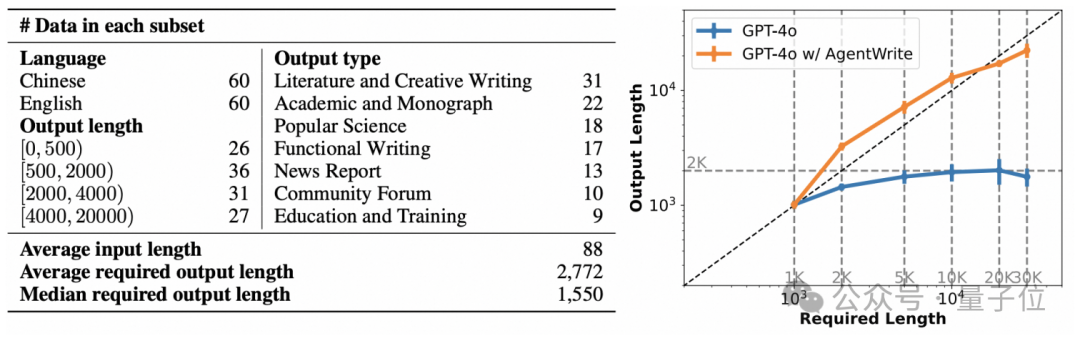
666条数据教会AI写万字长文!模型数据集都开源
666条数据教会AI写万字长文!模型数据集都开源仅需600多条数据,就能训练自己的长输出模型了?!
来自主题: AI技术研报
9249 点击 2024-09-27 18:33
 搜索
搜索
仅需600多条数据,就能训练自己的长输出模型了?!
大模型产业发展,需要可信中立的数据深加工平台,如何填补空白?
AI卫星影像知识生成模型数据集稀缺的问题,又有新解了。

本周五,一年一度的AI春晚“北京智源大会”正式开幕。本次大会AI明星浓度,放在全球范围内可能也是独一份:OpenAI Sora负责人Aditya Ramesh作为神秘嘉宾进行了分享,并接受了DiT作者谢赛宁的“拷问”、李开复与张亚勤炉边对话AGI、还集齐了国内大模型“四小龙”,百川智能CEO王小川、智谱AI CEO张鹏、月之暗面CEO杨植麟、面壁智能CEO李大海…… 这还只是第一天上午的开幕式。

本文是对发表于模式识别领域顶刊Pattern Recognition 2024的最新综述论文:「Advancements in Point Cloud Data Augmentation for Deep Learning: A Survey 」的解读。

昨天,Meta、纽约大学的研究者用「自我奖励方法」,让大模型自己生成自己的微调数据,从而在 Llama 2 70B 的迭代微调后超越了 GPT-4。今天,英伟达的全新对话 QA 模型「ChatQA-70B」在不使用任何 GPT 模型数据的情况下,在 10 个对话 QA 数据集上的平均得分略胜于 GPT-4。
本文探讨了大模型套壳的问题,解释了大模型的内核和预训练过程。同时,介绍了“原创派”和“模仿派”两种预训练框架的差异,并讨论了通过“偷”聊天模型数据进行微调的现象。最后,提出了把“壳”做厚才是竞争力的观点。
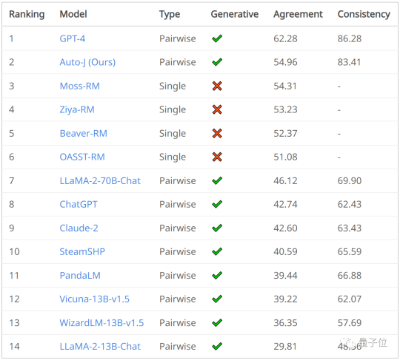
评估大模型对齐表现最高效的方式是?在生成式AI趋势里,让大模型回答和人类价值(意图)一致非常重要,也就是业内常说的对齐(Alignment)。

郑雯至今觉得记得几个月的下午,那天,她一个小时就赚了2毛钱。她毕业于湖南的一所专科学校,是一名大模型数据标注师