
别让米其林主厨削土豆!英伟达用「小脑指挥大脑」,重构AGI生产力
别让米其林主厨削土豆!英伟达用「小脑指挥大脑」,重构AGI生产力觉得大模型消耗的算力过大,英伟达推出的8B模型Orchestrator化身「拼好模」,通过组合工具降本增效,使用30%的预算,在HLE上拿下37.1%的成绩。
来自主题: AI技术研报
9717 点击 2025-12-12 08:58
 搜索
搜索
觉得大模型消耗的算力过大,英伟达推出的8B模型Orchestrator化身「拼好模」,通过组合工具降本增效,使用30%的预算,在HLE上拿下37.1%的成绩。

白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家

随着基础模型的日益成熟,AI领域的研发重心正从“训练更强的模型”转移到“构建更强的系统”。在这个新阶段,适配(Adaptation) 成为了连接通用智能与垂直应用的关键纽带。
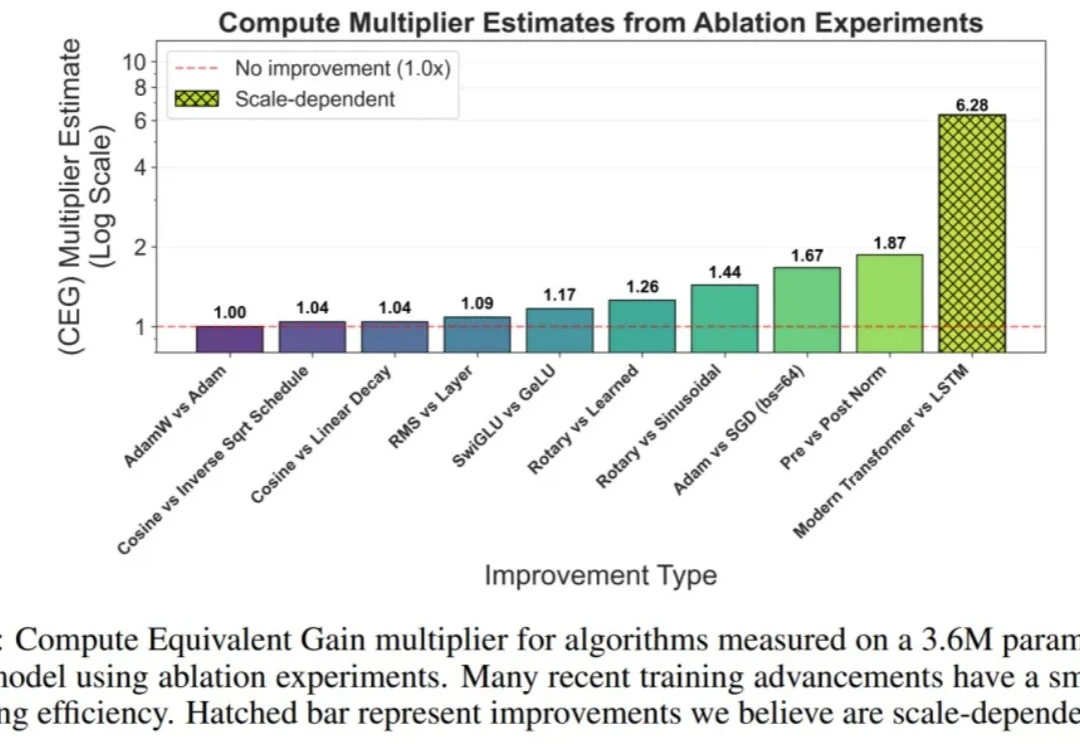
在过去十年中,AI 的进步主要由两股紧密相关的力量推动:迅速增长的计算预算,以及算法创新。
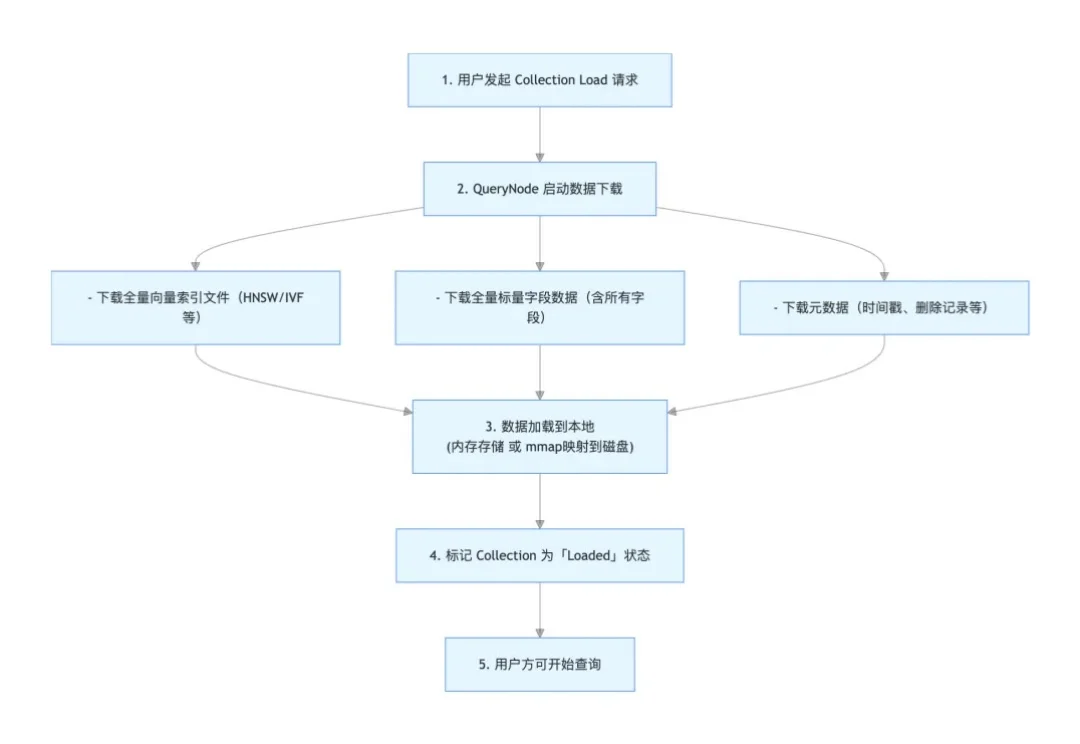
本文为Milvus Week系列第7篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。
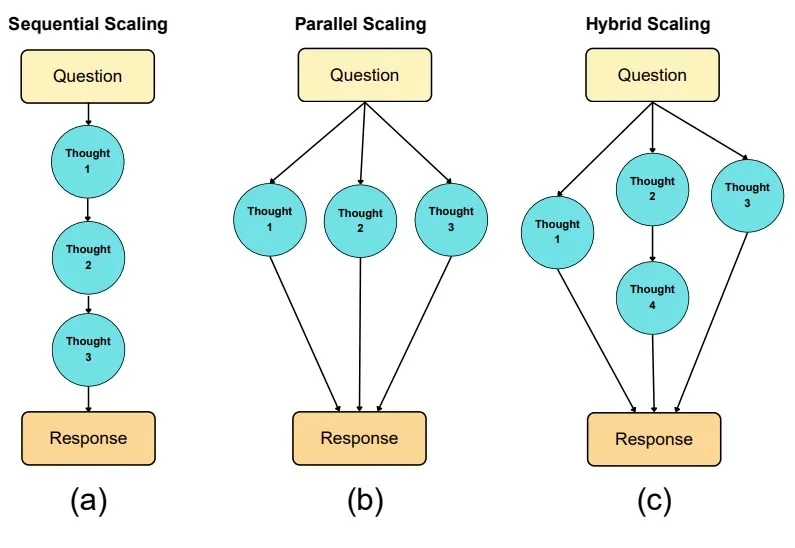
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。

Anthropic联合创始人兼首席科学官Jared Kaplan,认为在2027-2030年期间,我们将不得不做出是否允许 AI 自我进化的抉择,而允许的话很可能导致AI失控,毁灭全人类。Anthropic在迅速提升AI模型性能不断逼近AGI奇点的同时,也在同时让「9人特种部队」用1.4万字的「AI宪法」防范AI失控。
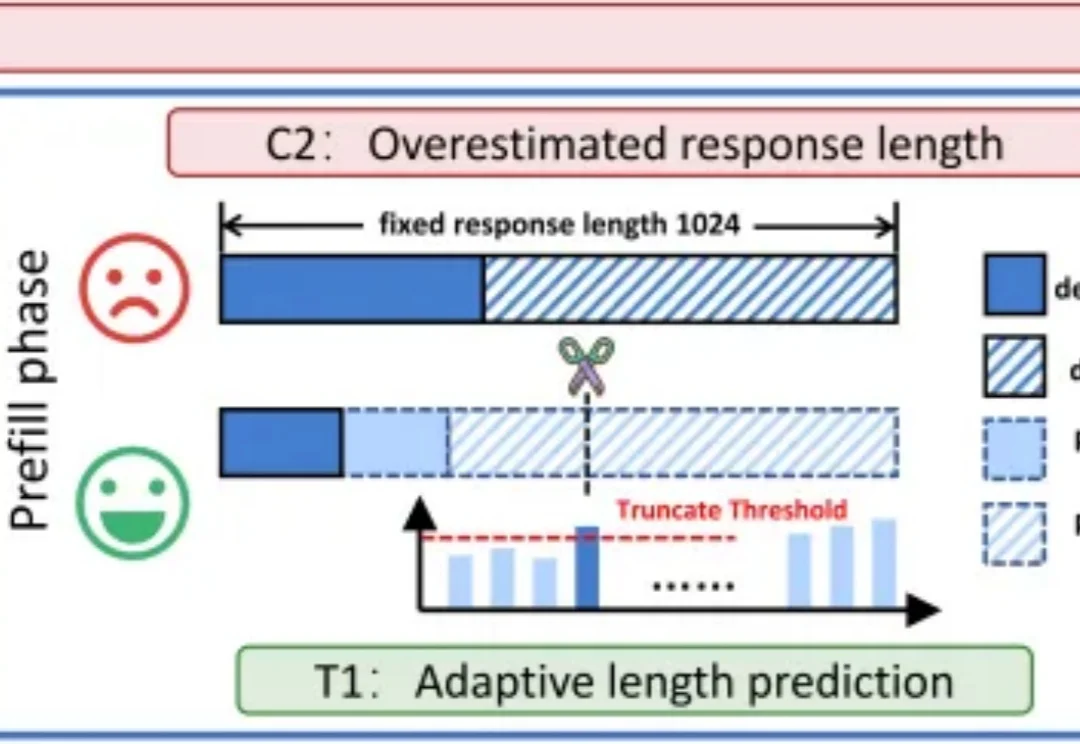
基于扩散的大语言模型 (dLLM) 凭借全局解码和双向注意力机制解锁了原生的并行解码和受控生成的潜力,最近吸引了广泛的关注。例如 Fast-dLLM 的现有推理框架通过分块半自回归解码进一步实现了 dLLM 对 KV cache 的支持,挑战了传统自回归 LLMs 的统治地位。

有关大语言模型的理论基础,可能要出现一些改变了。
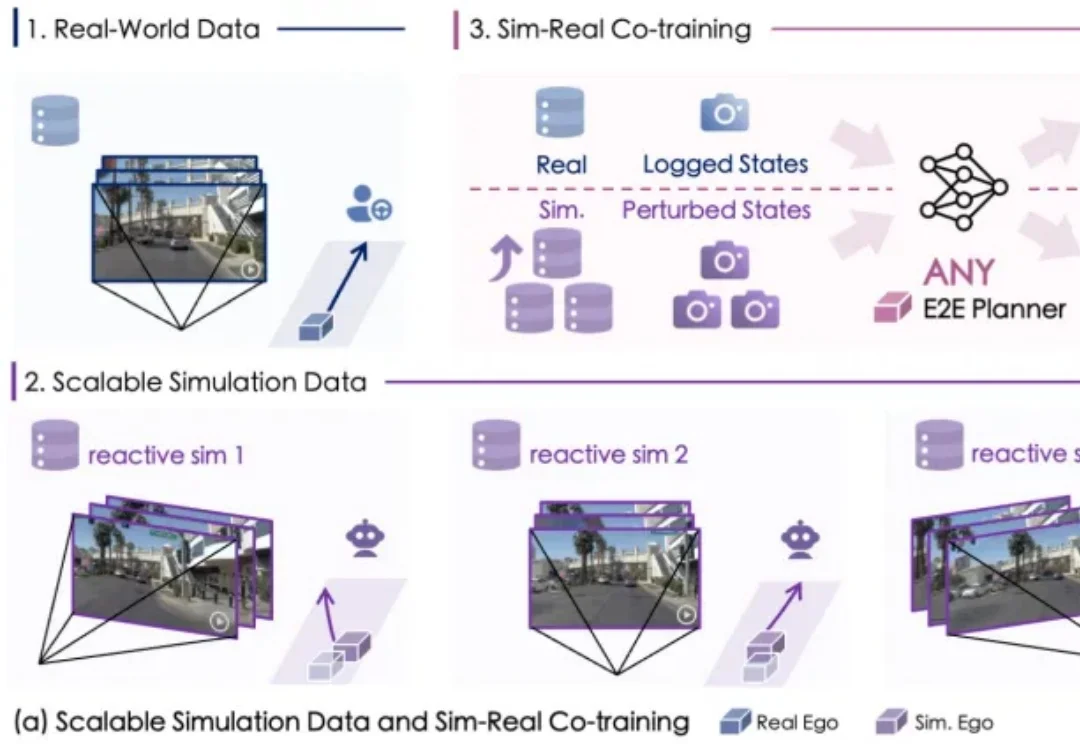
自动驾驶数据荒怎么破?