
AAAI 2026 Oral | 拒绝「一刀切」!AdaMCoT:让大模型学会「看题下菜碟」,动态选择最佳思考语言
AAAI 2026 Oral | 拒绝「一刀切」!AdaMCoT:让大模型学会「看题下菜碟」,动态选择最佳思考语言多语言大模型(MLLM)在面对多语言任务时,往往面临一个选择难题:是用原来的语言直接回答,还是翻译成高资源语言去推理?
来自主题: AI技术研报
10851 点击 2025-12-15 09:53
 搜索
搜索
多语言大模型(MLLM)在面对多语言任务时,往往面临一个选择难题:是用原来的语言直接回答,还是翻译成高资源语言去推理?

在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。
想象一下,只需要一句话描述,AI 就能为你拍出一部完整的短剧?为了让这个想法变成现实,香港大学黄超教授团队开源了 ViMax 框架,并在 GitHub 获得 1.4k + 星标,专注于 Agentic Video Generation 的前沿探索。通过多智能体协作,ViMax 实现了真正的 "自编自导自演"—— 从创意构思到成片输出的完整自动化,把传统影视制作的每个环节都搬进了 AI 世界。
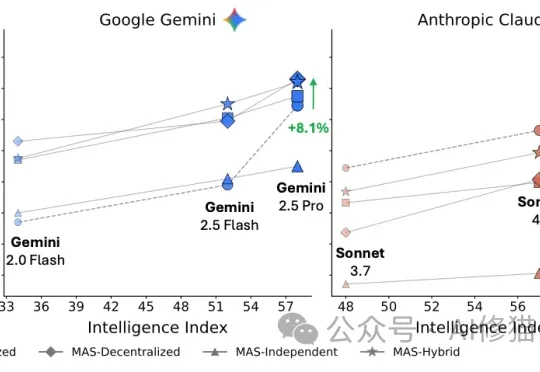
最近,来自Google Research、Google DeepMind和MIT的研究者们联合发表了一项重磅研究。结果显示:盲目增加智能体数量,在很多时候不仅没用,反而会让系统变笨、变慢、变贵。

扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临
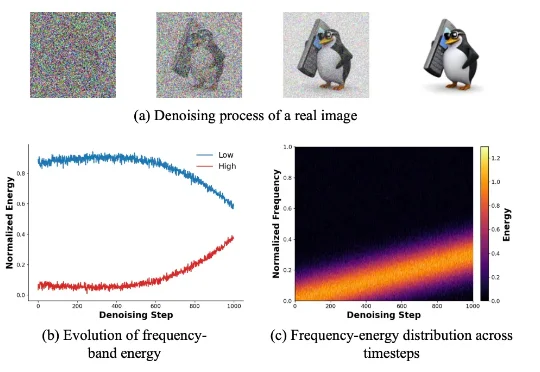
新加坡国立大学 LV Lab(颜水成团队) 联合电子科技大学、浙江大学等机构提出 FeRA (Frequency-Energy Constrained Routing) 框架:首次从频域能量的第一性原理出发,揭示了扩散去噪过程具有显著的「低频到高频」演变规律,并据此设计了动态路由机制。

智能体(Agent),即基于语言模型且具备推理、规划和行动能力的系统,正在成为现实世界 AI 应用的主导范式。

我们以为语言是语法、规则、结构。但最新的Nature研究却撕开了这层幻觉。GPT的层级结构与竟与人大脑里的「时间印记」一模一样。当浅层、中层、深层在脑中依次点亮,我们第一次看见:理解语言,也许从来不是解析,而是预测。

实现通用机器人的类人灵巧操作能力,是机器人学领域长期以来的核心挑战之一。近年来,视觉 - 语言 - 动作 (Vision-Language-Action,VLA) 模型在机器人技能学习方面展现出显著潜力,但其发展受制于一个根本性瓶颈:高质量操作数据的获取。
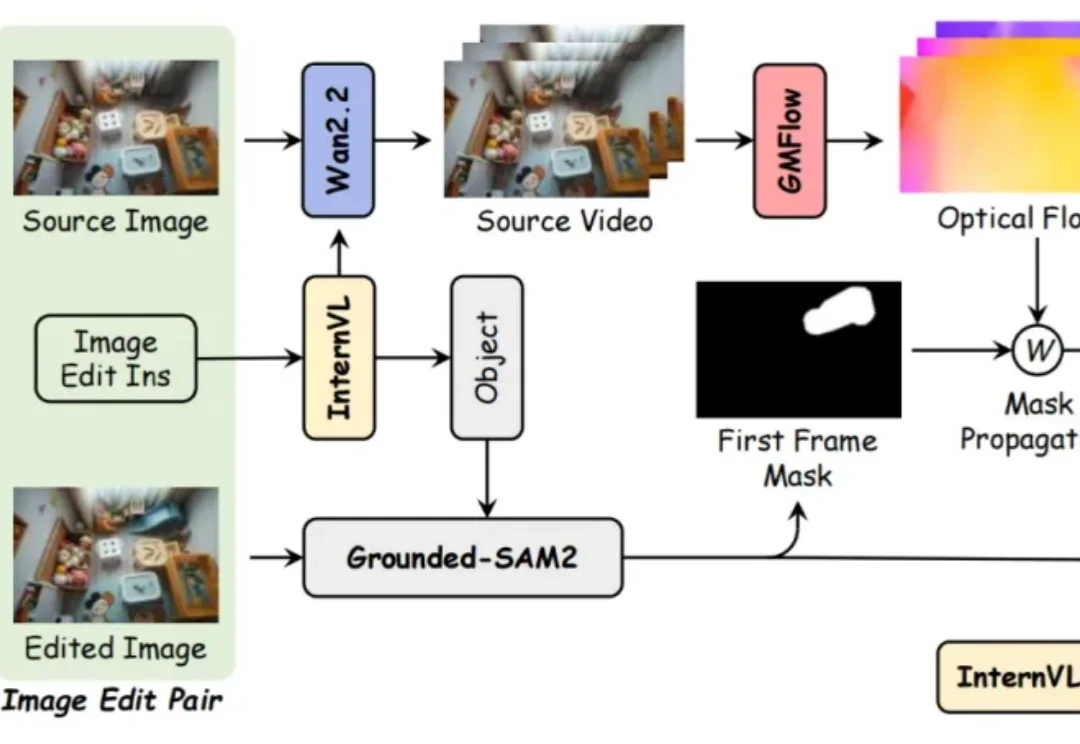
近年来,基于扩散的视频生成模型的最新进展极大地提高了视频编辑的真实感和可控性。然而,文字驱动的视频对象移除添加依然面临巨大挑战: