GPT Image 2研究科学家陈博远:我在OpenAI修中文
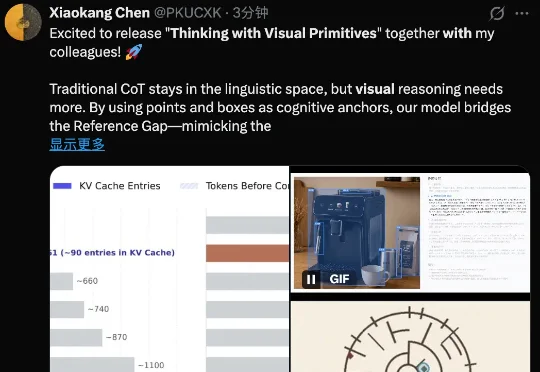
GPT Image 2研究科学家陈博远:我在OpenAI修中文GPT Image 2的发布给整个AI圈带来了亿点点震撼。但很多人可能没注意到,幕后最会玩梗的居然是他——主力训练者陈博远。他和奥特曼同台主持,悄悄修好了中文渲染;给模型起代号“布基胶带”,还拿香蕉艺术品玩梗;为了秀模型的文字能力,设计了米粒刻字、漫画套娃、视觉证明题这些“彩蛋级”测试。
来自主题: AI资讯
8167 点击 2026-05-01 11:07