推理模型新路线开源!与DeepSeek截然不同,抛弃思维链不用人类语言思考
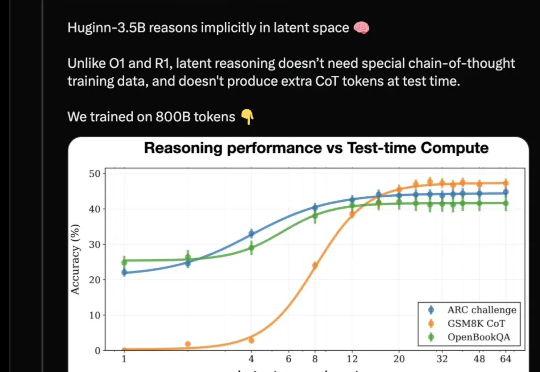
推理模型新路线开源!与DeepSeek截然不同,抛弃思维链不用人类语言思考开源推理大模型新架构来了,采用与Deepseek-R1/OpenAI o1截然不同的路线: 抛弃长思维链和人类的语言,直接在连续的高维潜空间用隐藏状态推理,可自适应地花费更多计算来思考更长时间。
来自主题: AI技术研报
7711 点击 2025-02-12 16:42
 搜索
搜索
开源推理大模型新架构来了,采用与Deepseek-R1/OpenAI o1截然不同的路线: 抛弃长思维链和人类的语言,直接在连续的高维潜空间用隐藏状态推理,可自适应地花费更多计算来思考更长时间。

这一篇文章来源于我自己的困惑而进行的探索和思考,再进行多次讨论后总觉隔靴搔痒,理解不透彻。 而在我自己整理后,发现已经有小伙伴点明了他们的区别。但是因为了解深度的不够,即使告诉了答案,我也无法理解,总有隔靴搔痒之感。
复旦新研究揭示了AI系统自我复制的突破性进展,表明当前的LLM已具备在没有人类干预的情况下自我克隆的能力。这不仅是AI超越人类的一大步,也为「流氓AI」埋下了隐患,带来前所未有的安全风险。

人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。

DeepSeek的爆火,让AI大模型在新一年的开年,又一次引起了全球的关注。然而,时至今日全球AI领域还没有完全消化DeepSeek带来的实质影响——这样的模式将给全球、给中国AI领域带来什么样的变局?
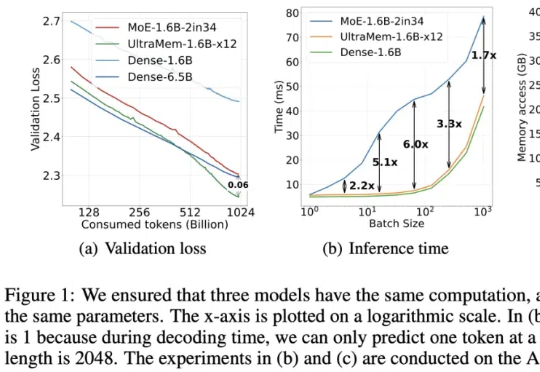
字节出了个全新架构,把推理成本给狠狠地打了下去!推理速度相比MoE架构提升2-6倍,推理成本最高可降低83%。

推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。

先是三星宣布智谱的Agentic GLM成为其新手机Galaxy S25的AI能力来源,紧接着The Information爆料,在经历了近一年的模型测试与合作伙伴探索后,苹果终于敲定了中国市场的合作伙伴:阿里巴巴。这意味着,中国iPhone用户很可能在今年迎来一个由国产大模型驱动的iPhone。

科技公司、车企或者是新消费企业,一时间都宣布接入DeepSeekR1大模型。DeepSeek,成了当下的“AI显学”。网易有道、学而思、云学堂行业里做软件的,做内容的,做平台的都宣布接入DeepSeek大模型。

只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。