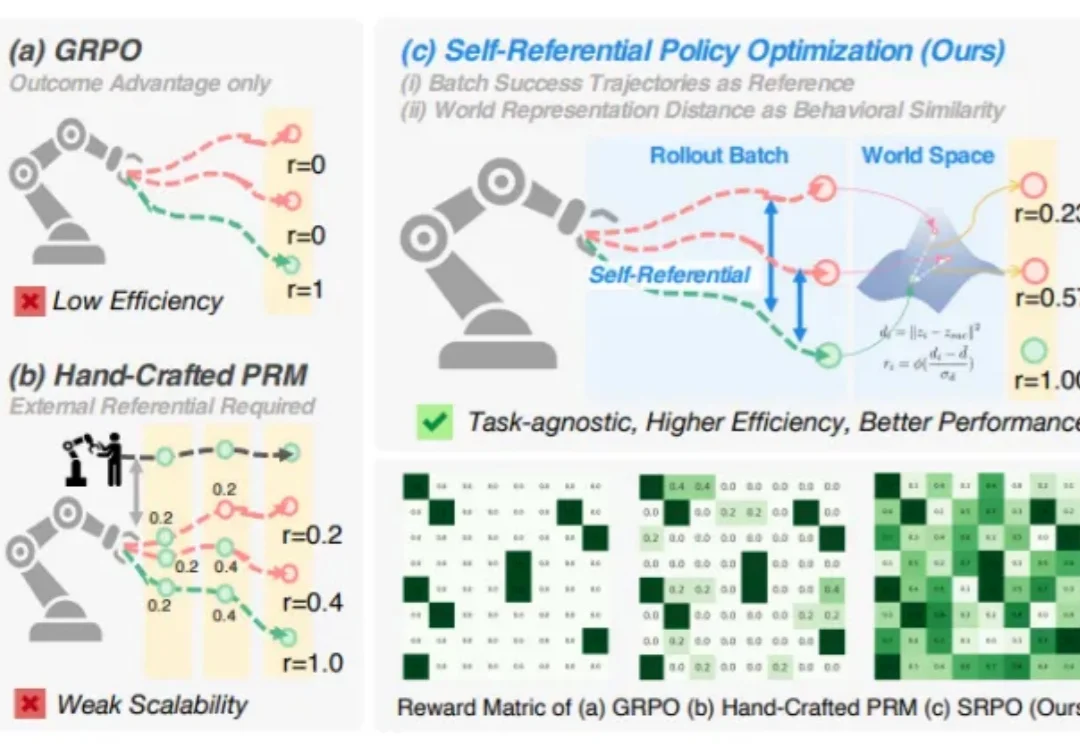
告别专家依赖,让机器人学会自我参考,仅需200步性能飙升至99.2%
告别专家依赖,让机器人学会自我参考,仅需200步性能飙升至99.2%你是否想过,机器人也能像人一样,从失败中学习,不断自我提升?
来自主题: AI技术研报
11026 点击 2025-12-11 10:08
 搜索
搜索
你是否想过,机器人也能像人一样,从失败中学习,不断自我提升?
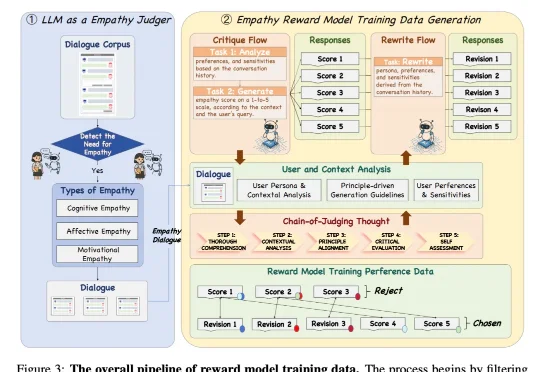
近日,来自 NatureSelect(自然选择)的研究团队 Team Echo 发布了首个情感大模型 Echo-N1,提出了一套全新的「情感模型训练方法」,成功将 RL 用在了不可验证的主观情感领域。仅 32B 参数的 Echo-N1,在多轮情感陪伴任务中胜率(Success Rate)达到 46.7%。作为对比,
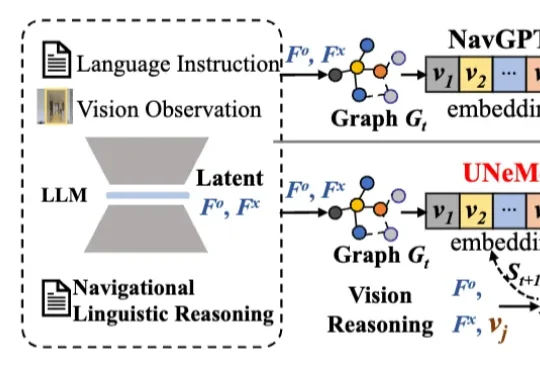
深圳大学李坚强教授团队最近联合北京理工莫斯科大学等机构,提出视觉-语言导航(VLN)新框架——UNeMo。让机器人听懂指令,精准导航再升级!
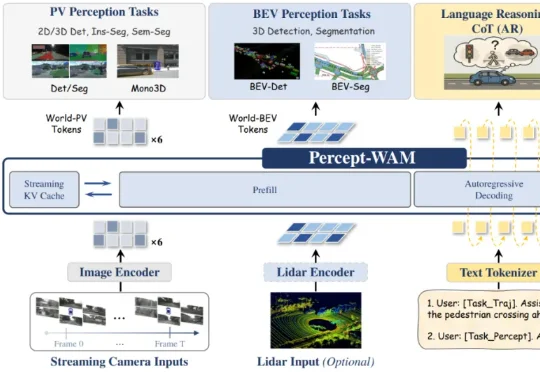
近日,来自引望智能与复旦大学的研究团队联合提出了一个面向自动驾驶的新一代大模型 ——Percept-WAM(Perception-Enhanced World–Awareness–Action Model)。该模型旨在在一个统一的大模型中,将「看见世界(Perception)」「理解世界(World–Awareness)」和「驱动车辆行动(Action)」真正打通,形成一条从感知到决策的完整链路。

近日,北京大学团队提出一个直接基于已有预训练模型进行极低比特量化的通用框架——Fairy2i。该框架通过广泛线性表示将实数模型无损转换为复数形式,再结合相位感知量化与递归残差量化,实现了在仅2比特的情况下,性能接近全精度模型的突破性进展。
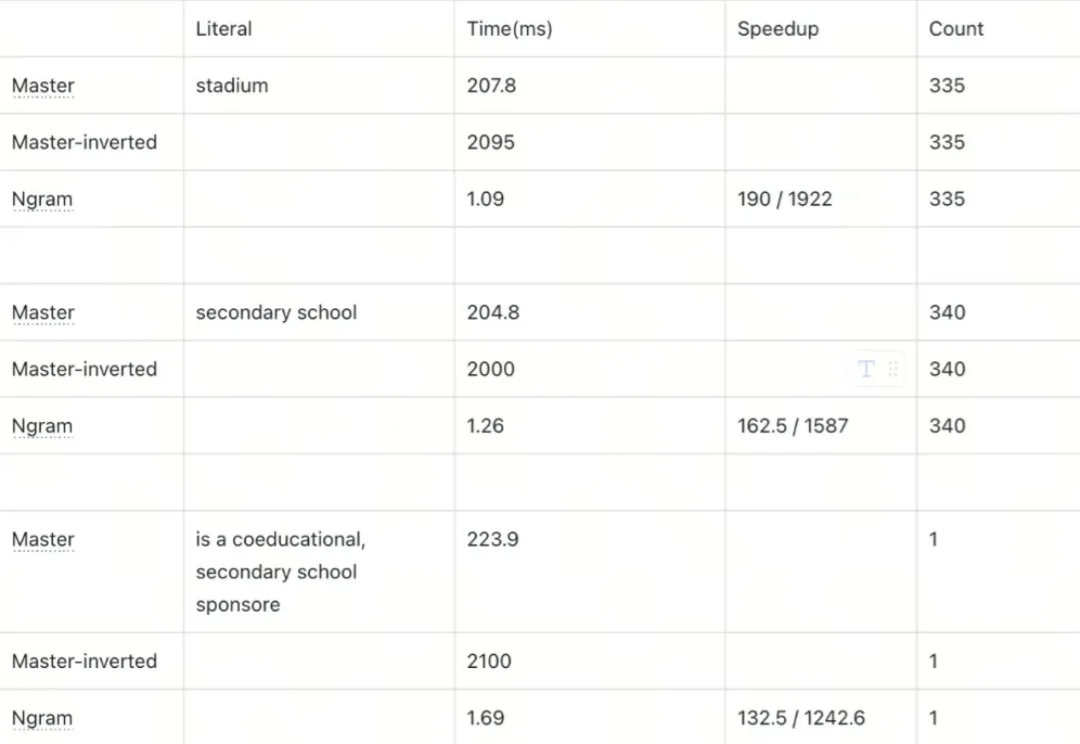
本文为Milvus Week系列第6篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。
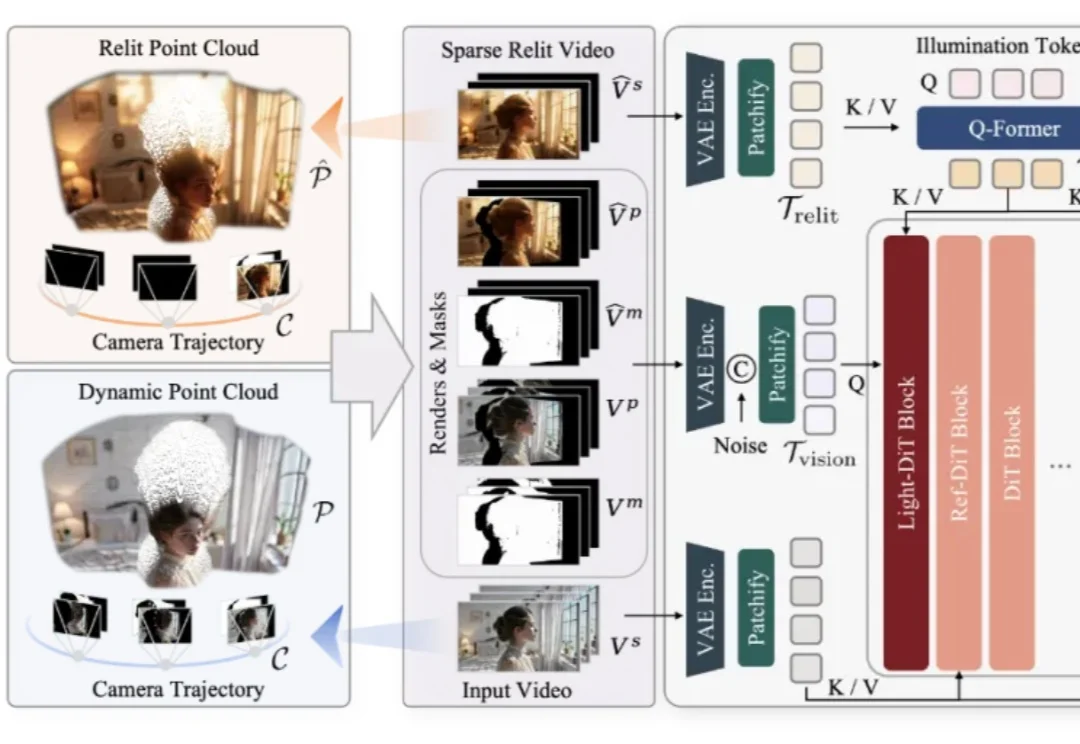
仅凭一段随手拍摄的单目视频,是否能够让镜头在空间中自由飞行,让光线随意变换,让原本固定的真实场景在全新的视角与照明条件下被再次「拍摄」?这一过去被视作科幻设想的问题,如今迎来了明确答案。
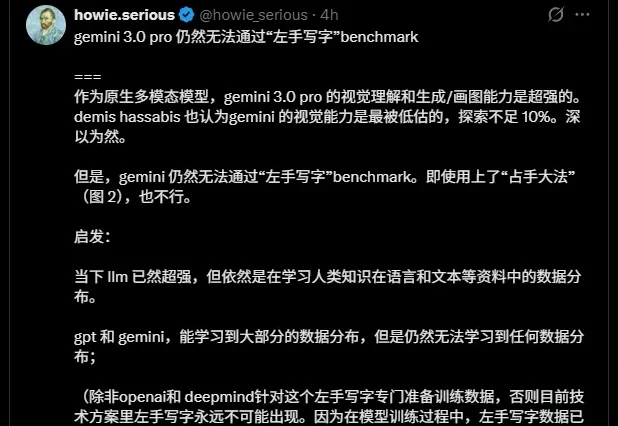
昨天刷到了一条非常有意思的推特。

假如你正在教一只小狗学习新技能。当你摇响铃铛然后给它食物,重复几次之后,只要一摇铃铛,即使没有食物,小狗也会留着口水跑过来。这就是著名的巴甫洛夫实验,它展现了生物是如何学习的。

Canvas-to-Image 是一个面向组合式图像创作的全新框架。它取消了传统「分散控制」的流程,将身份参考图、空间布局、姿态线稿等不同类型的控制信息全部整合在同一个画布中。用户在画布上放置或绘制的内容,会被模型直接解释为生成指令,简化了图像生成过程中的控制流程。