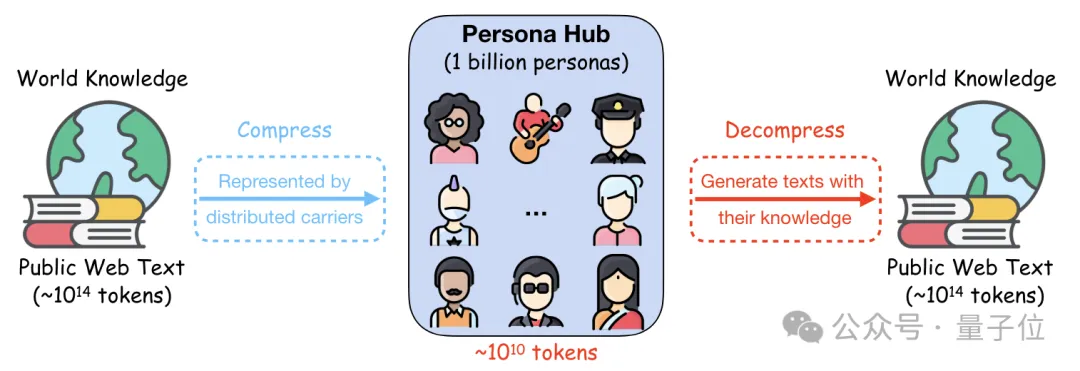
鹅厂造10亿虚拟人格专搞数据合成:让7B模型数学成绩打平GPT4,还能给弱智吧出题
鹅厂造10亿虚拟人格专搞数据合成:让7B模型数学成绩打平GPT4,还能给弱智吧出题10亿名“员工”生产数据合成,数量占到了世界人口的13%。
来自主题: AI资讯
5200 点击 2024-07-02 18:09
 搜索
搜索
10亿名“员工”生产数据合成,数量占到了世界人口的13%。

文生图也有自己的prompt优化工具了。

只要把推理和感知能力拆分,2B大模型就能战胜20B?!

因为 AI 为自己的工作焦虑,这件事不是一天两天了。
AI 考古,追溯到了祖师爷头上。

神经网络通常由三部分组成:线性层、非线性层(激活函数)和标准化层。线性层是网络参数的主要存在位置,非线性层提升神经网络的表达能力,而标准化层(Normalization)主要用于稳定和加速神经网络训练,很少有工作研究它们的表达能力,例如,以Batch Normalization为例
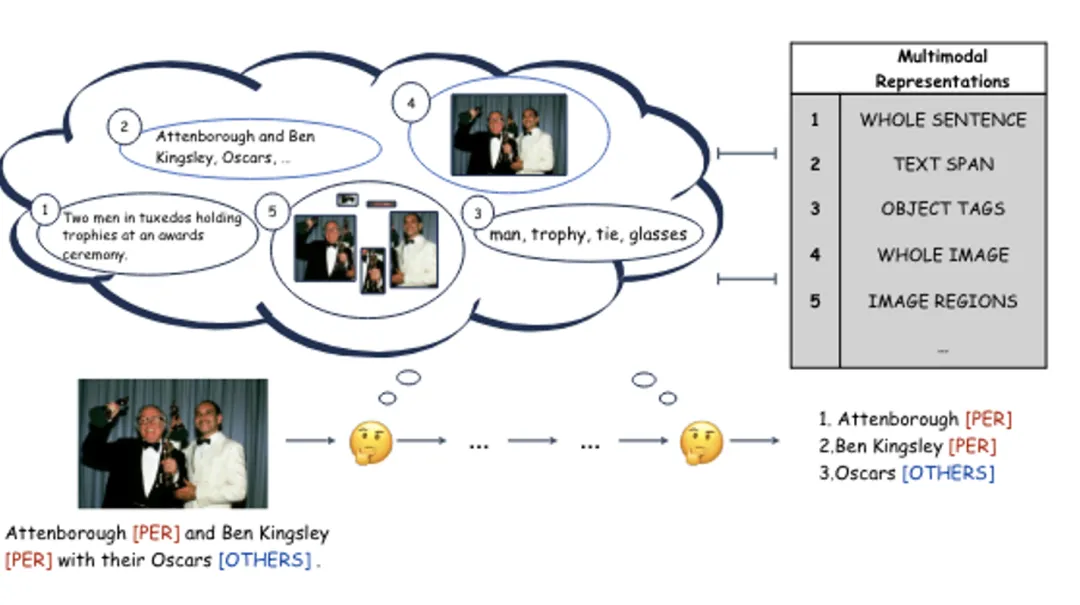
多模态命名实体识别,作为构建多模态知识图谱的一项基础而关键任务,要求研究者整合多种模态信息以精准地从文本中提取命名实体。尽管以往的研究已经在不同层次上探索了多模态表示的整合方法,但在将这些多模态表示融合以提供丰富上下文信息、进而提升多模态命名实体识别的性能方面,它们仍显不足。

「微调你的模型,获得比GPT-4更好的性能」不只是说说而已,而是真的可操作。最近,一位愿意动手的ML工程师就把几个开源LLM调教成了自己想要的样子。

两年一届的ECCV录用结果终于揭晓了!刚刚,ECCV组委会公布了录用论文名单,共有2395篇论文被录用。
最近,在美国00后中爆火的Character AI,竟然把聊天机器人对话模型给「阉割」了?愤怒的年轻人们冲进社区,抱怨的声浪快要掀翻天了!而这背后,似乎还有谷歌或Meta的授意。