
突破视觉仿真算力瓶颈!新一代具身智能仿真框架开源:高吞吐并行高保真渲染助力规模化训练
突破视觉仿真算力瓶颈!新一代具身智能仿真框架开源:高吞吐并行高保真渲染助力规模化训练为了攻克这些制约具身智能领域发展的核心难题,清华大学智能产业研究院(AIR)DISCOVER Lab联合谋先飞技术、原力灵机、求之科技和地瓜机器人,提出了GS-Playground通用多模态仿真框架。
来自主题: AI技术研报
7757 点击 2026-05-03 22:41
 搜索
搜索
为了攻克这些制约具身智能领域发展的核心难题,清华大学智能产业研究院(AIR)DISCOVER Lab联合谋先飞技术、原力灵机、求之科技和地瓜机器人,提出了GS-Playground通用多模态仿真框架。
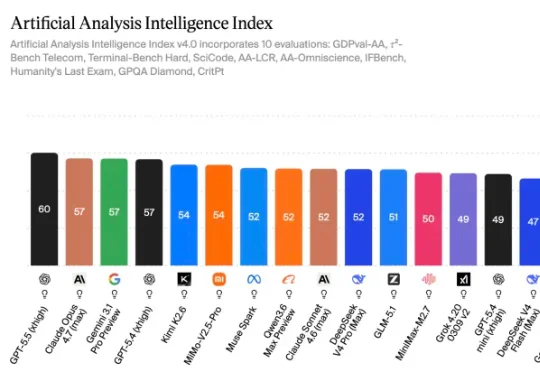
上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放在Agent的场景上测。所以我跟钱包一拍即合,复制了4个一模一样的Hermes Agent,记忆一样,skill一样,系统设置一样,能调用的工具也一样。

OpenAI 和 Anthropic 几乎在同一时间发布自己的提示词文档,在 OpenAI 官网,从 GPT-4.1 到 GPT 5.5,每次新模型发布都有一份完整的提示词指南,告诉我们怎么用新的模型。
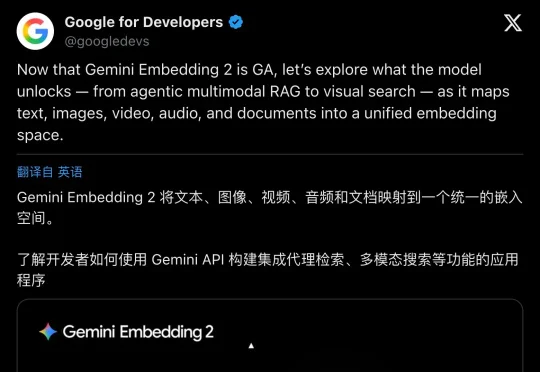
Google悄悄干了一件大事——Gemini Embedding 2正式进入GA阶段,成为Gemini API中第一个原生多模态embedding模型。它能把文本、图片、视频、音频、PDF文档全部映射进同一个统一向量空间,支持100多种语言。
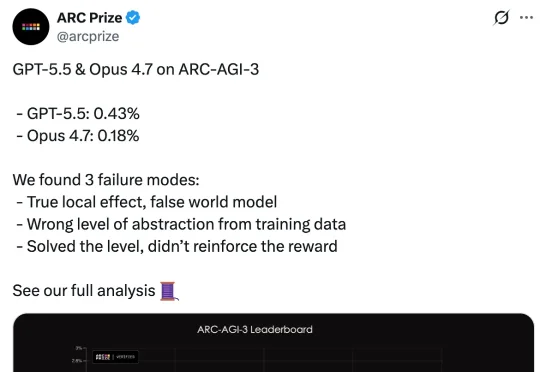
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。

GPT-5.5发布没几天,后台日志里就冒出了GPT-5.6;Anthropic的一个从未见过的代号——Jupiter也炸出了!两天之内,两家巨头的下一代模型同时浮出水面。新一轮模型军备竞赛,比我们想的都要快!

昆仑万维在年报中宣告,公司正全面All in AGI与AIGC,并在2026年将战略升级为"4+3",即以视频、音乐音频、世界、基座文本四大SOTA模型为底座,支撑AI短剧、AI音乐、AI游戏三大平台。

当AI生图真的开始被普通人使用,它会先被用在哪里?所以这次我没有继续测模型或者写Prompt分享。而是去找了10个身边的普通人,问他们怎么开始用AI生图,又为什么会在这些具体的小事上用到它。
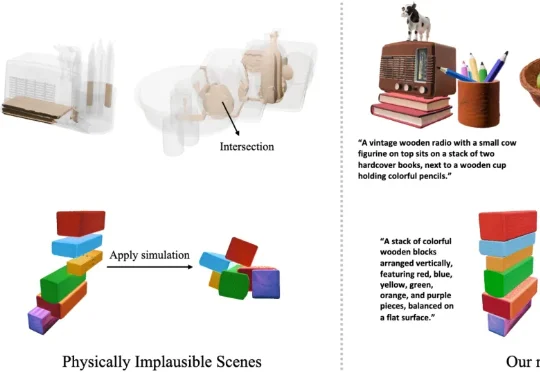
现在的 3D AIGC 已经可以很快生成场景,但离真正落地还有一段距离。很多场景看起来还行,一进物理模拟就会暴露问题,比如物体悬空、互相穿插,甚至还没碰就散。这些问题让它们很难直接用于游戏、XR 或机器人等实际场景。
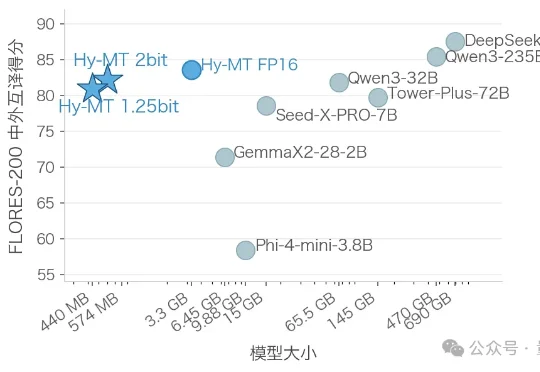
腾讯混元团队刚刚开源了一份硬核解决方案:推出极致量化压缩版本翻译模型Hy-MT1.5-1.8B-1.25bit,把支持33种语言的翻译大模型压缩至440MB。无需联网,下载后即可在手机本地运行 。官方测试显示,其翻译质量优于谷歌翻译。