7B小模型写好学术论文,新框架告别AI引用幻觉,实测100%学生认可引用质量
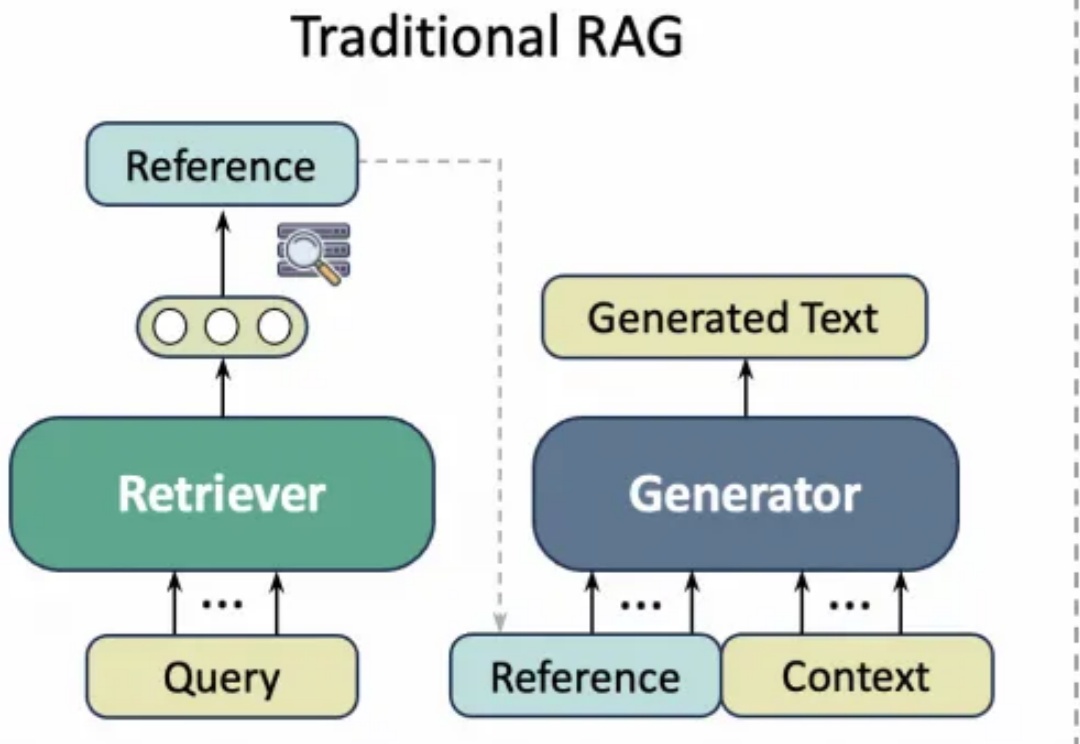
7B小模型写好学术论文,新框架告别AI引用幻觉,实测100%学生认可引用质量学术写作通常需要花费大量精力查询文献引用,而以ChatGPT、GPT-4等为代表的通用大语言模型(LLM)虽然能够生成流畅文本,但经常出现“引用幻觉”(Citation Hallucination),即模型凭空捏造文献引用。这种现象严重影响了学术论文的可信度与专业性。
来自主题: AI技术研报
9888 点击 2025-04-11 10:20