# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在具身智能(Embodied AI)的快速发展中,样本效率已成为制约智能体从实验室环境走向复杂开放世界的瓶颈问题。
不同于纯数字域的对话任务,具身任务通常涉及极度复杂的物理环境感知以及高维度的连续控制输出,这意味着智能体面临着巨大的状态-动作搜索空间,导致学习效率低下且难以收敛。
传统的无模型强化学习由于缺乏对底层物理逻辑的理解,完全依赖于海量的盲目试错来获取学习信号。
然而,在现实物理世界中,每一次交互都伴随着不可忽视的时间损耗、高昂的硬件维护成本以及潜在的安全风险,这使得动辄数亿次的交互需求变得极不现实。
为了应对这一挑战,世界模型强化学习(World Model RL)研究应运而生。
其核心范式在于通过额外学习一个能够表征环境内在转移规律的预测模型,使智能体具备在想象空间中进行自我进化的能力。
这种机制允许智能体在潜空间内进行大规模、低成本的轨迹预演与策略优化,从而显著降低对环境交互的依赖,加速具身智能机器人的落地应用。

在世界模型强化学习领域,如何将“多看几步”的在线规划(Online Planning)与“博采众长”的离轨策略学习(Off-Policy)机制完美结合?
清华大学与加州伯克利的研究团队联合提出了BOOM框架,通过创新的“自举循环”机制,实现了高维控制任务下的性能新突破!
在线规划能够让智能体在环境交互前通过模拟未来轨迹来优化动作,显著提升强化学习的样本效率。
然而,当在线规划与策略学习相遇时,存在一个根本性的矛盾:角色偏差(Actor Divergence),即规划器和策略是两个不同的角色。
这造成了两大痛点:
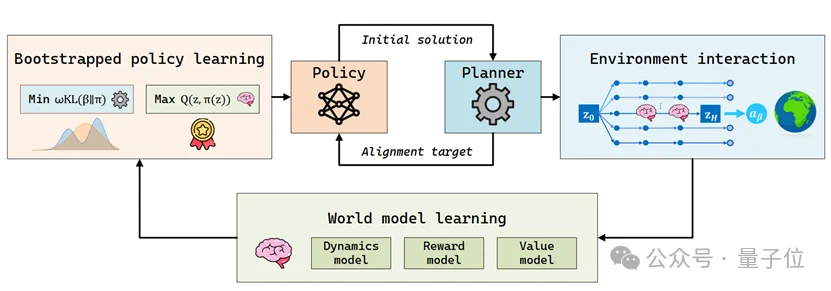
为了解决这一难题,研究团队提出了BOOM(Bootstrap Off-policy with World Model)框架。其核心思想是构建一个自举循环(Bootstrap Loop):
由于在线规划器的动作分布通常是不可显式表达的非参数化分布(Non-parametric),其似然度(Likelihood)难以计算。BOOM采用了一种无似然对齐损失,无需知道规划器的具体概率分布,即可实现策略与规划动作的高效对齐,缓解角色偏差。
并非所有的规划动作都是完美的。BOOM引入了软Q加权机制,根据Q函数动态调整权重,引导策略优先学习那些高价值、高回报的优质经验,从而在处理历史数据波动的同时加速学习。
研究团队在DeepMind Control Suite(DMC)和挑战性极高的Humanoid-Bench(H-Bench)上进行了全面评估。
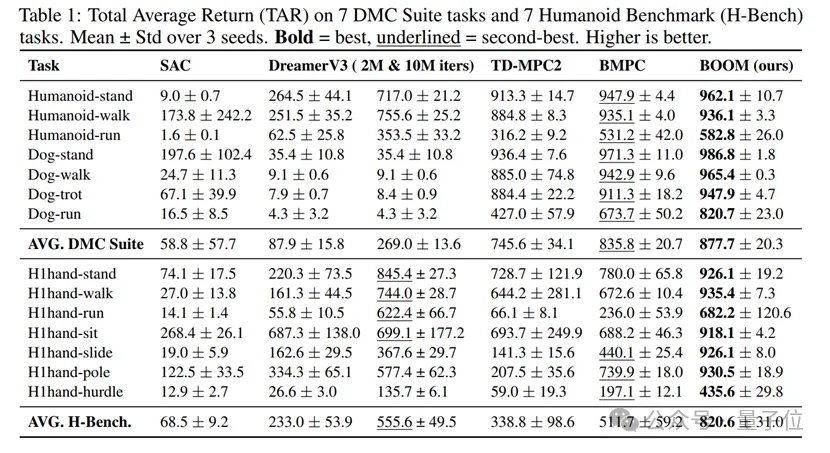
卓越性能:在Humanoid和Dog等14个高维任务中,BOOM的最终表现和训练稳定性均达到了State-of-the-art(SOTA)水平。
大幅领先:在DMC任务中,BOOM超过了TD-MPC2(+17.7%)和BMPC(+5.0%)。在Humanoid-Bench任务上,更是比DreamerV3提升了47.7%,比BMPC提升了60.5% 。
复杂环境适应性:即使是在需要滑行(H1hand-slide)或跨障碍(H1hand-hurdle)的复杂任务中,BOOM依然展现出了极强的控制鲁棒性,部分任务性能提升甚至超过100% 。
BOOM框架通过巧妙的自举对齐机制,消弥了世界模型规划与离轨策略强化学习之间的鸿沟。
这不仅为高维连续控制任务提供了一套高效、稳定的解决方案,也为未来具身智能(Embodied AI)在复杂现实环境中的落地提供了坚实的理论与实验支撑。
论文题目:Bootstrap Off-policy with World Model
论文链接:https://openreview.net/forum?id=zNqDCSokDR
作者单位:清华大学、加州伯克利
录取会议:NeurIPS 2025
项目代码:https://github.com/molumitu/BOOM_MBRL
文章来自于“量子位”,作者 “BOOM团队”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
