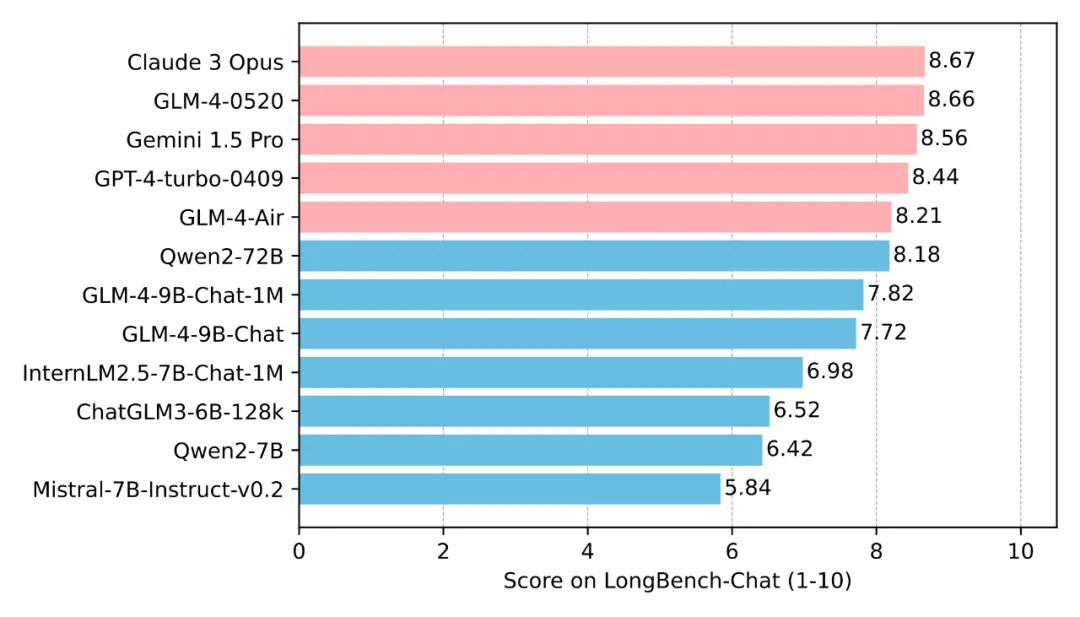
如何将 LLM 的上下文扩展至百万级?
如何将 LLM 的上下文扩展至百万级?在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k。然而,时至今日,1M的上下文长度已经成为衡量模型技术先进性的重要标志之一。
来自主题: AI技术研报
6985 点击 2024-07-19 10:14
 搜索
搜索
在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k。然而,时至今日,1M的上下文长度已经成为衡量模型技术先进性的重要标志之一。
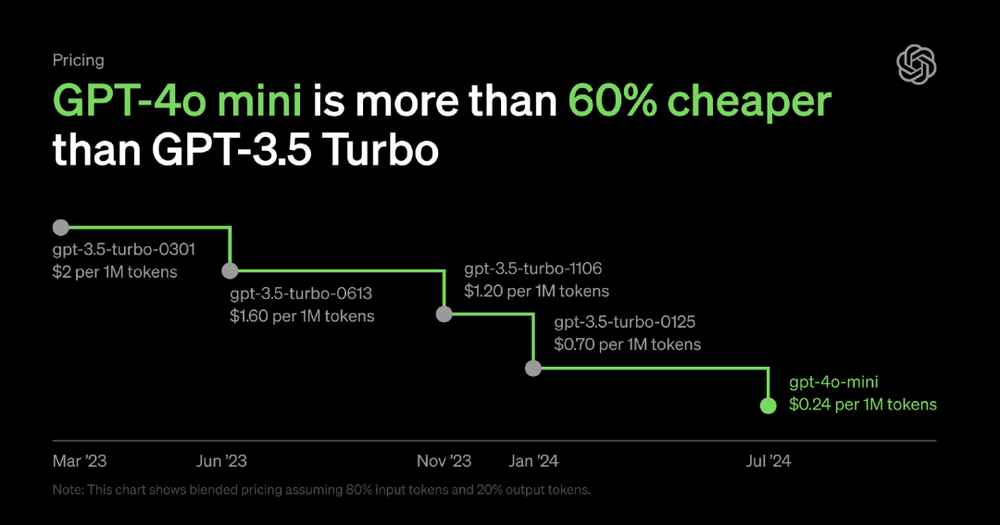
今天凌晨,OpenAI 突然发布了他们的“最具性价比”的新一代模型 GPT-4o mini。

大模型测试能拿高分,实际场景中却表现不佳的问题有解了。
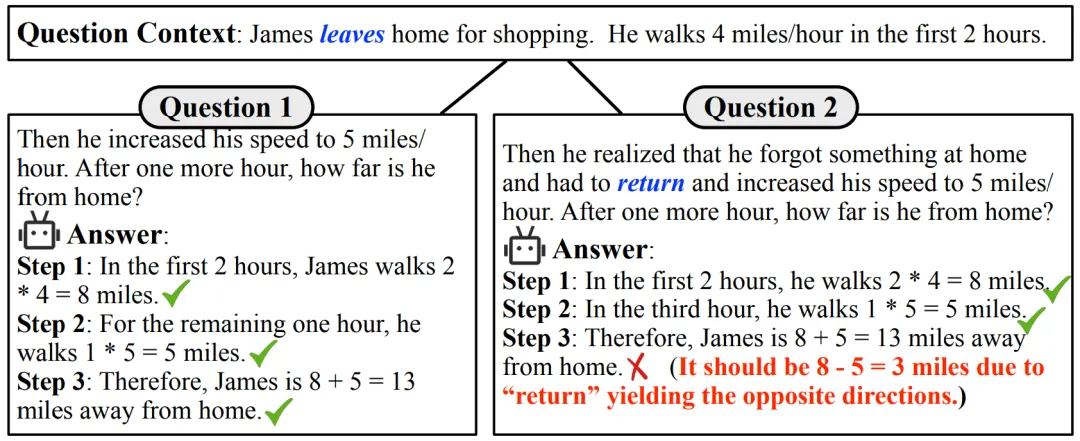
大型语言模型(LLMs)在解决问题方面的非凡能力日益显现。最近,一个值得关注的现象是,这些模型在多项数学推理的基准测试中获得了惊人的成绩。以 GPT-4 为例,在高难度小学应用题测试集 GSM8K [1] 中表现优异,准确率高达 90% 以上。同时,许多开源模型也展现出了不俗的实力,准确率超过 80%。
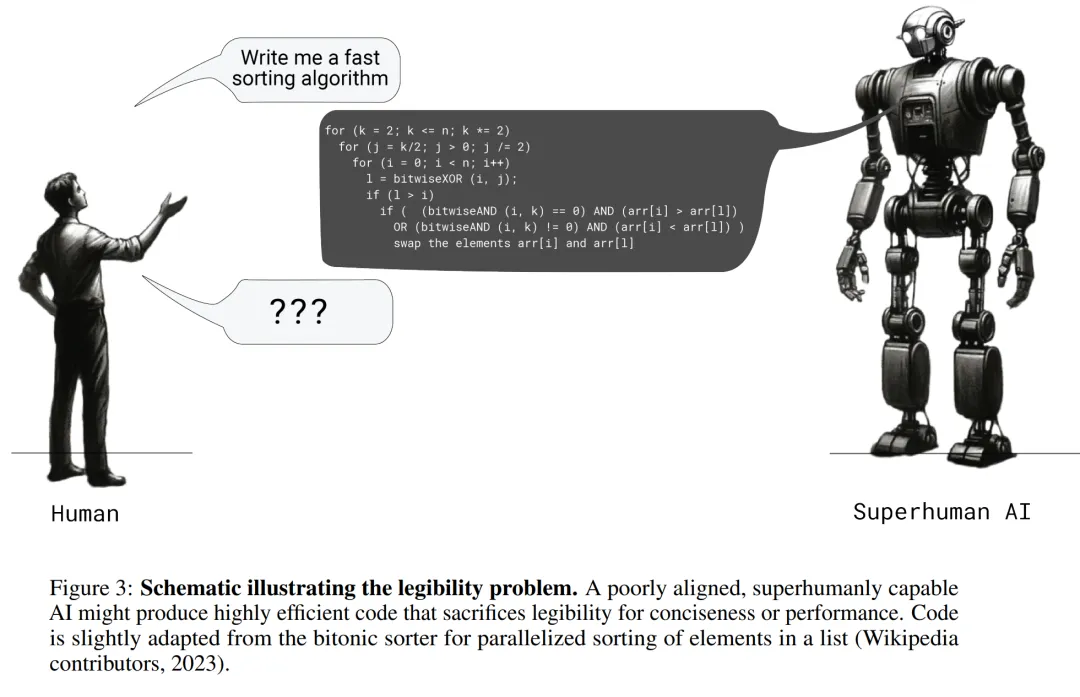
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
离开快手创业后,「李岩」悄悄拿到了快手联合创始人宿华、红点创投以及经纬创投的3200万美金种子轮融资。

只需激活60%的参数,就能实现与全激活稠密模型相当的性能。

让大小模型相互博弈,就能实现生成内容可读性的提升!

刚刚,信息检索领域的国际顶会SIGIR 2024,公布了最终获奖结果。在所有获奖名单中,来自清华计算机系的团队们斩获了两大奖项——时间检验奖、最佳论文奖,实至名归!

当我们不停在CoT等领域大下苦功、试图提升LLM推理准确性的同时,OpenAI的对齐团队从另一个角度发现了华点——除了准确性,生成答案的清晰度、可读性和可验证性也同样重要。