# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果你最近关注了 GitHub,可能会注意到一个有趣的现象:
YOLO 的版本号,直接从 11 跳到了 26。
起初我以为是分支管理出了 bug,但看完技术报告,我收回这个想法, 确实是有意为之的宣告。YOLO26 的“26”,代表着与 2026 年同步,这么大的版本号跨越,也必然代表这是一次重大升级。
官方给这次升级的定位是——
标志着计算机视觉模型在真实世界系统中的训练方式、部署方式以及规模化路径发生了根本性的转变。
用 Ultralytics 创始人 Glenn Jocher 在 YOLO Vision 2025 大会上的话说:
“我们希望 AI 不再只停留在云端,而是下沉到边缘设备、你的手机、车辆以及低功耗系统中。”
YOLO26 正是这一愿景的技术实现:生产级、以边缘端为核心的计算机视觉新标准。
在所有人都在追逐 GPT、Claude 的时代,为什么还要关注一个目标检测模型?
这两年 CV 圈确实被大模型抢尽风头,GPT-4V 能看图写代码,Gemini 能一口气吞下几小时视频,SAM 号称分割一切,很多人以为传统 CV 任务已经过时。
但现实世界里:
原因也很简单,算一笔账你就懂了。
假设用大模型做流水线质检,调用一次 API 耗时 0.1 秒、成本 1 美分。一条产线每秒过 10 个件、一天跑 8 小时:
推理费用就是:10×3600×8×0.01=2880 美元/天 10×3600×8×0.01=2880 美元/天
折合人民币两万。请问哪个老板顶得住?
而 YOLO26 呢?
这就是大模型与 YOLO 的根本差异。
大模型解决的是“能力上限"——它能理解复杂语义,告诉你:这张图里有一只忧郁的橘猫坐在复古天鹅绒沙发上。YOLO 解决的是“工程下限”——在最苛刻的条件下,用最快的速度、最低的成本,把活儿干完。
这也是为什么 Ultralytics YOLO 能拿下 12.3 万 GitHub Stars、2.08 亿 + Python 包下载量、日使用量接近 25 亿次的原因——它解决的是真实世界里“省钱、高效、能落地”的问题。

那这次的 YOLOv26 有什么新东西?
说实话,看完文档我挺惊讶,基本上做了一次“断舍离”式的架构重构。
第一,移除 NMS,实现端到端推理。
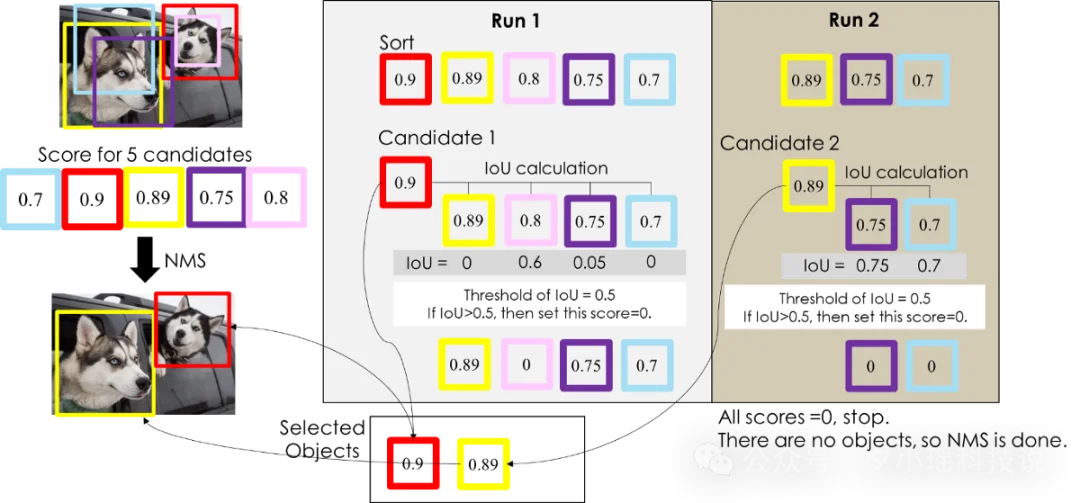
咱们搞算法的都知道,以前的模型( 比如 YOLOv8/11)在“看”图时,会生成成千上万个重叠的候选框,然后用非极大值抑制(NMS)过滤掉多余的框。
这个过程就像是高速公路的收费站:无论你的模型推理速度有多快,到了收费站(NMS 后处理)都得排队缴费,整体速度立马就下来了。
YOLO26 直接拆掉了这个收费站。
它采用了全新的端到端无 NMS 架构,模型输出的就是最终结果,不再需要复杂的后处理。这一改变带来的效果是立竿见影的:
第二,移除 DFL,解除隐形围栏。
以前的 YOLO 喜欢用 分布焦点损失(DFL) 来提升精度。但 DFL 像一道隐形围栏,限制了边界框的回归范围。 这就导致模型在检测 超大目标(比如贴着摄像头的大卡车)时,经常“束手束脚”,框画不全。
YOLO26 移除 DFL 后:
听到这儿,有同学可能要问了:
"博主,去掉了 DFL,那小目标检测会不会变差啊?"
别急,Ultralytics 显然想到了这点。他们设计了 STAL(Small Target Alignment Loss):专门增强模型对小目标和远距离目标的感知能力。
在航拍无人机找地面行人、工业相机检测微小裂痕这类场景下,STAL 的加持让 YOLO26 比前辈们稳得多。
最后,还有一个新玩意值得一提—MuSGD 优化器。
它融合了传统 SGD 的稳定性和大模型训练的一些优化思路,能让模型收敛得更快、更稳,尤其在处理复杂数据集时,调参的头疼程度会下降不少。

第三,拆掉云端依赖,CPU 性能暴涨 43%。
传统观念里,深度学习模型吃 GPU。但 YOLO26 专为边缘计算优化,实现了一个惊人的数据:CPU 推理速度提升高达 43%
这意味着什么?
YOLO26 还做了一系列对特定任务的优化。
YOLO26 继续沿用了 n(Nano)、s(Small)、m(Medium)、l(Large)、x(Extra Large)五种尺寸的家族设计,能够支持根据部署的客观条件来完成多种任务。
与 YOLO11 相比,YOLO26 的 Nano 版本在 CPU 推理场景下最高可实现 43% 的性能提升,成为目前边缘端和基于 CPU 部署场景中速度与精度兼顾的领先目标检测模型之一。
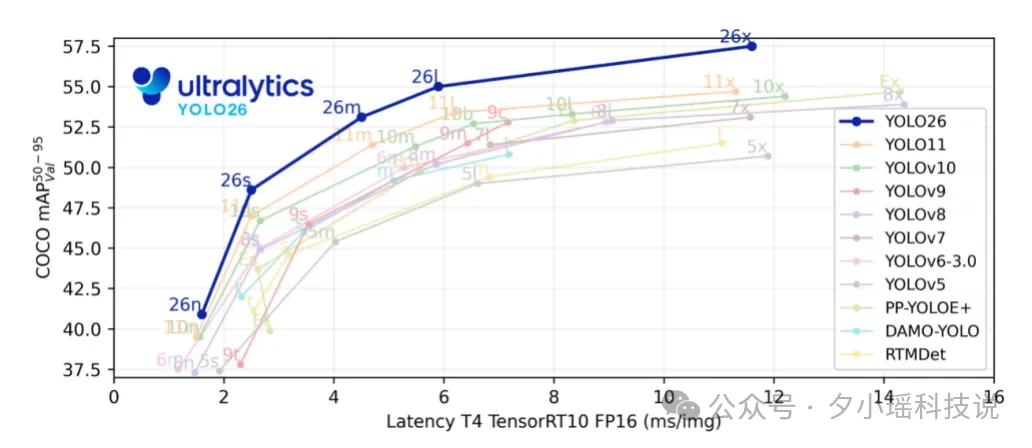
更重要的是,这些性能提升不需要硬件升级——YOLO26 可以在现有硬件上高效运行,包括 CPU、边缘加速器以及各类嵌入式设备。
我也第一时间上手盘了一下,体验非常丝滑。目前有两种主流玩法:
方式一:Ultralytics 云平台(适合生产部署)
官方提供了一站式平台,把训练、微调、导出、部署全包圆了。
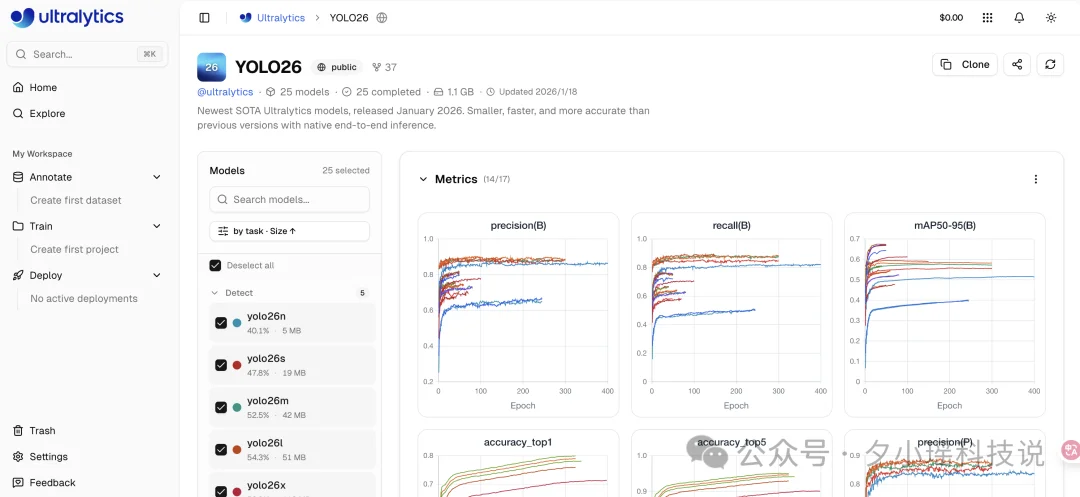
传送门:https://bit.ly/3LIom24
(Ps:也可以点击阅读原文)
在平台上可以:
我试着传了一个“玩具数据集”上去,点击训练。好家伙,不到 20 秒就跑完了!
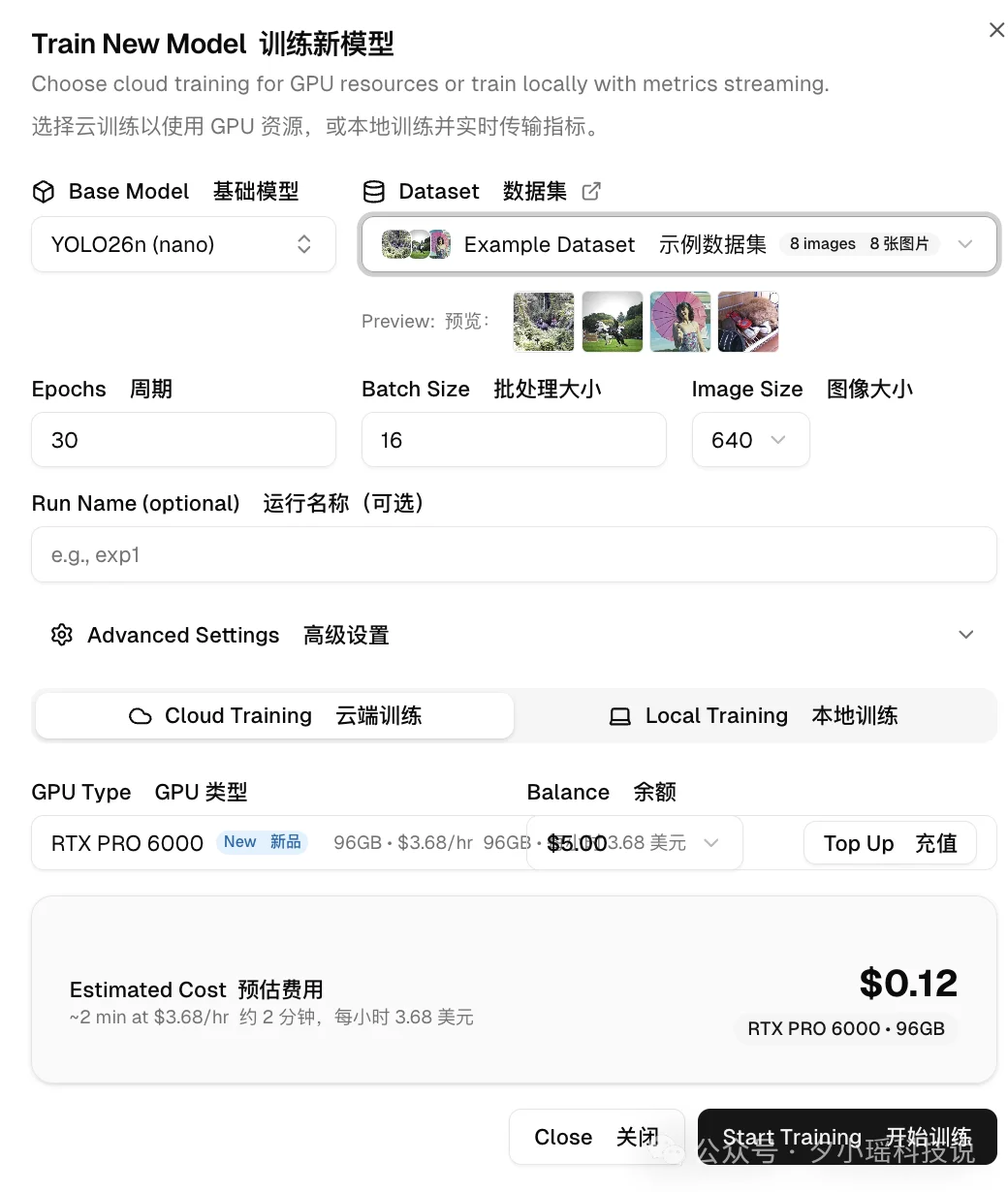
而且训练过程中的 loss 曲线、各项指标看得清清楚楚。 对于不想折腾环境、或者需要团队协作的朋友:
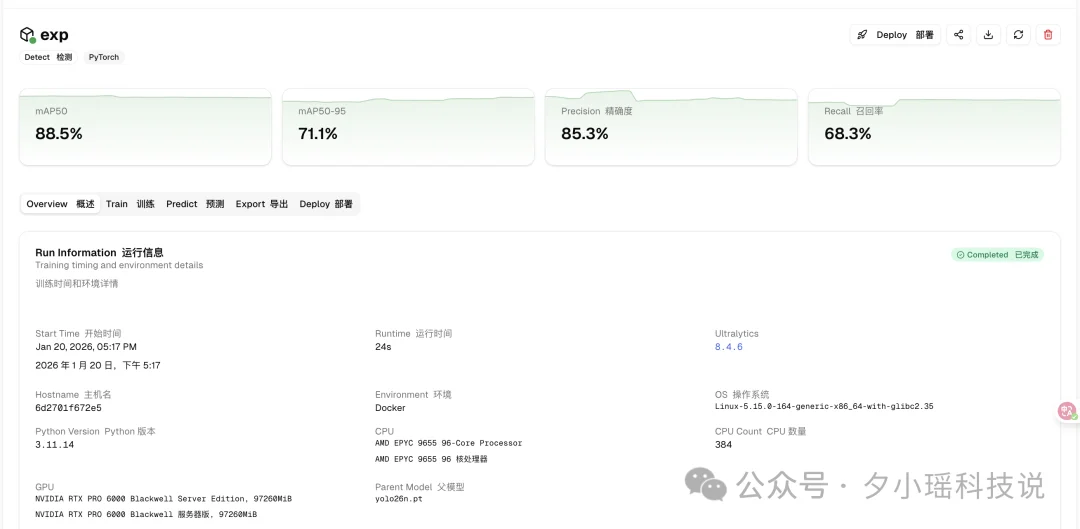
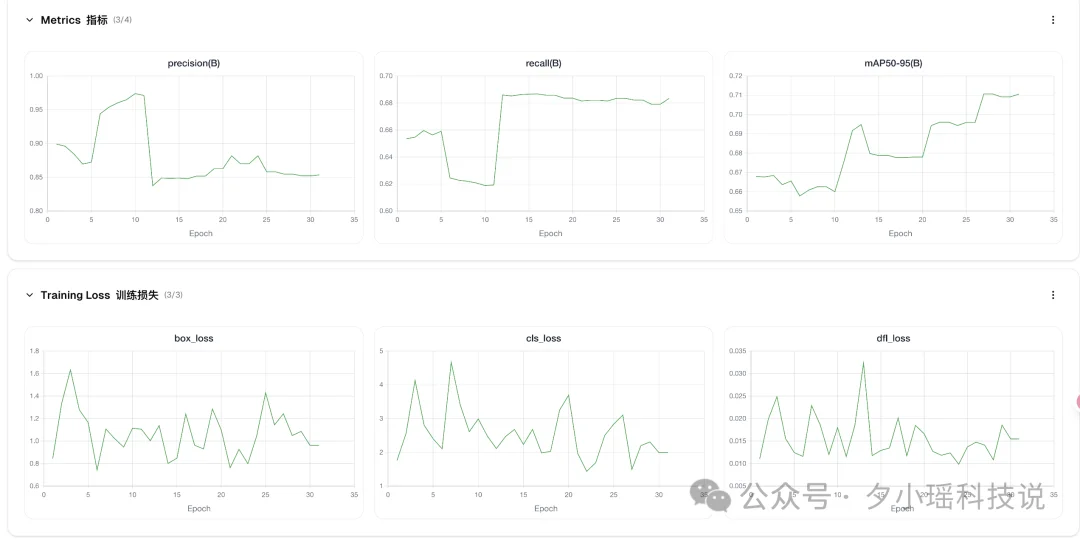
ps:现在好像有活动,只要注册就给 5 美刀用于训练,反正我测的时候没花钱。
方式二:本地开源部署
YOLO26 完全开源,可以通过 Ultralytics Python 包使用,老规矩,pip 一把梭:
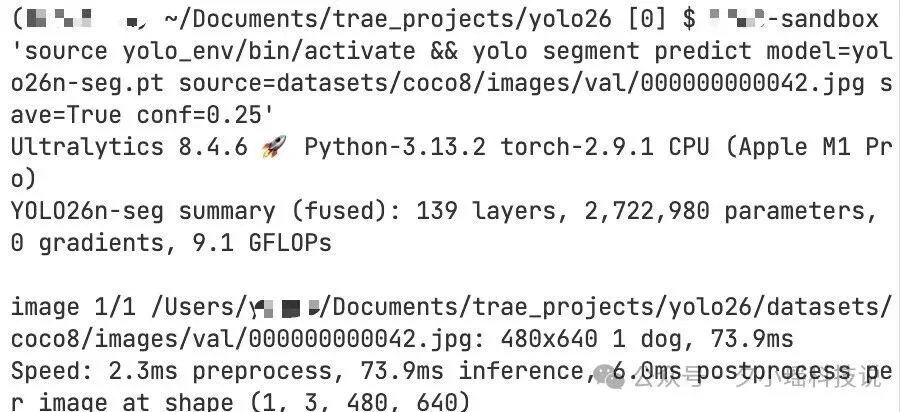
pip install ultralytics
from ultralytics import YOLO
model = YOLO("yolo26n.pt") # 自动下载预训练权重_
results = model("bus.jpg") # 一行推理_
教程传送门: https://docs.ultralytics.com/models/yolo26/
如果你想训练自己的模型,也就是几行代码的事。
训练:
from ultralytics import YOLO
# Load a model
model = YOLO("yolo26n.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="african-wildlife.yaml", epochs=100, imgsz=640)
推理:
model = YOLO("yolo26n.pt")
results = model.train(
data="coco.yaml", # 数据集配置文件
epochs=100, # 训练轮次
imgsz=640, # 图像大小
batch=16 # 批次大小
)
# 训练 YOLO26 分割模型
model = YOLO("yolo26n-seg.pt")
results = model.train(
data="coco.yaml", # 数据集配置文件
epochs=100, # 训练轮次
imgsz=640, # 图像大小
batch=16 # 批次大小
)
训练起来非常流畅!
哪怕是不太懂 CV 的新手,也能在几分钟内跑通一个自己的目标检测模型。而且 YOLO26n 这种 Nano 级别的模型,在笔记本 CPU 上跑起来简直飞快。
总之,云端有全家桶,本地有自由度,丰俭由人。
最后必须友情提醒一下家人们,Ultralytics 提供了两种授权方案,大家对号入座,别踩坑:
1.AGPL-3.0 开源许可证
2.企业级商业许可证
这两年大模型太火了,火到很多人忘了一个基本事实——99% 的 AI 应用场景,根本用不起大模型。
一个工厂的质检摄像头,不需要理解莎士比亚;一台送餐机器人,不需要和你聊人生哲学。它们只需要又快又准地完成一件事:看懂眼前这一帧画面,然后做出反应。
这就是 YOLO 系列存在的意义,不是所有 AI 都要追求"大而全",有时候"小而美"才是真正的生产力。
作为一名 AI 科技的观察者,我其实很看好一种未来的“师生模型”范式:
比如,我们用云端那个牛逼但昂贵的 GPT 去自动标注海量数据,教出轻量级、反应快的 YOLO26,然后把学生派到世界各地的摄像头里去干活。
云端有智慧,边缘有速度。
家人们,你们怎么看 ~ 欢迎评论区和我们一起讨论!
文章来自于“夕小瑶科技说”,作者 “夕小瑶编辑部”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
