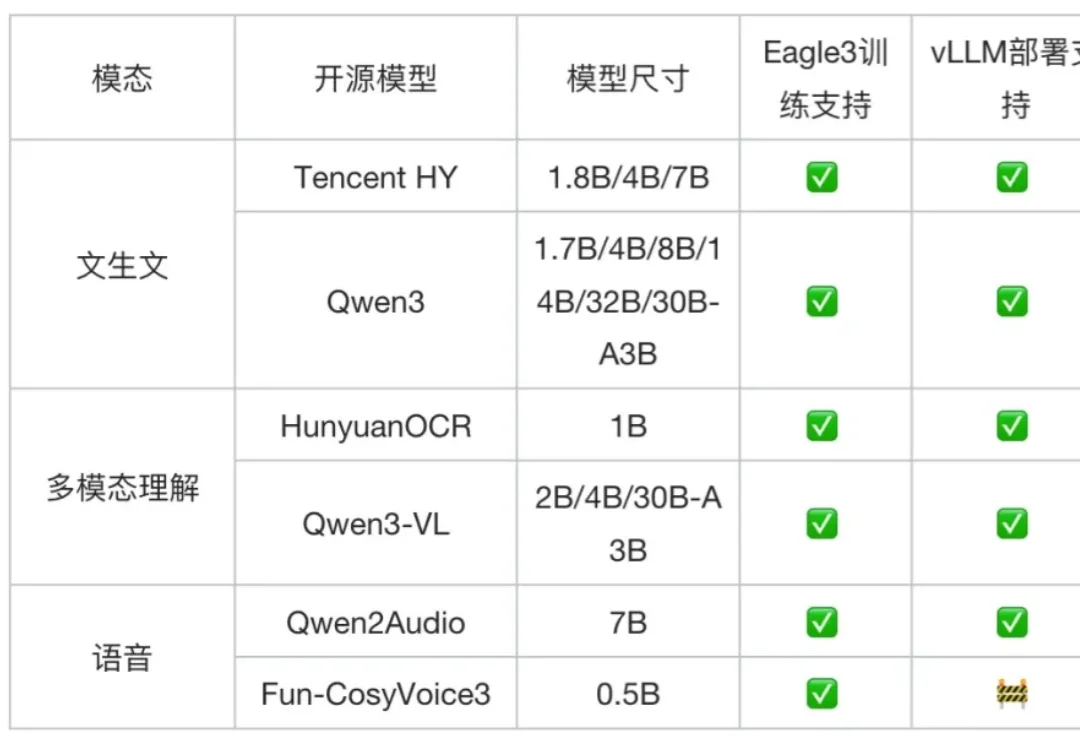
你的自教师模型还在用参考解吗?马普所联合清华大学推出d-OPSD,第一个针对扩散语言模型的在线自蒸馏学习
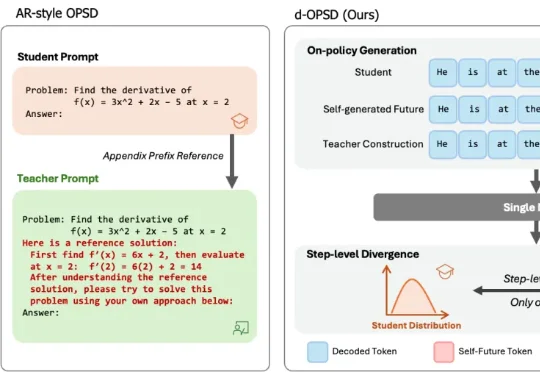
你的自教师模型还在用参考解吗?马普所联合清华大学推出d-OPSD,第一个针对扩散语言模型的在线自蒸馏学习有没有一种更为合适的 OPSD 范式?近期,清华大学和马普所等机构的研究者们联合推出的 d-OPSD,给这一问题提供了完美的答案。这是第一个针对扩散大语言模型的 OPSD 范式,无需参考解,无需额外的教师模型,只需要 RL 十分之一的训练步数,便可以达到或超出 RL 的后训练效果。
来自主题: AI技术研报
8216 点击 2026-07-10 10:41