# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大家好,我是小瑶,今天是你们的 AI 前排吃瓜 + 技术解读博主。
昨天人在百度科技园,参加了百度 AI DAY 活动,不仅吃到了「文小言」的一手大瓜,还非常荣幸的采访到了语音技术大牛——百度语音首席架构师贾磊老师!
在现场时,我感觉脑子 CPU 都要干烧了,给你们看一张现场 PPT——

技术大牛贾磊老师,现场硬核拆解语音大模型,更重要的是,拆的是这次文小言全新升级的语音语言大模型背后的核心技术。
这让我的技术基因止不住的躁动起来了,瞬间有一种参加 ICASSP 语音学术顶会的错觉。
先带你们一手感受下文小言最新的实时语音通话——
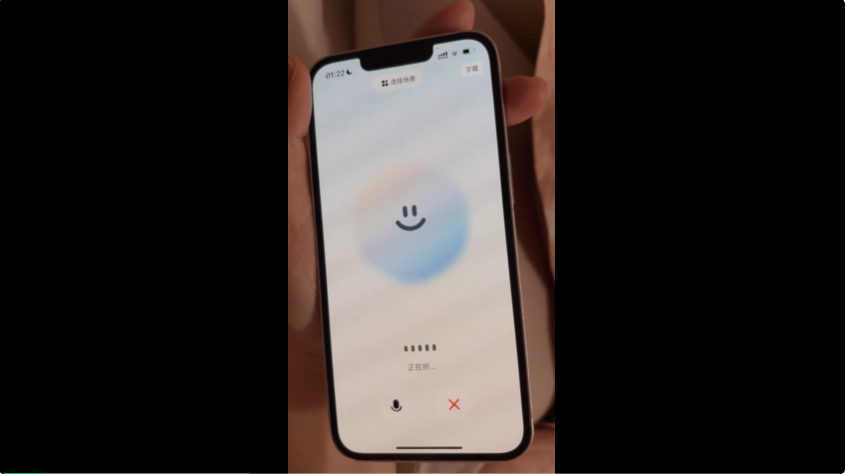
从测试一开始,我就在无情的、疯狂的打断文小言的讲话,我试图让整个对话变得支离破碎,但在这个情况下,文小言都能在我插嘴 1 秒左右反应过来,流畅转变,聪明如人。不过,这要换成真人,被我这样打断,对方早就炸毛了。
要知道,市面上的语音通话产品,普遍 3~5 秒的反应延迟,文小言这反应速度 + 对话的顺畅程度,真的爽到我了。
而且实测下来,我发现更新后的文小言不止实时打断 + 反应速度非常牛逼,其在情感、方言、记忆、知识方面也都可圈可点。
但,今天这篇文章,我不准备写产品评测,大家可以升级「文小言 APP」到最新版后自行感受。
因为,这次百度 AI DAY 上,贾磊老师公开并深入拆解了这个惊艳的语音大模型背后的技术实现,这对于推动业界的语音技术进步,有非常重要的参考意义。
语音对话这个赛道,与文本对话相比有根本性的不同。
在文本对话的场景,用户对于等待回复的容忍度比较高。但,你跟一个人说话的时候,如果对方总是先卡顿个 3、5 秒才说话,你肯定心里不愿意再说了。
还有人类看东西,往往一目十行,但听东西,是一个字一个字的接收。
所以,看一家厂商的语音对话技术牛不牛,第一个要关注的指标,就是看对方多快吐出第一个字。
业界普遍能做到的水平是 3~5 秒,而能做到 1 秒左右的,一只手就能数得过来,包括这次百度发布的全新语音大模型。

对于语音对话来说,最简单的建模方案就是——
这种工程化的模块级联方案,不仅会导致信息在传递中多级损耗,导致效果差,而且多环节积累起来的延迟、成本也会爆炸。市面上仍然有不少语音对话产品,走的是这种传统的技术方案。所以你能感受到的就是对方“又慢又笨”。
百度这里则是训出了一个端到端的语音语言大模型,把原本独立的语音识别、LLM 理解生成、语音合成给直接编码到了一个模型里——
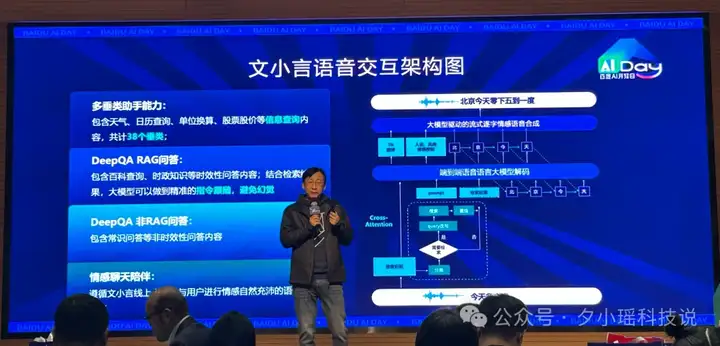
这个端到端的语音语言大模型采用了 MoE 架构,是基于成熟的文心一言预训练模型冷启,采用自蒸馏、多模数据混合的方式 post-train 训练出来的。
这里非常关键的是,百度这里竟然用了 Cross-Attention 这个我本以为已经被历史遗忘的注意力机制。
通过它,巧妙的将大模型的 Encoder 与语音识别进行融合,然后将 Decoder 与语音合成进行融合,优雅的把文本和语音两个模态,整合进了一个模型中。
这样做的好处非常直接——从接收用户语音到吐出第一个字,只需要一次模型推理,直接把第一个 token 的延迟给打了下来。
看到这个模型结构图,我突然懂了为什么这个模型叫“端到端语音语言大模型”了。
同时,从上图可以看出,这里 Cross Attention 的效率,极大的决定了延迟高低。
贾磊老师在现场提到,现有的 Attention 技术,比如 DeepSeek 中使用的MLA(Multi-Head Latent Attention),用在 Cross-Attention 的时候,容易出现不稳定的情况。
于是,百度探索出了一个成为 EALLQA(Efficient All Query Attention,高效全查询注意力)的“黑科技”,也就是专门为 Cross-Attention 场景设计的全新 Attention 机制。

这个 EALLQA,可以总结成以下几点:
EALLQA 加上 Encoder 的融合设计,直接把 Cross Attention 这个环节的计算量和缓存需求给打了下来。这对于降低延迟,尤其是让我们能在 1 秒左右听到文小言回应的第一个字,起到了决定性的作用。
可以说,EALLQA 就是百度这次为了攻克语音对话低延迟难题,专门打磨出的核心技术突破。
通过 EALLQA 技术,解决了“慢”的问题。与此同时,百度这波还巧妙的通过“流式逐字处理 +MoE 架构”来解决了实时语音对话“成本高”和“并发低”的问题,相比行业平均水平,成本能降低 50% ,甚至达到惊人的 90%。

先说一下「流式逐字处理」的机制。
我们平时听别人说话,是不是一个字一个字听进去
的?我们并不需要等对方说完一整段话,才开始理解和反应。百度这个语音大模型就模拟了这一点。它不是先生成一整句完整的文本,再去合成语音;而是一边听 + 思考,一边一个字、一个词地往外“说”。
正因为是“一个字一个字”地听和说,对于系统来说,同一时间处理一个用户的计算压力相对分散。这使得系统可以非常从容地同时服务大量用户(也就是高并发)。
而且,百度这里用了 MoE 架构,在处理语音时,可能每个用户(每个 token)只需要激活 5 亿或 10 亿参数的“专家小分队”。在高并发下,这个模型就能被极大地共享,成本自然就摊薄了。
根据百度 AI DAY 上公布的信息,这个模型可以部署在 L20 这样廉价的显卡上,并且在满足低延迟要求的同时,实现超过数百的并发处理能力。
这波操作,直接把实时语音大模型的使用门槛和成本极大的打下来了,让以前可能觉得“用不起”大模型的语音应用场景,一下子变得触手可及。
要我说,对于推动语音通话技术的普及来说,这些技术点的公开,要比发布新产品有更大的社会意义。
光快、光便宜还不够,如果声音听起来像个没有感情的机器人,那再快也是没人用的。
还记得前面我们说的那个「端到端语音语言大模型」和「流式逐字处理」吗?它们不仅解决了延迟和成本问题,也恰恰是让声音更自然的关键。
前面提过,传统的语音助手通常是“三段式”:先识别成文字 (ASR),再让大模型思考文字 (LLM),最后把文字交给语音合成模块 (TTS) 念出来。这个过程中,TTS 模块往往只知道要念什么字,但对这句话背后的情感、上下文语境可能一无所知,念出来的声音自然就容易平淡、生硬。
但百度这次,是端到端的。
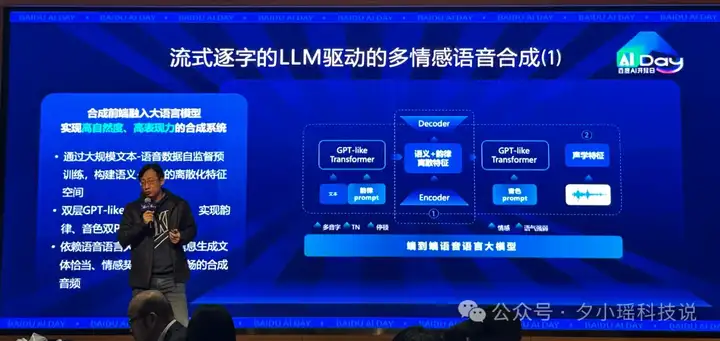
端到端 + 流式逐字之后,便可以:
更新后的文小言,给我的感觉就是,它不是在“念”答案,更像是在用带有情绪和理解的语气和你“聊”。这让整个对话体验变得亲切、舒服了许多。
一个语音模型,能同时做到超低延迟 + 超高并发 + 超低成本 + 效果提升,是一个相当难的事情,足以反映百度这个工作的含金量。
但,我想用我在专访时,被贾磊老师深深打动到的一个点,来结束本文。
我:
为何要把这个技术突破公开传播出去?
贾磊老师:
科学可能有国界,但没有公司边界。大家就应该积极去分享,推动这个学科的进步。我们拿出来,告诉你语音领域有重大突破,它有重大进展,你想想做大模型的人是不是就更关注语音领域的研究?语音领域高速发展,手机就会更智能,有利于整个行业和生态,你应该这样想这个问题,不应该将技术创新捂在手里,这不是做科研甚至技术进步的途径。
我们百度也是一直秉承开放、自由的学术理念,我们做百度 AI Day 就是把核心技术分享出去,告诉大家我们是怎么做的。就想要这个领域爆发出来,不单单百度语音人工智能发展起来,我希望腾讯、阿里、头条、华为都发展起来,整个行业都发展起来,大模型才能真正推动社会进步,做大模型的所有人才能够有好的发展,好的收益,我是这样一个理念,百度公司也跟我一样的理念。
文章来自于“夕小瑶科技说”,作者“夕小瑶编辑部”。




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
