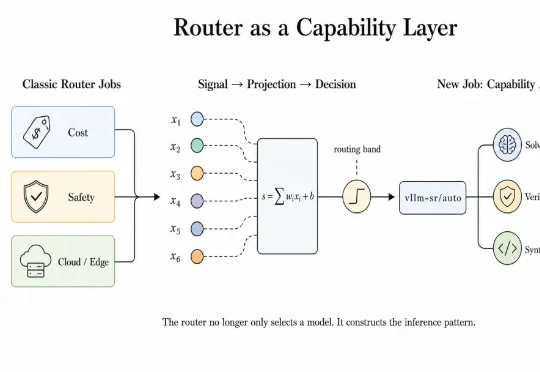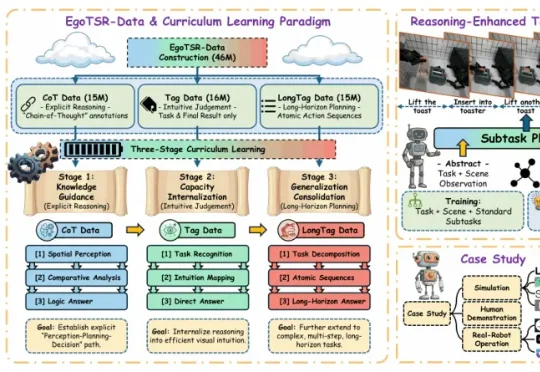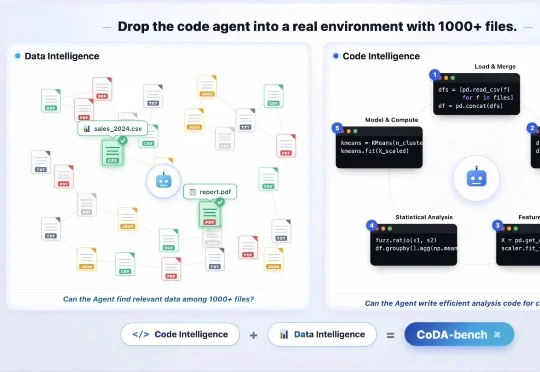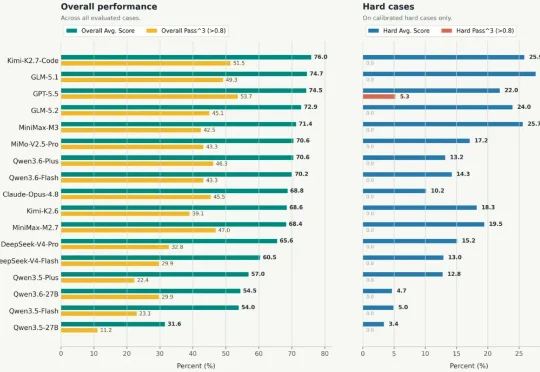
ICML 2026|如何对Multi-Agent系统进行过程评估?重新认识多智能体系统中的Orchestrator
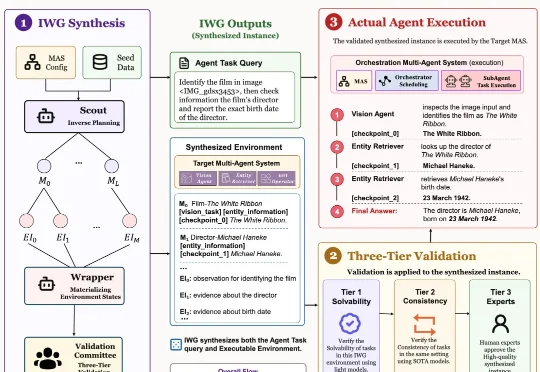
ICML 2026|如何对Multi-Agent系统进行过程评估?重新认识多智能体系统中的Orchestrator来自南京大学 NLP 实验室的 ICML 2026 论文 Recognize Your Orchestrator: An Entropy Dynamics Perspective for LLM Multi-Agent Systems 指出:在当前主流的 Orchestrator-Executor 多智能体架构中,系统失败往往并不首先来自某个执行器不会干活,
来自主题: AI技术研报
8572 点击 2026-07-06 15:48