
大厂养不起大模型?
大厂养不起大模型?AI投资热下的冷思考:百度传闻风波与行业变现难题;是继续烧钱研发通用大模型,还是加速落地AI商业应用,大模型厂商和投资人们都在焦虑中。
来自主题: AI资讯
9845 点击 2024-09-15 14:55
 搜索
搜索
AI投资热下的冷思考:百度传闻风波与行业变现难题;是继续烧钱研发通用大模型,还是加速落地AI商业应用,大模型厂商和投资人们都在焦虑中。

为什么CueMe无法创造“赛博小雷”?

OpenAI o1 在数学、代码、长程规划等问题取得显著的进步。一部分业内人士分析其原因是由于构建足够庞大的逻辑数据集 <问题,明确的正确答案> ,再加上类似 AlphaGo 中 MCTS 和 RL 的方法直接搜索,只要提供足够的计算量用于搜索,总可以搜到最后的正确路径。然而,这样只是建立起问题和答案之间的更好的联系,如何泛化到更复杂的问题场景,技术远不止这么简单。
作为谷歌 DeepMind 机器学习团队的重量级人物,Nando de Freitas 曾共同领导开发出了 Imagen 2、Gato、Genie、Griffin、Lyria 等名噪一时的大模型产品。
LLM 应该改名吗?你怎么看。

大语言模型(如 GPT-4)具备强大的语言处理能力,但其独立运作时仍存在局限性,如无法进行复杂计算,获取不到实时信息,难以提供专业定制化功能等。而大语言模型的工具调用能力使其不仅限于文字处理,更能提供全面、实时、精确的服务,极大地扩展了其应用范围和实际价值。

近日,成立仅 6 个月的 AI 生物技术初创公司 Chai Discovery,发布用于分子结构预测的新型多模态基础模型 Chai-1,并附带了一份技术报告,比较了 Chai-1 与 AlphaFold 等模型的性能。

当大模型开始思考

随着近年来在文本和视频数据上构建基础模型的进展,学术界对时间序列的基础模型也表现出浓厚的兴趣。 时间序列分析在许多关键领域中具有重要性,能够影响从科学研究到经济决策的广泛应用。
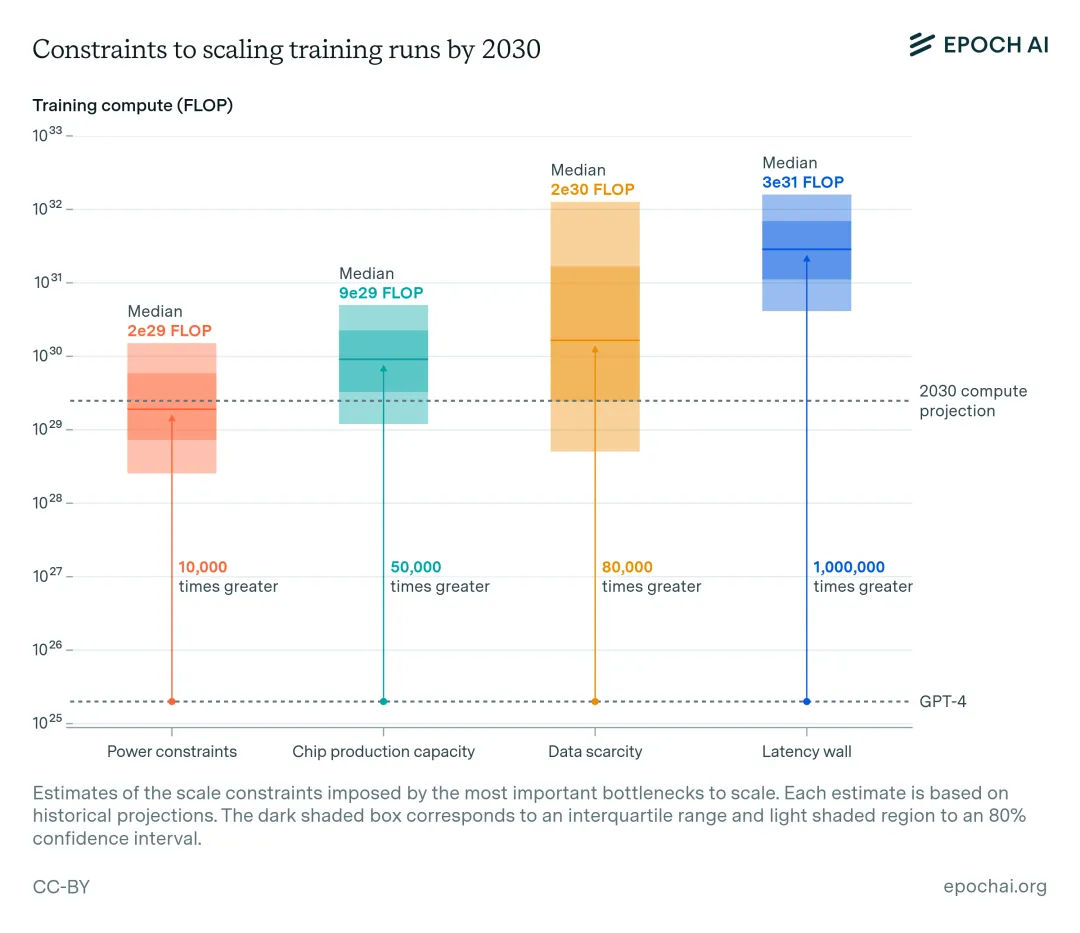
近年来,人工智能模型的能力显著提高。其中,计算资源的增长占了人工智能性能提升的很大一部分。规模化带来的持续且可预测的提升促使人工智能实验室积极扩大训练规模,训练计算以每年约 4 倍的速度增长。