
从图像到视频的任意分割:X2SAM让MLLM 真正看懂像素级时空世界
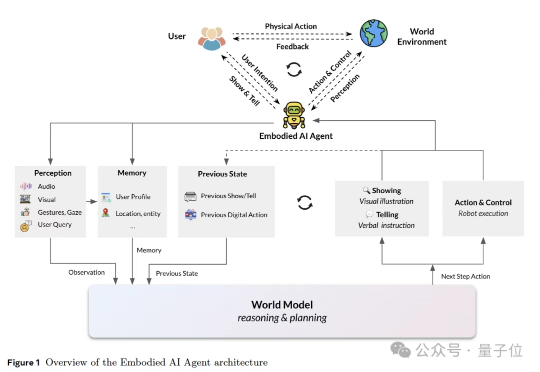
从图像到视频的任意分割:X2SAM让MLLM 真正看懂像素级时空世界为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。
来自主题: AI技术研报
7806 点击 2026-05-16 10:50
 搜索
搜索
为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。

围绕这一挑战,上海人工智能实验室联合复旦大学、南京大学、南洋理工大学 S-Lab 等单位提出了 LongVie 2—— 一个能够生成长达 5 分钟高保真、可控视频的世界模型框架。

麻省理工学院最新研究预示着人类距离能够自主学习的AI又迈出了关键一步。该研究推出了一种全新的自适应大模型框架「SEAL」,让模型从「被动学习者」变为「主动进化者」。

北京深度逻辑智能科技有限公司推出了 LLaSO—— 首个完全开放、端到端的语音语言模型研究框架。LLaSO 旨在为整个社区提供一个统一、透明且可复现的基础设施,其贡献是 “全家桶” 式的,包含了一整套开源的数据、基准和模型,希望以此加速 LSLM 领域的社区驱动式创新。
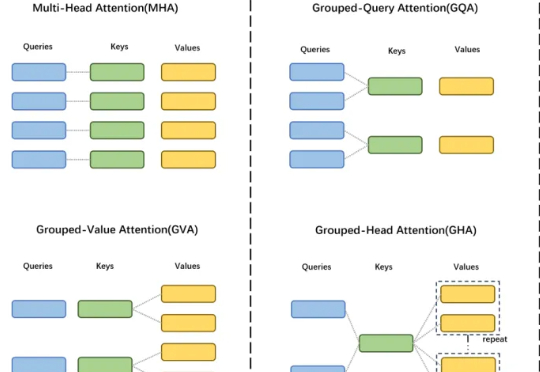
GTA 工作由中国科学院自动化研究所、伦敦大学学院及香港科技大学(广州)联合研发,提出了一种高效的大模型框架,显著提升模型性能与计算效率。
这篇报告第一次把对人心智状态的推断,放到和物理世界模型(physical world model)同等重要的位置上,并将其概念化为心智世界模型(mental world model)。相比于传统世界模型(如LeCun的JEPA)仅关注物理规律(物体运动、机械因果),心智世界模型则首次将心理规律(意图、情感、社会关系)纳入世界模型框架,实现“双轨建模”。

自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。

你是否曾对着一个繁复的AI框架,无奈地想:"真有必要搞得这么复杂吗?"在与臃肿框架斗争一年后,Zachary Huang博士决定大刀阔斧地革新,剔除所有花里胡哨的部分。于是Pocket Flow诞生了——一个仅有100行代码的超轻量级大语言模型框架!

一个新框架,让Qwen版o1成绩暴涨: 在博士级别的科学问答、数学、代码能力的11项评测中,能力显著提升,拿下10个第一! 这就是人大、清华联手推出的最新「Agentic搜索增强推理模型框架」Search-o1的特别之处。

多模态模型,统一图像生成。