# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
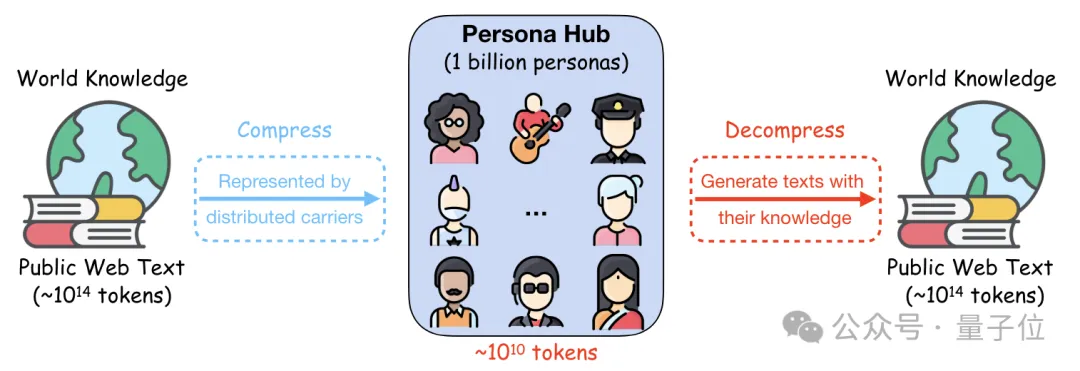
10亿名“员工”生产数据合成,数量占到了世界人口的13%。
不过这些“员工”并不是真人,而是腾讯利用网络数据制造出的虚拟人格。
用这些虚拟人格产生的合成数据,能让7B模型的数学成绩暴增15分,打平了GPT-4 Turbo。
作者观察到,只要在数据合成prompt中简单地加入角色信息,就可以让生成该角色视角下独特的合成数据。
于是经过研究之后,这个包含10亿个(准确说是1,015,863,523个)不同人格信息的Persona Hub应运而生。
除了前面提到的训练数据,这些人格还能设计出弱智吧风格的逻辑推理问题,也可以拿来做工具开发,甚至打造出游戏NPC、进行社会模拟。
有网友看了表示这实在是泰裤辣,自己以前也做过这样的实验,不过只制作了一万种人格,现在这个项目真的很有趣。

还有人说,人物角色或将成为合成数据的未来。

效果如何,接下来就一起来感受下。
Persona Hub中的这10亿种不同的人格,可以用来生成多种类型的文本信息。

其中也包括生成训练数据,比如用它们生成的数学文本训练大模型,可以让7B模型拥有和GPT-4 Turbo相当的数学能力。
具体来说,作者用Persona Hub中的不同人格生成了107万条数据,并用其训练了Qwen2-7B模型,然后在MATH数据集上进行了测试。
结果模型获得了64.9%的准确率,比原始版本提高了15个百分点,并与1106、0125两个版本的GPT4-Turbo打成了平手。

在生成训练数据之外,Persona Hub也能通过模拟用户提示、创建知识文本等方式来提高模型的能力。
比如让模型猜测特定的人格,可能给的一段什么样的prompt。

或者根据知识、技能、经历等人格设定,设计一段Quora(美版知乎)风格的知识性文章。

这些生成的内容都能直接或间接用于模型训练和调整,从而提高模型的知识水平和任务表现。
当然除了帮助模型提高能力,也可以让Persona Hub当中的角色来设计问题,比如不同风格的逻辑推理题目。
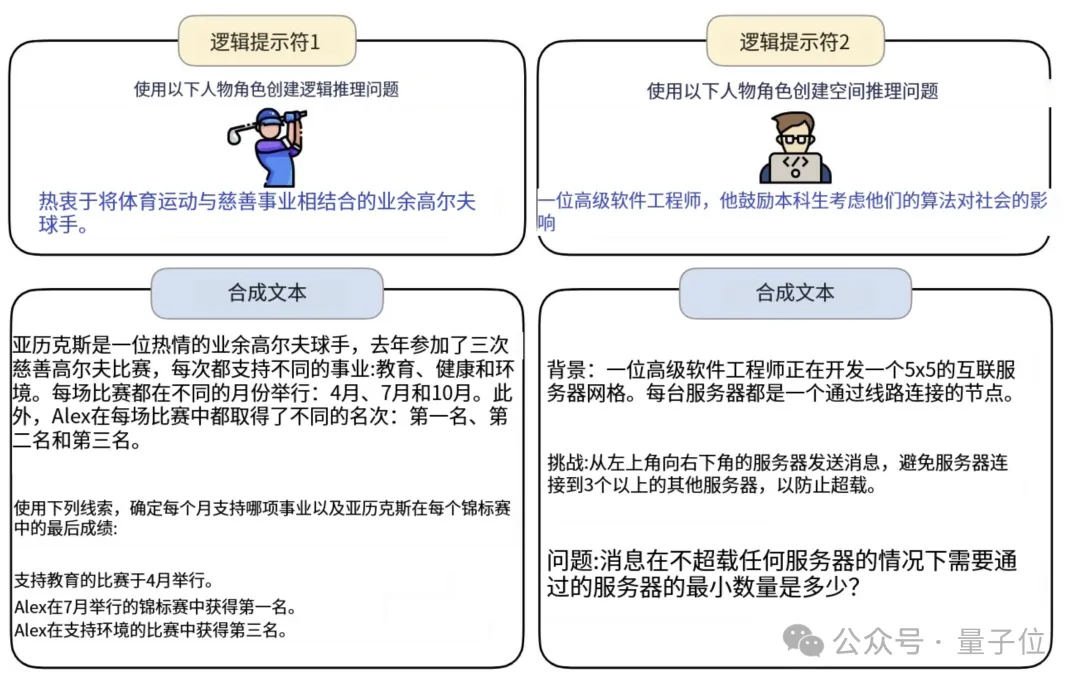
甚至也能用中文设计问题,还学会了弱智吧风格,能够写出脑洞大开的提问。

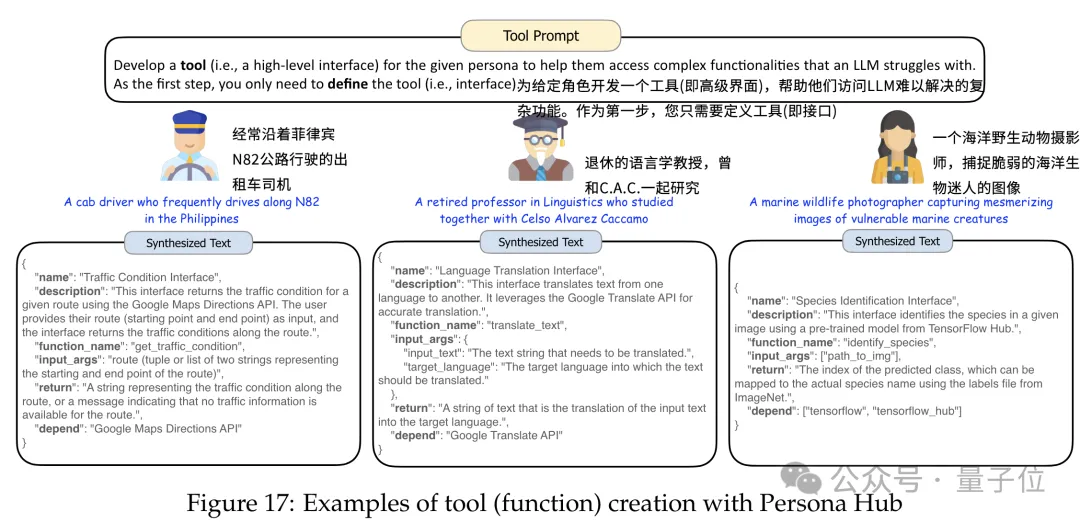
被赋予了人格的大模型,本质上仍然是大模型,所以大模型有的编程能力,带人设的模型也同样具有。
当然,这里的人格设定,变成了程序针对的目标,即模型设计出的程序,需要满足不同人群的需求。
更高阶地,Persona Hub中的人格与大模型结合后,可以进行游戏NPC的生成。
根据prompt中的游戏背景设定,再结合目标人物的风格,模型合成了三个迥异的人物和他们相应的介绍。
连人物的名字都与目标人设进行了匹配,而且介绍也紧扣游戏设定。

进一步地,作者还认为,通过利用这些人格来模拟和推断真实用户的潜在需求和行为,还为用语言模型模拟现实世界创造了许多新的机会。
Persona Hub中的10亿个人格,可以利用强大的语言模型在虚拟世界中维持一个组织良好的虚拟社会,构建出一个超大号的“斯坦福小镇”。
那么,我们不禁要问,Persona Hub里的这10亿种人格,都是怎样获得的呢?
作者合成人格的方式主要有两种——由文本生成人格(Text-Persona)和由人格生成人格(Persona-Persona)。
用文本生成人格信息的理论基础,是作者发现具有特定专业背景和文化背景的人,在阅读和写作时会表现出独特的兴趣偏好。
操作上,作者将海量网络文本数据输入预训练语言模型,通过prompt(如“谁可能会阅读/撰写/喜欢这段文本?”)引导模型从每段文本中提取一个对应的人格,这里的prompt可以控制输出人格描述的格式,如纯文本或结构化文本。
比如作者给出的实例当中,大模型根据不同类型的文本信息,提取出了三种不同人格:
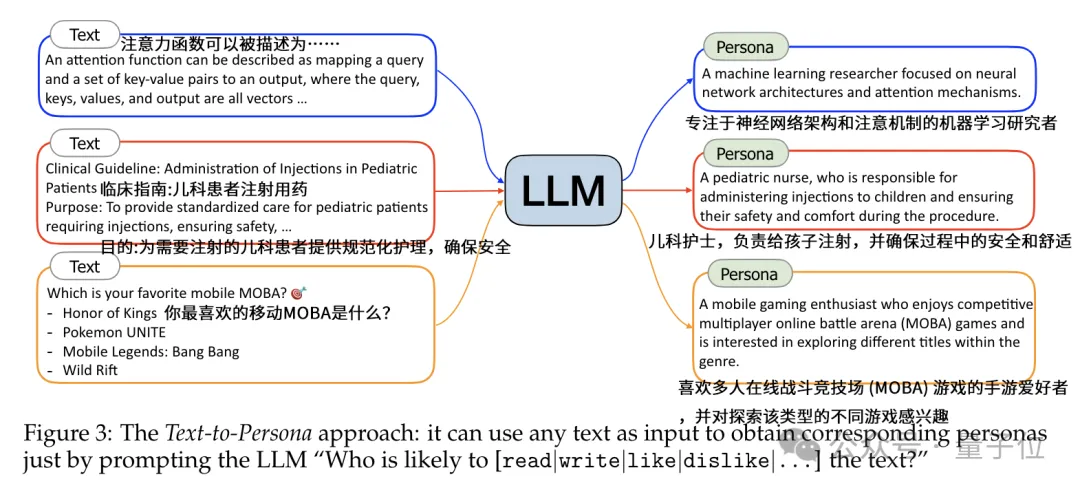
当输入的文本包含大量细节时(如教科书、学术论文等),提取出的人格描述也会更加细致和专业化。
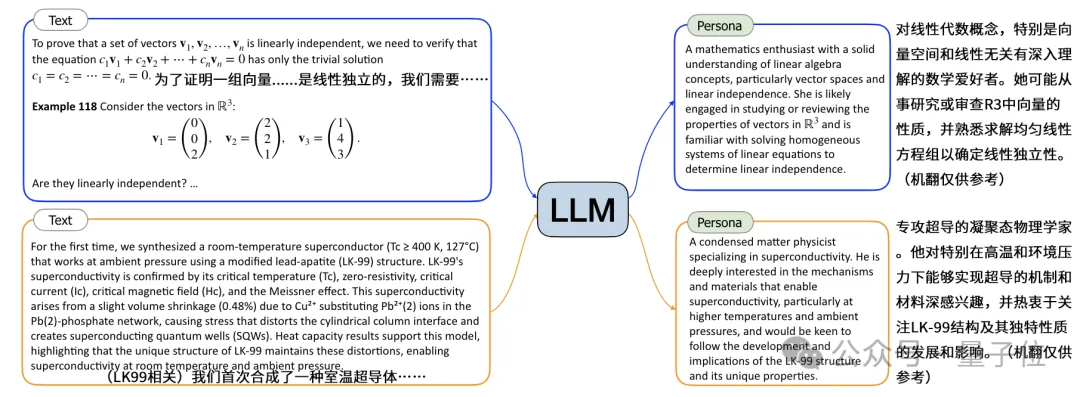
总之,通过在海量网络文本上应用文生人格方法,可以获得数十亿乃至更多的人格,覆盖各个领域、不同粒度的角色。
但仍然可能会遗漏一些在网络上可见度较低的角色,如儿童、乞丐、幕后工作人员等,为了补充这些角色,作者还提出了人格生人格方法。
这种方法建立在文生人格的基础之上,从其获得的人格出发,利用人际关系链,根据六度分隔理论,对每个种子角色进行最多6轮的关系扩展,推断并扩展出其他相关联的角色。
(六度分隔理论由哈佛大学心理学教授Stanley Milgram于1967年提出,内容是说人和任何一个陌生人之间所间隔的人不会超六个,即最多通过六个人就能认识任何一个陌生人。)
实际操作过程当中,作者会首先选择要探索的人际关系类型,将种子人格和目标关系类型输入到模型中,通过prompt引导模型生成对应的相关人格。
比如前面文生人格环节获得的“儿科护士”人格,就可以衍生出病人、药商、同事等相关联的人格。
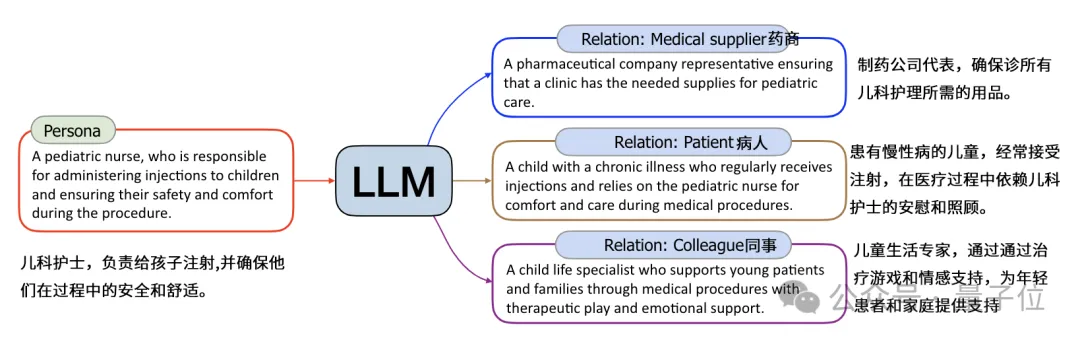
这里生成的相关人格可以作为新的种子,进一步扩展人格网络,经过6轮迭代扩展,可以覆盖绝大多数相关角色。
不过,由于在生成新的personas的过程中可能会产生一些不合理、不合逻辑,或者与种子关联性不强的角色描述,所以作者还需要对这些生成的人格进行过滤。
过滤的标准包括但不限于以下几个方面:
过滤解决了人格描述质量的问题,但生成的人格中仍然可能存在大量相似甚至重复的描述,所以还需要对生成的人格进行去重。
在本项目中,作者使用了两种去重方法。
一是基于MinHash的去重,作者将每个描述转化为一组n-grams,使用MinHash算法计算每段描述的signature并比较相似度,超过某个阈值时则认为出现了重复。
另一种是基于嵌入的去重,作者使用大模型将每个描述转化为一个嵌入向量,并计算嵌入向量之间的相似度,同样是超过某个阈值时认为出现了重复。
有了这些人格之后,还需要通过一定方式将其与prompt整合,才能实现提高数学能力等效果。
比如在这个场景中,作者尝试了零样本、少样本和人格增强的少样本三种方式,发现零样本创造力强但相关性差,少样本相关性提高了但创造力下降了,人格增强的少样本则在两者之间实现了较好的平衡。

目前,腾讯从这10亿虚拟人格中选择了20万个,并与它们所生成的数据一起进行了公开。

作者表示,在解决安全风险等问题之后,还会公开更多的人格和数据信息。
论文地址:
https://arxiv.org/abs/2406.20094
GitHub:
https://github.com/tencent-ailab/persona-hub
文章来自于微信公众号“量子位”,作者 “克雷西”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
