# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
离线翻译这件事,正在从“能用”走向“好用”。
对出国旅行、跨境办公和本地阅读来说,翻译工具一旦依赖联网,就很容易在弱网、无网或隐私敏感场景里掉链子。
但把翻译大模型真正塞进手机,又会遇到内存和算力限制:模型太大、推理太慢,都很难常驻本地。
为应对这一挑战,腾讯混元团队刚刚开源了一份硬核解决方案:
推出极致量化压缩版本翻译模型Hy-MT1.5-1.8B-1.25bit,把支持33种语言的翻译大模型压缩至440MB。
无需联网,下载后即可在手机本地运行 。官方测试显示,其翻译质量优于谷歌翻译。
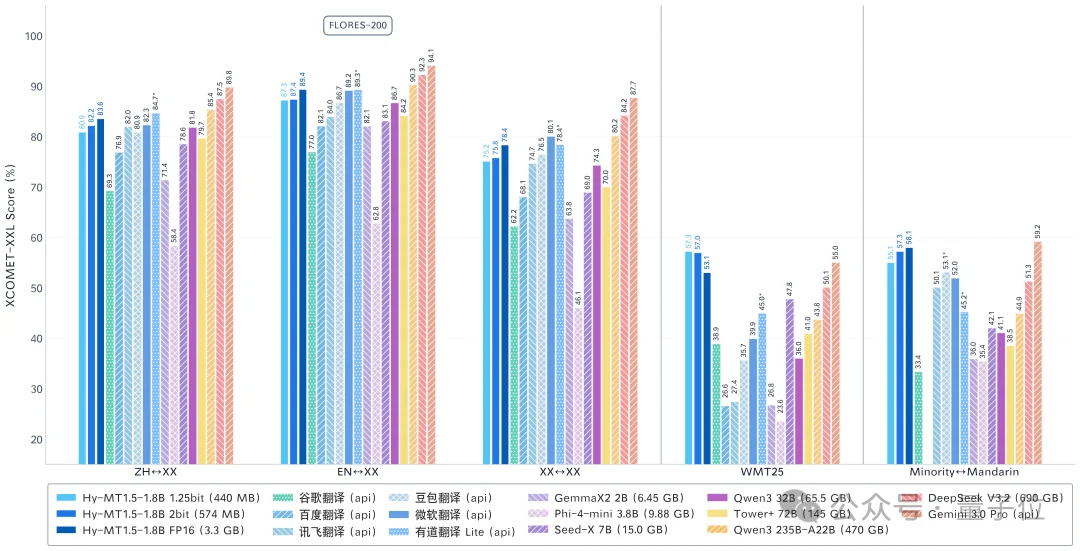
Hy-MT1.5是腾讯混元团队打造的专业翻译大模型,原生支持33种语言、5种方言/民汉及1056个翻译方向。从常见的中英互译,到法语、日语、阿拉伯语、俄语,甚至藏语、蒙古语等少数民族语言,它都能游刃有余地处理。
值得注意的是,1.8B版本的Hy-MT1.5就实现了比肩商业翻译API和235B级大模型的翻译效果。
在严格的评测基准中,其翻译质量不仅超越了谷歌翻译、百度翻译等主流系统,更证明了在高效优化下,轻量级模型能够展现出亮眼的翻译能力。
但问题也很直接:原始的1.8B模型即使在FP16精度下,依然占用3.3GB内存。对于手机上金子般的内存来说,这还是太大、太慢,所以需要量化压缩。
量化压缩,简单来说就是把模型里原本用16位数字(16-bit)表示的参数,改用更低位数字储存。
这就像把一幅高清照片压缩成缩略图,文件小了很多,但你还是能看清楚里面的内容。
针对不同的手机用户,腾讯特别推出了2-bit与1.25-bit两种极致的量化压缩方案。
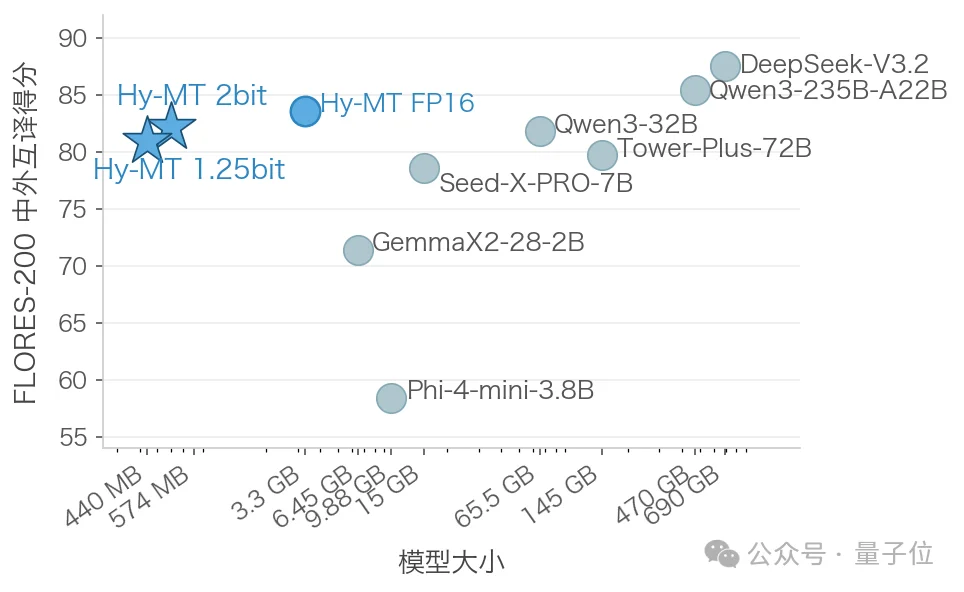
2-bit模型采用了业内顶尖的拉伸弹性量化(SEQ),将模型参数量化至{-1.5,-0.5,0.5,1.5},并结合量化感知蒸馏,在将模型体积压缩至574MB的同时,实现了几乎无损的翻译质量,效果超越上百GB的大模型。在支持Arm SME2技术的移动设备上,2-bit模型能够实现更快速、更高效的推理。
为了达成极致的轻量化,腾讯推出了基于Sherry(稀疏高效三值量化)技术的1.25-bit模型。该技术方案已被NLP顶级学术会议ACL 2026录用。
Sherry压缩方案的核心逻辑在于“细粒度稀疏”策略:每4个模型参数,3个最重要的用1-bit储存,1个用0储存,平均每个参数仅需1.25-bit。
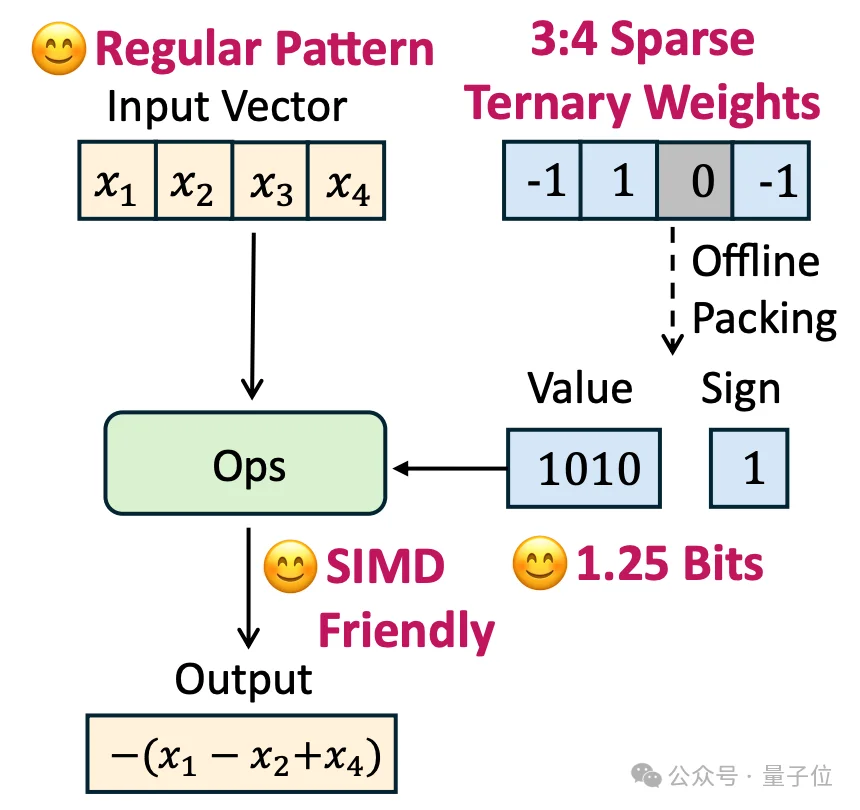
配合腾讯专门为手机CPU设计的STQ内核,该方案实现了对SIMD指令集的适配。最终,3.3GB的原始模型被进一步压缩至440MB,轻松常驻后台,让内存紧张的普通手机也能顺滑进行高质量离线翻译。
FP16(八倍速)vs. 1.25-bit速度对比演示:
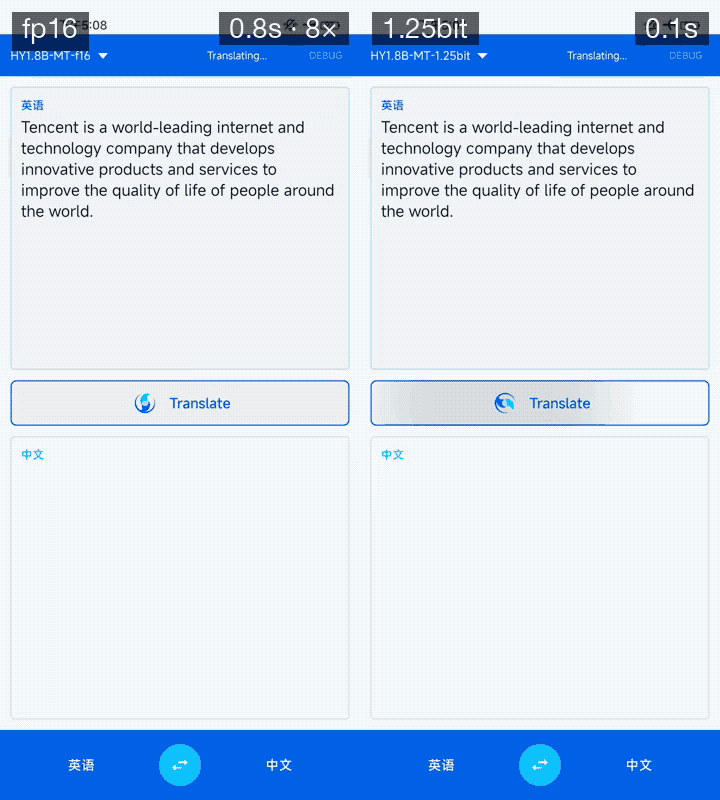
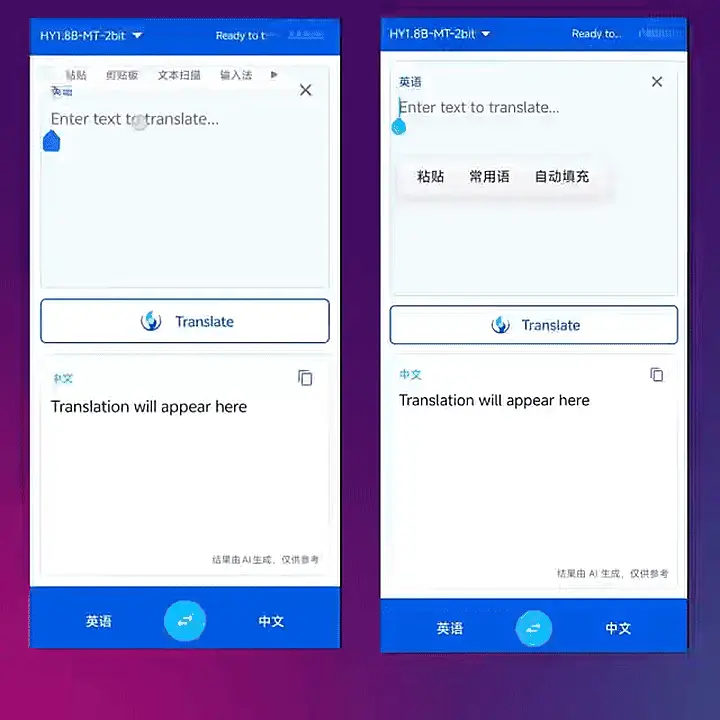
本次开源不仅包含模型权重,腾讯混元团队还制作了一个实际可用的腾讯混元翻译Demo版,特别适配“后台取词模式”。无论是在本地查看邮件还是浏览网页,混元翻译都能随叫随到。无需网络,无需订阅,完全本地处理、不涉及个人信息采集和上传,一次下载永久使用。

所有模型权重、代码及技术报告均已全面开源(目前只支持安卓体验Demo,后续正式版会添加对iOS等平台的支持)。
体验链接:Hugging Face(海外用户):https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-1.25bit-GGUF/resolve/main/Hy-MT-demo.apk魔搭社区(国内用户):https://modelscope.cn/models/AngelSlim/Hy-MT1.5-1.8B-1.25bit-GGUF/resolve/master/Hy-MT-demo.apk
模型下载:Huggingface(海外用户):
魔搭社区(国内用户):
技术报告:
代码仓库:AngelSlim: https://github.com/tencent/AngelSlim
文章来自于微信公众号 "量子位",作者 "量子位"



