让大模型不再过度思考!上海AI Lab后训练新范式重塑CoT,推理又快又好
让大模型不再过度思考!上海AI Lab后训练新范式重塑CoT,推理又快又好近日,上海人工智能实验室的研究团队提出了一种全新的后训练范式——RePro(Rectifying Process-level Reward)。这篇论文将推理的过程视为模型内部状态的优化过程,从而对如何重塑大模型的CoT提供了一个全新视角:
来自主题: AI技术研报
8643 点击 2025-12-21 12:35
 搜索
搜索
近日,上海人工智能实验室的研究团队提出了一种全新的后训练范式——RePro(Rectifying Process-level Reward)。这篇论文将推理的过程视为模型内部状态的优化过程,从而对如何重塑大模型的CoT提供了一个全新视角:

现有视频生成模型往往难以兼顾「运镜」与「摄影美学」的精确控制。为此,华中科技大学、南洋理工大学、商汤科技和上海人工智能实验室团队推出了 CineCtrl。作为首个统一的视频摄影控制 V2V 框架,CineCtrl 通过解耦交叉注意力机制,摆脱了多控制信号共同控制的效果耦合问题,实现了对视频相机外参轨迹与摄影效果的独立、精细、协调控制。

MiniMax 海螺视频团队「首次开源」了 VTP(Visual Tokenizer Pre-training)项目。他们同步发布了一篇相当硬核的论文,它最有意思的地方在于 3 个点:「重建做得越好,生成反而可能越差」,传统 VAE 的直觉是错的
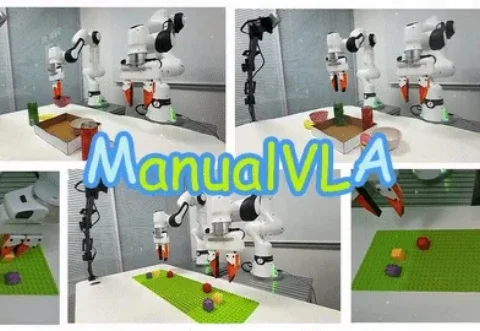
视觉–语言–动作(VLA)模型在机器人场景理解与操作上展现出较强的通用性,但在需要明确目标终态的长时序任务(如乐高搭建、物体重排)中,仍难以兼顾高层规划与精细操控。

在计算机图形学、三维视觉、虚拟人、XR 领域,SIGGRAPH 是毫无争议的 “天花板级会议”。 SIGGRAPH Asia 作为 SIGGRAPH 系列两大主会之一,每年只接收全球最顶尖研究团队的成果稿件,代表着学术与工业界的最高研究水平与最前沿技术趋势。
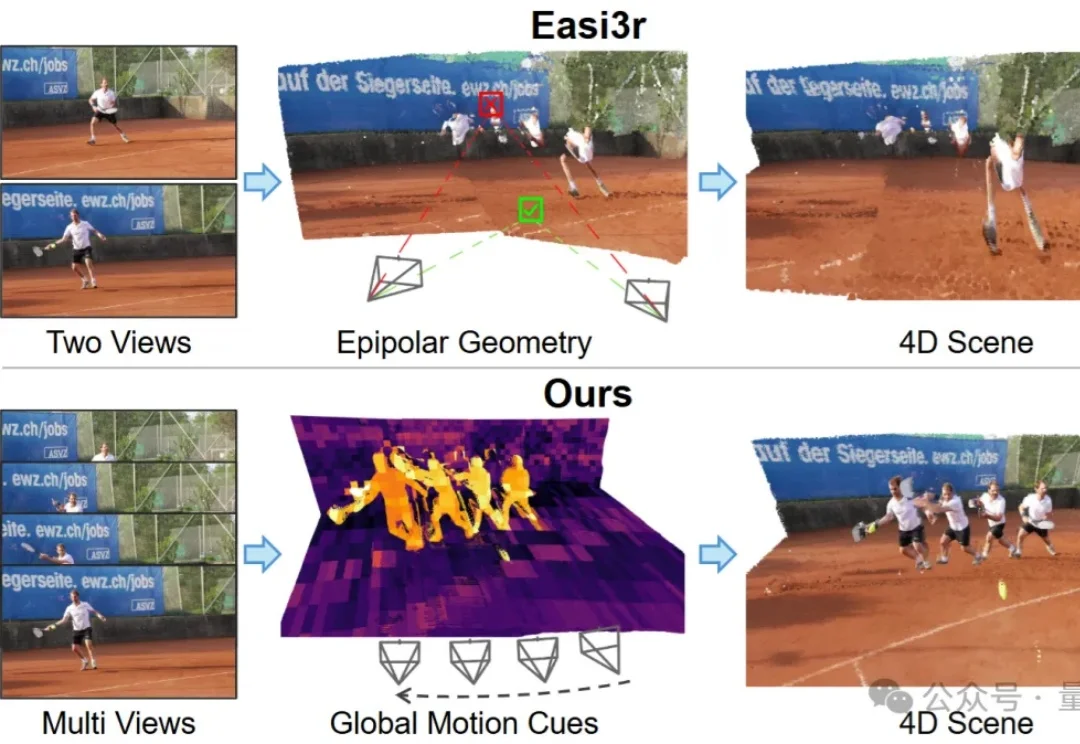
如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?
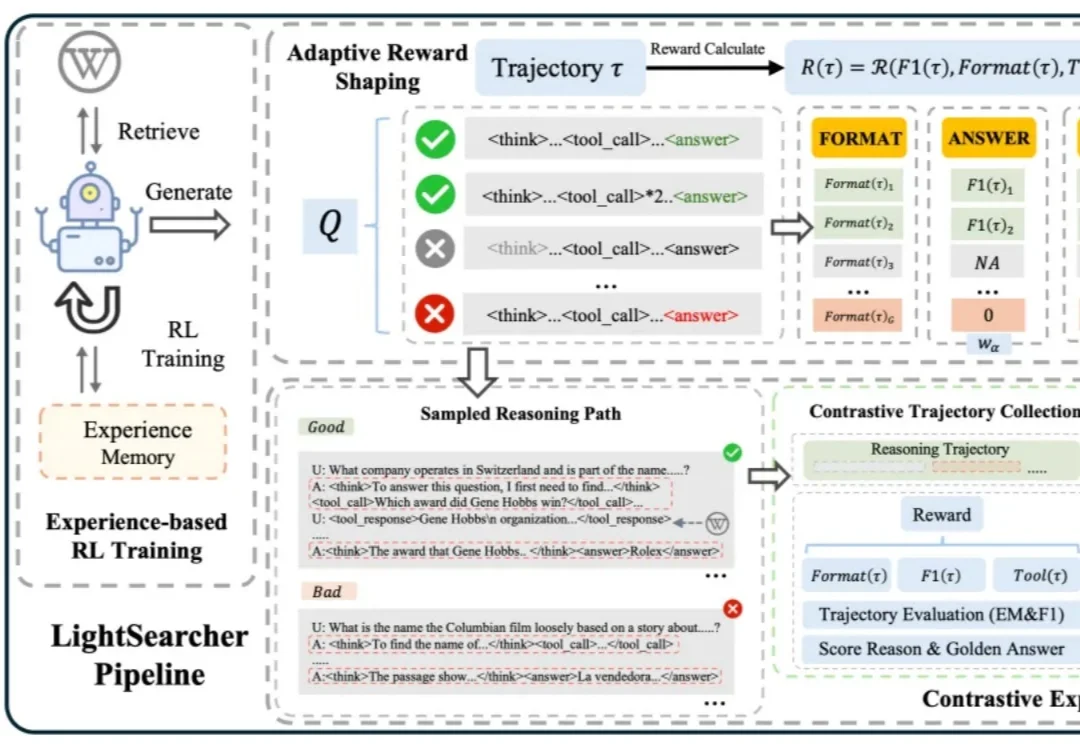
如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。
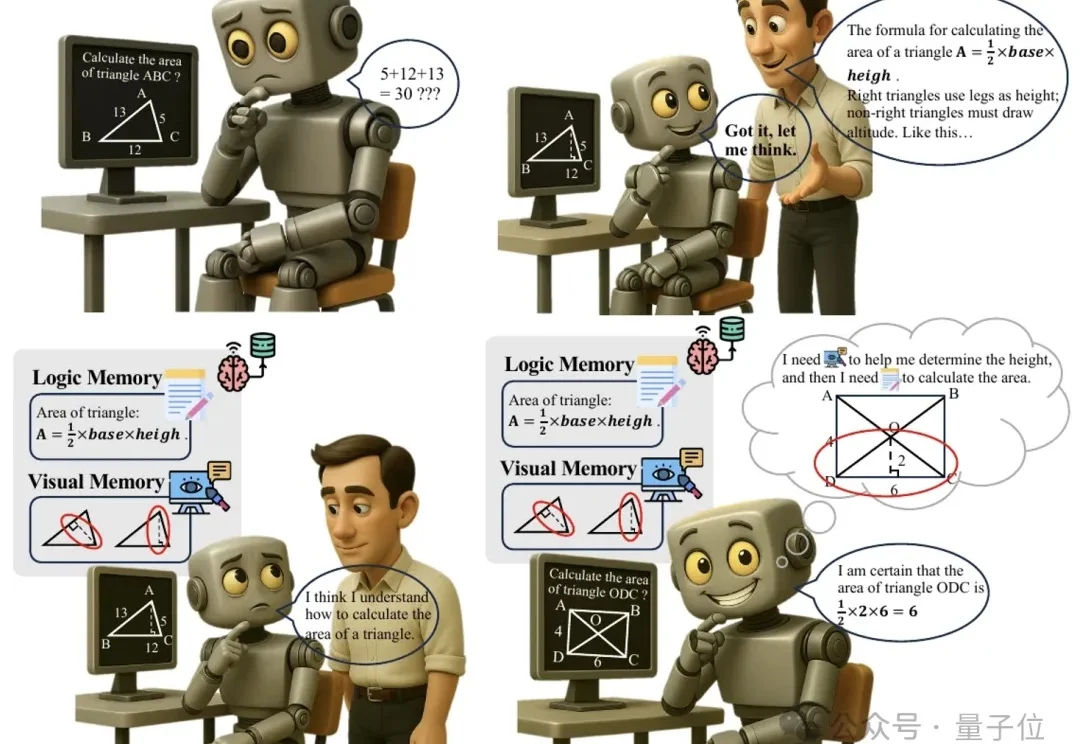
多模态推理又有新招,大模型“记不住教训”的毛病有治了。
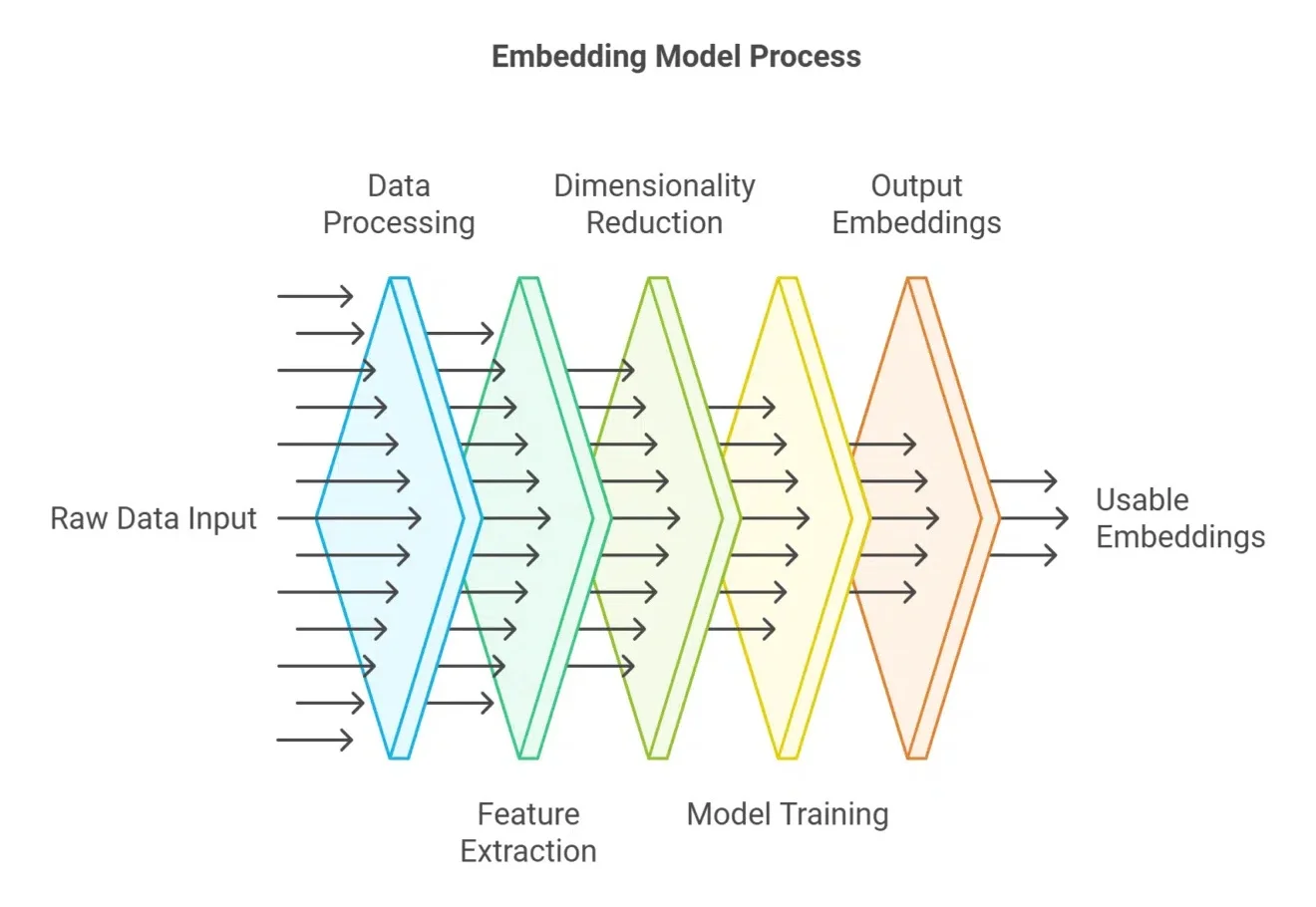
今天聊一聊我们如何做高质量rerank。

北京大学团队提出了一种新的视觉语义场景补全方法HD²-SSC,用于从多视角图像重建三维语义场景。该方法通过高维度语义解耦和高密度占用优化,解决了现有技术中二维输入与三维输出之间的维度差异,以及人工标注与真实场景密度差异的问题,从而实现更准确的语义场景补全。