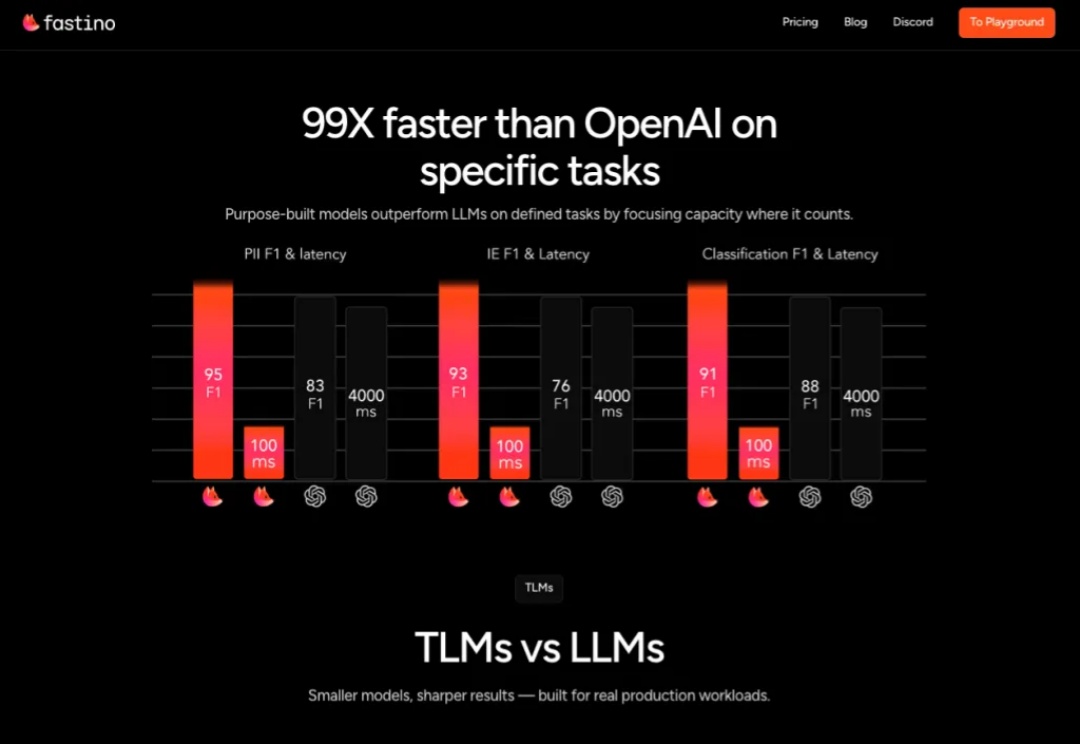
速递|OpenAI首投机构再出手!Khosla1750万美元押注“轻量化AI”Fastino,AI训练平民化
速递|OpenAI首投机构再出手!Khosla1750万美元押注“轻量化AI”Fastino,AI训练平民化科技巨头常吹嘘需要庞大昂贵GPU 集群的万亿参数 AI 模型,但 Fastino 正采取截然不同的策略
来自主题: AI资讯
11486 点击 2025-05-08 14:26
 搜索
搜索
科技巨头常吹嘘需要庞大昂贵GPU 集群的万亿参数 AI 模型,但 Fastino 正采取截然不同的策略

扩散模型(Diffusion Models)近年来在生成任务上取得了突破性的进展,不仅在图像生成、视频合成、语音合成等领域都实现了卓越表现,推动了文本到图像、视频生成的技术革新。然而,标准扩散模型的设计通常只适用于从随机噪声生成数据的任务,对于图像翻译或图像修复这类明确给定输入和输出之间映射关系的任务并不适合。

用1/8成本比肩Claude 3.7,刚刚,“欧洲OpenAI”Mistral AI发布多模态新模型。

过去一年,AI 领域在开源力量的推动下呈现爆发式增长。大模型不再是少数巨头专属的技术高地,而是在社区协作与开放共享中不断演化,覆盖基础架构、算法优化、推理部署等多个层面。开源,让 AI 更快、更平、更广,也让越来越多的开发者、研究者、创业者拥有了参与下一代智能系统构建的机会。
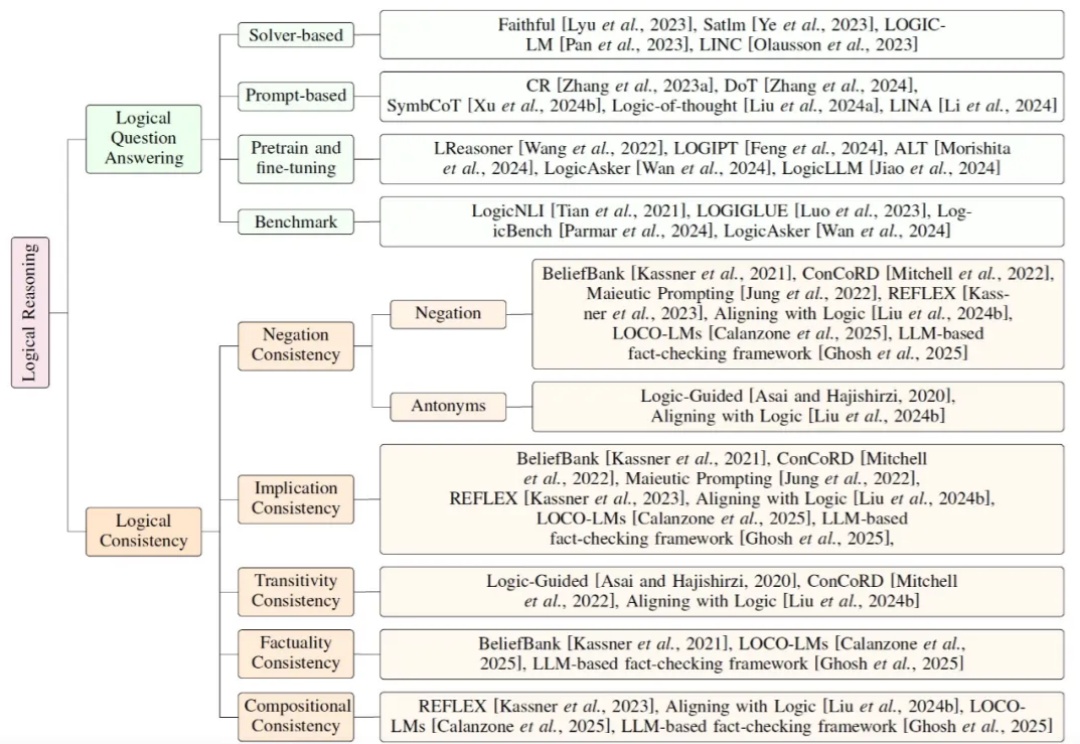
当前大模型研究正逐步从依赖扩展定律(Scaling Law)的预训练,转向聚焦推理能力的后训练。鉴于符号逻辑推理的有效性与普遍性,提升大模型的逻辑推理能力成为解决幻觉问题的关键途径。
Google也不知道受了什么刺激,最近在AI场上,好像越来越有站起来的意思了。
最强AI模型面对5560道数学难题,成功率仅16.46%?背后真相大揭秘。

大模型AI应用在消费级市场的爆发,已引发各界广泛关注。
自 OpenAI 发布 Sora 以来,AI 视频生成技术进入快速爆发阶段。凭借扩散模型强大的生成能力,我们已经可以看到接近现实的视频生成效果。但在模型逼真度不断提升的同时,速度瓶颈却成为横亘在大规模应用道路上的最大障碍。

法国初创Mistral,刚刚推出定价碾压DeepSeek V3的模型,而模型性能,却超过Claude Sonnet 3.7的90%。不过在网友们的实测中,它却翻车了?有人建议:不必下载浪费流量和硬盘空间。