# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型(如 GPT-4)具备强大的语言处理能力,但其独立运作时仍存在局限性,如无法进行复杂计算,获取不到实时信息,难以提供专业定制化功能等。而大语言模型的工具调用能力使其不仅限于文字处理,更能提供全面、实时、精确的服务,极大地扩展了其应用范围和实际价值。
为提高模型的工具调用能力,高质量、多样化、且复杂的训练数据至关重要。然而,现实中工具调用数据的收集和标注极为困难,现有的合成数据生成方式在覆盖率和准确性方面仍存在不足。
针对这一挑战,华为诺亚方舟实验室联合中科大等机构的研究人员提出了一个统一的工具调用数据合成框架 ToolACE,可以自动化地生成高准确性、高复杂性、高多样性的工具调用数据。ToolACE 通过创新的自进化合成过程,构建了一个包含 26,507 个多样化 API 的 API 库。通过多智能体之间的交互生成对话,并通过形式化的思维过程进行引导,确保生成的数据复杂且多样化。并结合了基于规则和基于模型的数据质检机制,确保数据准确性。基于对应合成数据对 Llama 3.1 进行微调,以 8B 的模型量级,在开源工具调用榜单 BFCL(
https://gorilla.cs.berkeley.edu/leaderboard.html)中持平 GPT-4,获得开源第一,超过如 Functionary 等 70B 模型效果。

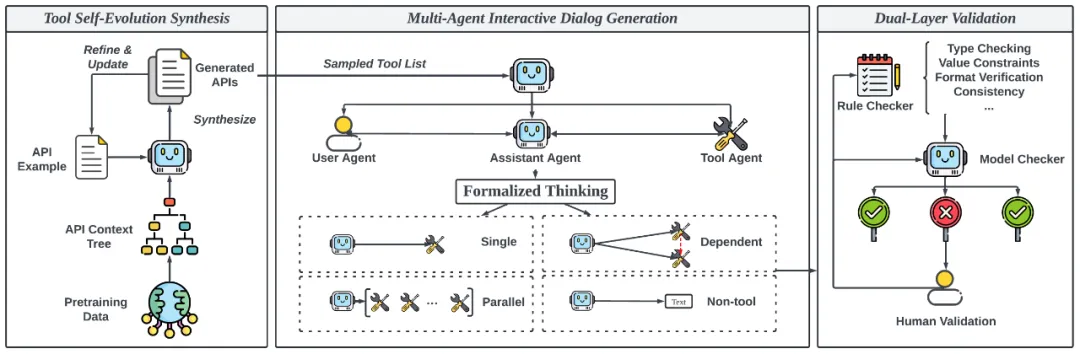
图 1. ToolACE 数据合成框架图
ToolACE 工具调用数据合成框架
ToolACE 的数据合成流程分为 API 生成、对话生成、数据质检三个阶段:
基于自演进的 API 合成:多样化的 API 能够显著提升工具调用数据的多样性和复杂性。ToolACE 利用基于自演进的 API 合成模块构建了一个包含 26,507 个 API 库,在数量和领域覆盖上均超越了其他代表性的工具调用数据。基于自演进的 API 合成模块可以根据不同的数据类型和约束条件合成新的工具描述。具体来说,该模块利用多样的网页预训练数据提取了一个 API 上下文树,每个节点代表一个潜在的应用领域和函数调用的功能,如金融、健康、交通等。通过由 API 上下文树中进行采样,结合给定的 API 示例,由语言模型可以合成新的 API。API 的多样性和复杂性通过递归的自我进化和更新逐渐增加。
基于多智能体交互的对话生成:ToolACE 利用多智能体交互的方式进行工具调用对话合成,所生成的对话涵盖了多种类型,包括简单函数调用、并行函数调用、依赖函数以及非工具使用的对话。
对话生成过程首先从构建好的 API 库中采样一个或多个候选 API,之后通过三个不同的智能体(用户、助手和工具)的互动生成对话,每个智能体都由大语言模型模拟。用户智能体主要提出请求或提供额外信息,请求的多样性和复杂性由多模式提示和基于相似性的复杂化策略来保证。助手智能体则使用给定的 API 来完成用户提出的请求。助手智能体的操作空间包括:调用 API、请求进一步信息、总结工具反馈以及提供非工具使用的回答。每个操作都通过形式化的思考过程确定,并通过自我一致性验证以确保准确性。工具智能体作为 API 执行者,处理助手提供的工具描述和输入参数,并模拟输出潜在的执行结果。所生成的对话可进一步进行格式泛化为不同的工具调用格式。
双层数据质检流程:影响大语言模型工具调用能力的一个关键因素是训练数据的准确性和可靠性。不一致或不准确的数据会阻碍模型理解和执行工具的能力。与一般问答数据不同,工具调用数据的正确性更容易验证,因为成功的工具调用必须严格符合 API 定义中指定的格式。因此,ToolACE 提出了结合规则质检和模型质检的双层数据质检流程对合成数据进行校验。规则质检保证数据严格遵循 API 定义的格式和结构要求,确保工具调用的可执行性。模型质检则进一步对规则难以处理的问题进行检查,如幻象和数据不一致性。
实验验证
数据分布:ToolACE 数据共包含了 26507 个不同的 API,来自于不同的领域。下图展示了各个领域的 API 数量分布,以及在娱乐(Entertainment)领域的二级 API 分布。
图 2. ToolACE 数据集 API 领域来源分布
此外,ToolACE 数据集中 API 的参数覆盖多个类型:字符串(string),浮点数(float),整数(int),字典(dict),数组(array)等。且数据中含有单工具调用(single)、并行多工具调用(parallel)、多轮数据(multi-turn)、工具依赖调用(dependency)和无需工具调用(non-tool)等多种可能情形,分布如下图所示。
图 3. ToolACE 数据 API 参数类型分布和工具调用形式分布
工具调用能力验证:研究团队使用 ToolACE 方案生成的数据集,对开源的 LLaMA-3.1-8B-Instruct 模型进行 LoRA 微调得到 ToolACE-8B 模型,并在加州大学伯克利分校团队发布的工具调用测试榜单 BFCL 上进行评估,在 BFCL 上击败所有模型获得榜首。
表 1. 模型在 BFCL-v2 榜单上的工具调用性能比较(榜单数据更新于 2024/08/16)。表中选择排名前 20 的模型作为比较。
通用能力验证:研究团队对训练后模型的综合通用能力进行测试,实验涵盖通用理解任务、代码生成任务、数学推理任务、尝试问答任务以及工具调用任务,结果证明 ToolACE-8B 模型在大幅提升工具调用能力的同时,相比于基座模型(LLaMA-3.1-8B-Instruct)并未明显损失其他能力,且各方面明显优于同规模开源工具调用模型 xLAM-7B-fc-r。
图 4. ToolACE-8B 模型通用能力评估
相关文献
[1] Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334, 2023.
[2] Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases. arXiv preprint arXiv:2306.05301, 2023.
[3] Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Shirley Kokane, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, et al. Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets. arXiv preprint arXiv:2406.18518, 2024.
[4] Meetkai. Functionary.meetkai. 2024.
[5] Ibrahim Abdelaziz, Kinjal Basu, Mayank Agarwal, Sadhana Kumaravel, Matthew Stallone, Rameswar Panda, Yara Rizk, GP Bhargav, Maxwell Crouse, Chulaka Gunasekara, et al. Granitefunction calling model: Introducing function calling abilities via multi-task learning of granular tasks. arXiv preprint arXiv:2407.00121, 2024.
[6] Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789, 2023.
文章来源“机器之心”,作者“机器之心”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
