OpenClaw 一口气补了五块地基,官方只甩了一句:「交付的比吹的多」!
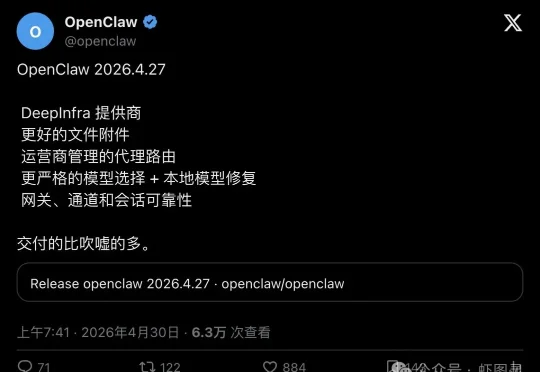
OpenClaw 一口气补了五块地基,官方只甩了一句:「交付的比吹的多」!OpenClaw 刚刚发布 2026.4.27 版本,一次性把 DeepInfra 多模态 provider、非图片附件链路、企业级代理路由、模型选择确定性、网关/通道/会话稳定性五件事全部补齐。近 900 人点赞,6.3 万人围观,社区却吵成两派——一边夸"终于补了生产级地基",一边追问"上几版的 gateway 坑到底填了没"。
来自主题: AI资讯
7017 点击 2026-05-02 11:18