:ActivityNet Captions数据集的测试结果
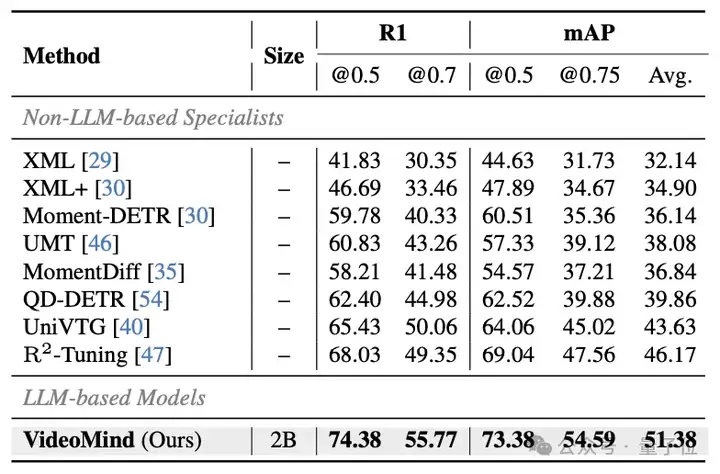
△表7:QVHighlights数据集的测试结果
(3)一般视频问答(General VideoQA)
对于通用的视频理解问题,VideoMind也表现出了强大的泛化能力。在Video-MME、MVBench、MLVU、LVBench、LongVideoBench等基准上,VideoMind得益于其Planner的设计,可以自适应地决定是否需要grounding,其性能超越了许多先进的视频问答模型,显示了其在不同视频长度下的优越表现。
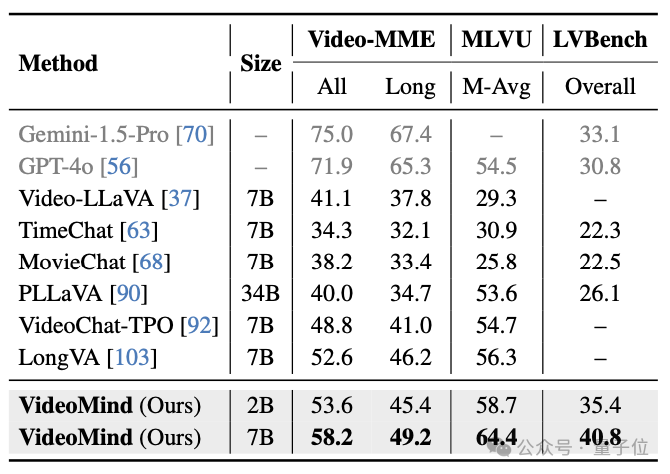
△表8:Video-MME、MLVU和LVBench数据集的测试结果
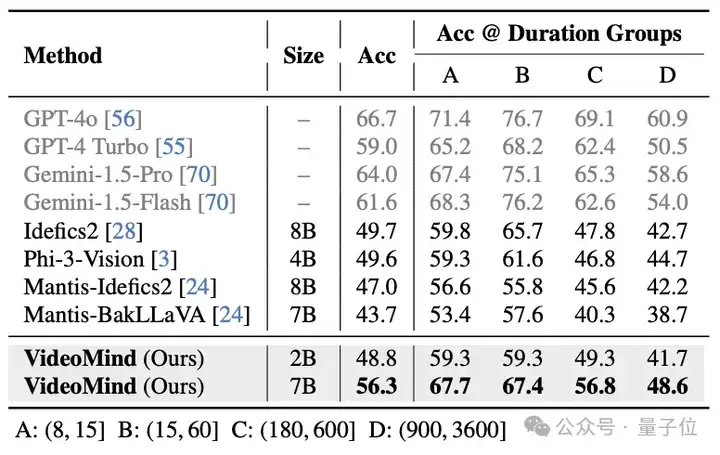
△表9:LongVideoBench数据集的测试结果
以下例子展现了VideoMind在实际场景中的推理流程。给定一个视频和一个问题,该模型可以拆解问题、指定计划、搜索片段、验证结果,并根据获取的片段推理最终答案。该策略相比传统的纯文字推理(左下部分)更加符合人类行为,结果也更加可靠。
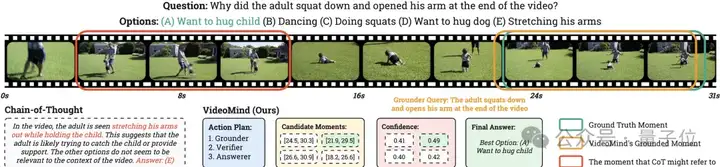
△图6:VideoMind的推理流程可视化
VideoMind的提出不仅在于视频理解性能的突破,更在于提出了一个模块化、可扩展、可解释的多模态推理框架。该框架首次实现了类似人类行为的“指定计划、搜索片段、验证结果、回答问题”流程,真正让AI能“像人类一样理解视频”,为未来的视频理解和多模态智能系统领域奠定了基础。
项目主页:https://videomind.github.io/
论文链接:https://arxiv.org/abs/2503.13444
开源代码:https://github.com/yeliudev/VideoMind
开源数据:https://huggingface.co/datasets/yeliudev/VideoMind-Dataset
在线Demo:https://huggingface.co/spaces/yeliudev/VideoMind-2B
文章来自于“量子位”,作者“VideoMind团队”。




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
