腾讯混元最新开源:440M翻译模型手机离线就能用,翻译质量超谷歌
腾讯混元最新开源:440M翻译模型手机离线就能用,翻译质量超谷歌腾讯混元团队刚刚开源了一份硬核解决方案:推出极致量化压缩版本翻译模型Hy-MT1.5-1.8B-1.25bit,把支持33种语言的翻译大模型压缩至440MB。无需联网,下载后即可在手机本地运行 。官方测试显示,其翻译质量优于谷歌翻译。
来自主题: AI资讯
6804 点击 2026-05-02 13:34
 搜索
搜索
腾讯混元团队刚刚开源了一份硬核解决方案:推出极致量化压缩版本翻译模型Hy-MT1.5-1.8B-1.25bit,把支持33种语言的翻译大模型压缩至440MB。无需联网,下载后即可在手机本地运行 。官方测试显示,其翻译质量优于谷歌翻译。

在 AGI-Next 前沿峰会上,腾讯姚顺雨举了一个很生活化的例子:当你问 AI “今天吃什么” 时,真正限制答案质量的,可能不是模型不够大,也不是推理不够强,而是它不知道你今天冷不冷、想不想吃热的、最近和朋友聊过什么、家人又有什么偏好需要纳入考虑。
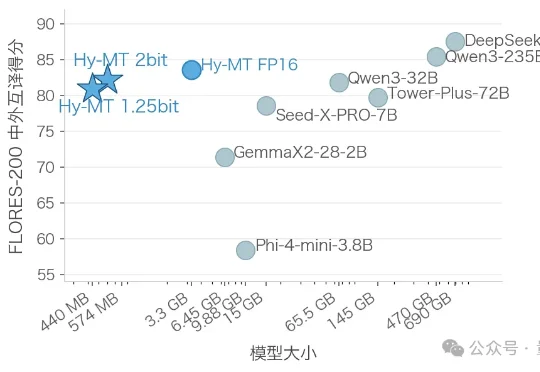
今日,腾讯混元开源翻译模型Hy-MT1.5-1.8B-1.25bit。该模型仅0.4G,就实现了33种语言高质量互译,且下载后可直接在手机本地离线运行,翻译表现优于谷歌翻译。这一原始模型的参数规模为1.8B,为降低用户手机内存压力,腾讯混元团队通过量化压缩推出了适配中高性能手机的2-bit、适配全系列手机的1.25-bit两种方案,模型体积分别被压缩至574MB、440MB。

腾讯混元团队提出了 Multi-Stream Scene Script(MTSS),一种全新的视频描述范式 —— 将传统的 "一段话描述整个视频" 升级为 "多流结构化剧本",通过 Stream Factorization 和 Relational Grounding 两大核心原则,让视频描述既忠实又可扩展,在视频理解和生成任务中均取得显著提升。
刚刚,混元的 Hy3 Preview 也正式亮相,这是腾讯首席 AI 科学家姚顺雨主导的一个模型。姚顺雨表示,Hy3 preview是混元大模型重建的第一步。他希望通过这次开源和发布,不断提升 Hy3 正式版的实用性,以及模型在真实场景中的综合表现,并开始探索特色模型能力。
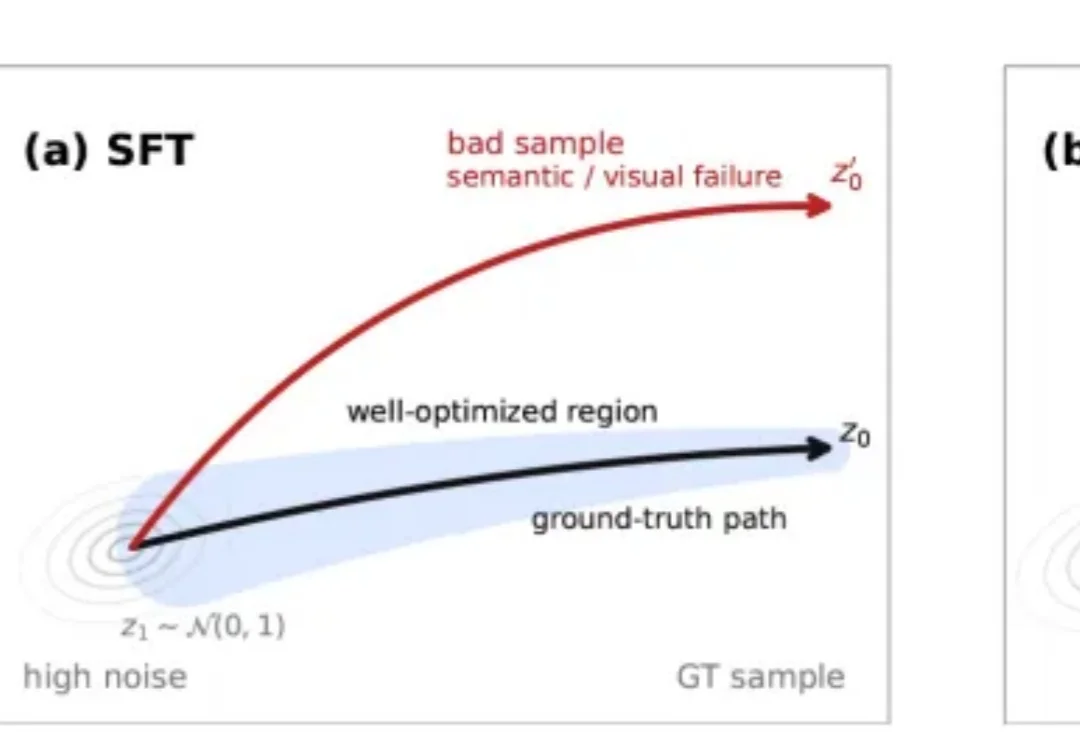
近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。
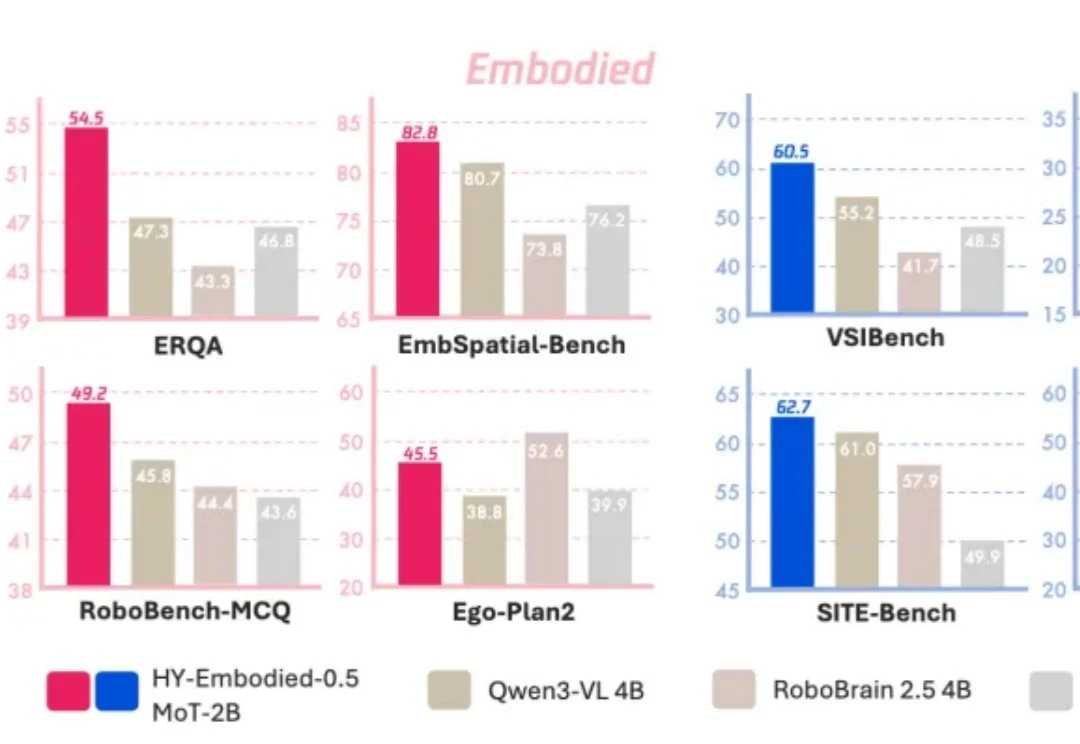
让大模型真正走进现实世界,是当下最迫切的需求之一。

据接近腾讯混元团队的知情人士透露,原字节Seed视觉AI平台团队负责人肖学锋,Infra团队张弛于近期低调入职腾讯,负责大模型Infra相关工作,向腾讯首席AI科学家姚顺雨汇报。

4月21-22日北京站将正式举行~

3月6日,腾讯混元发布了一篇名为“HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing”的技术报告。提出了一种崭新的功能性记忆(functional neural memory)范式(weight unleashing),