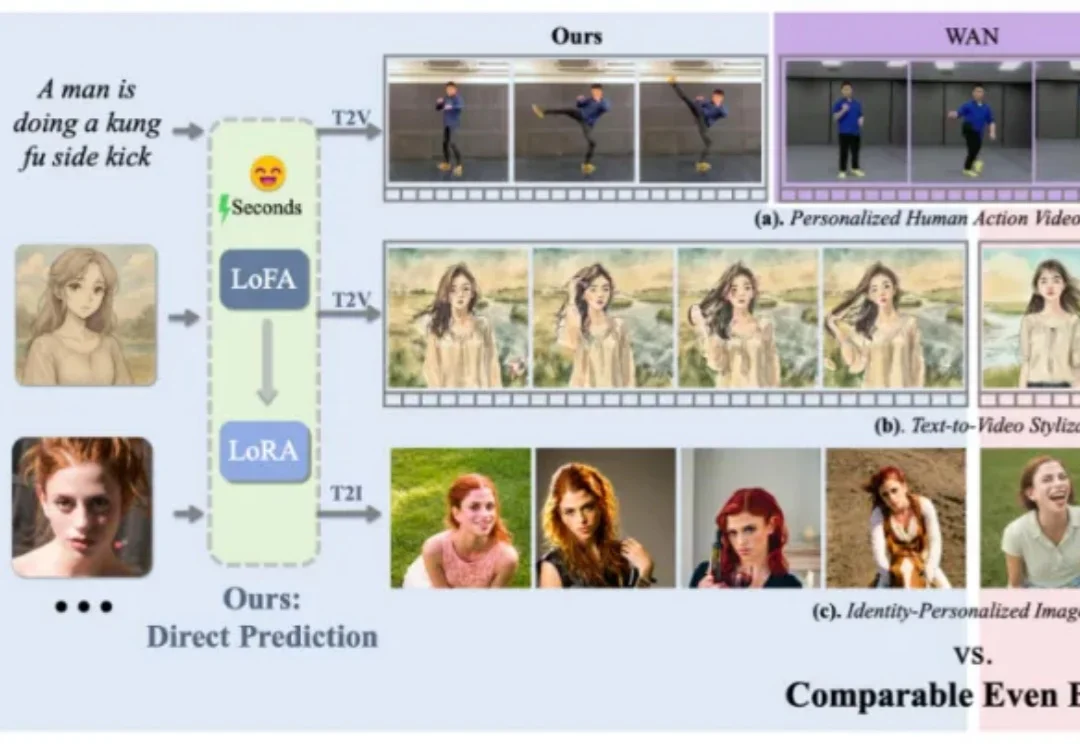
比LoRA更快更强,全新框架LoFA上线,秒级适配大模型
比LoRA更快更强,全新框架LoFA上线,秒级适配大模型在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。
来自主题: AI技术研报
7249 点击 2025-12-18 09:12
 搜索
搜索
在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。

LLM 智能体很赞,正在成为一种解决复杂难题的强大范式。
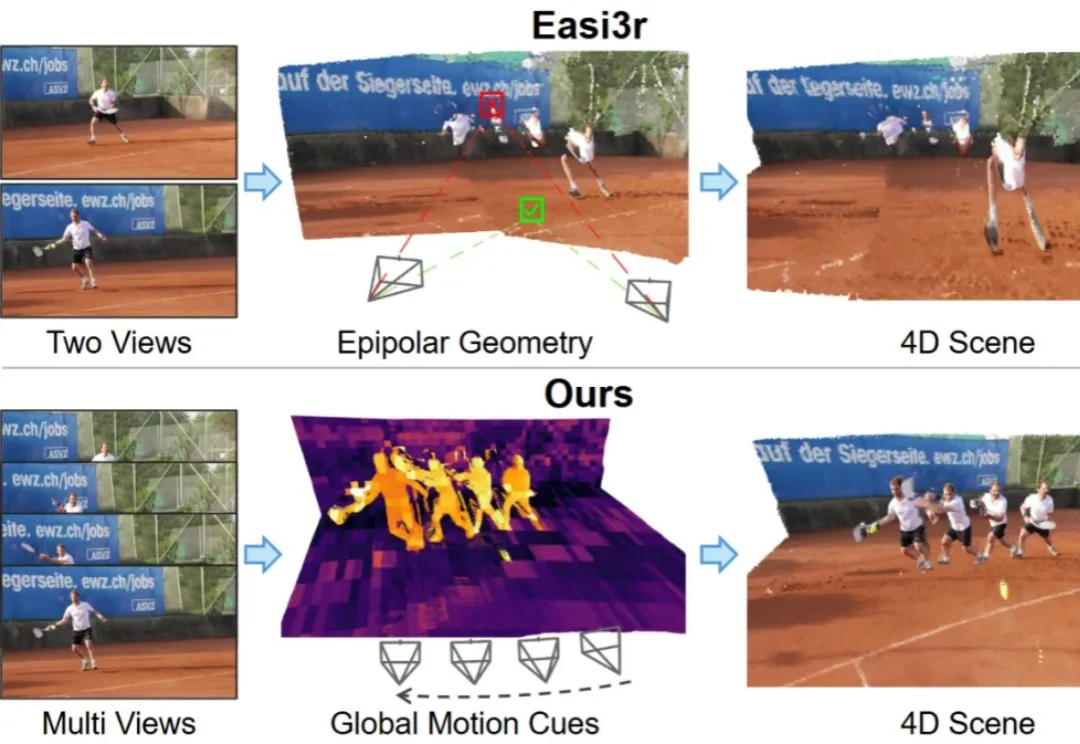
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力?

生成式模型正在成为机器人和具身智能领域的重要范式,它能够从高维视觉观测中直接生成复杂、灵活的动作策略,在操作、抓取等任务中表现亮眼。但在真实系统中,这类方法仍面临两大「硬伤」:一是训练极度依赖大规模演示数据,二是推理阶段需要大量迭代,动作生成太慢,难以实时控制。
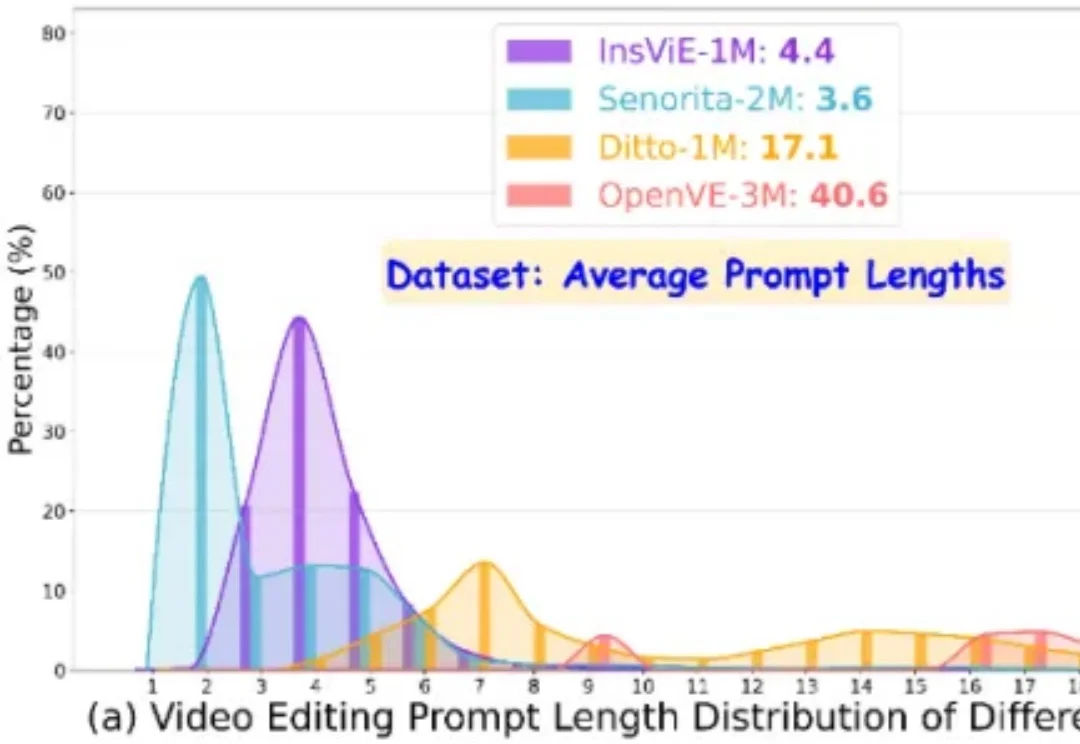
作者提出了一个大规模、高质量、多类别的指令跟随的视频编辑数据集 OpenVE-3M,共包含 3M 样本对,分为空间对齐和非空间对齐 2 大类别共 8 小类别。
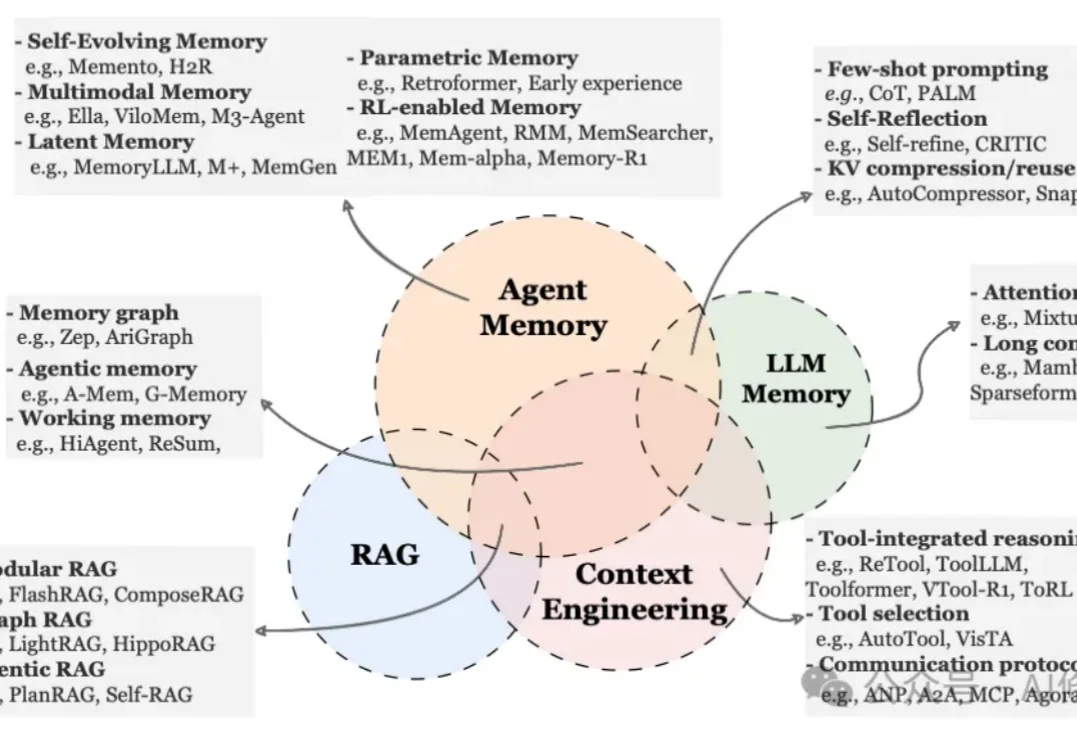
就在昨天,新加坡国立大学、中国人民大学、复旦大学等多所顶尖机构联合发布了一篇AI Agent 记忆(Memory)综述。

从 0 到上线,在OpenAI内部,安卓版 Sora经历的时间只有 28 天,而且期间只用了 2-3 名员工。

过去三年,扩散模型席卷图像生成领域。以 DiT (Diffusion Transformer) 为代表的新一代架构不断刷新图像质量的极限,让模型愈发接近真实世界的视觉规律。

南洋理工大学研究人员构建了EHRStruct基准,用于评测LLM处理结构化电子病历的能力。该基准涵盖11项核心任务,包含2200个样本,按临床场景、认知层级和功能类别组织。研究发现通用大模型优于医学专用模型,数据驱动任务表现更强,输入格式和微调方式对性能有显著影响。

近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。