# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这不是一个普通的Skill,而是一把“把经验变成Skill”的工具:Claudeception是一个Meta-Skill,即专门用来“生产技能”的技能。

你写代码时最浪费的不是敲键盘,而是重复付出“第一次解决问题”的成本:同样的依赖冲突、同样的构建错误、同样的怪异边缘case,每隔几周就会再来一次。
Claudeception的想法很直接:既然Claude Code能帮你把问题解决,那它也应该把这次解决过程里真正有价值的经验,自动提炼成一条可复用的Skill,下次遇到相似场景直接命中并复用。它把“会话内的即时帮忙”变成“会话外的持续增益”,让你的工具链拥有一种工程化的连续学习能力。
Claudeception并非凭空而生,其设计灵感直接源于Agent领域关于‘技能库’(Skill Libraries)的一系列经典学术研究。项目作者在开发文档中坦言,其核心理念很简单:具备持久化学习能力的Agent,表现远优于每次都从零开始的Agent。它并未试图发明新的理论,而是将学术界关于‘具身智能’、‘反思机制’和‘元技能’的前沿探索,务实地转化为了一套面向软件工程的落地工具。

Voyager是第一个在大规模开放世界(Minecraft)中实现终身学习的Agent。它最革命性的贡献在于证明了"Code as Policies"(代码即策略的可行性。
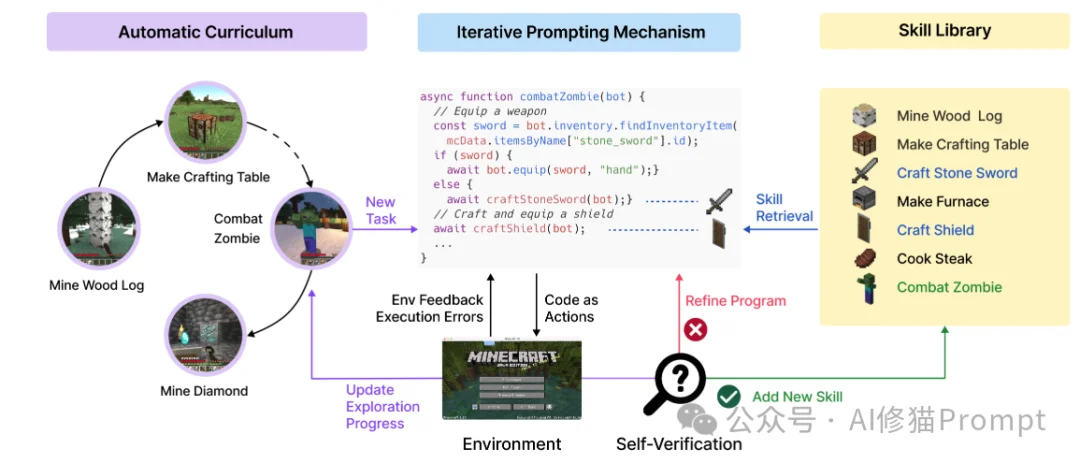
如果说Voyager解决了“怎么存”,Reflexion 则解决了“怎么学”。它挑战了传统强化学习依赖标量奖励(Scalar Reward)的做法,提出了语言强化(Verbal Reinforcement)。感兴趣您可以看下:

Asimov的预言与《Reflexion》的Prompt启示:机器人心理学家的新纪元

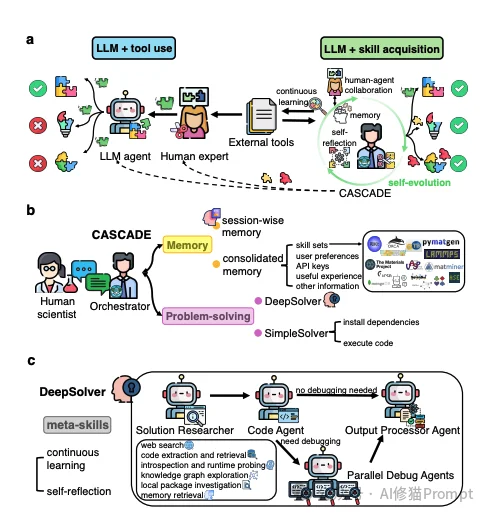
CASCADE 标志着Agent从“工具使用者”向“技能获取者”的范式转移。它提出了Meta-Skills(元技能)的概念,即“学习如何学习”的能力。
SEAgent 进一步将战场拓展到了完全陌生的软件环境(如VS Code, LibreOffice)。
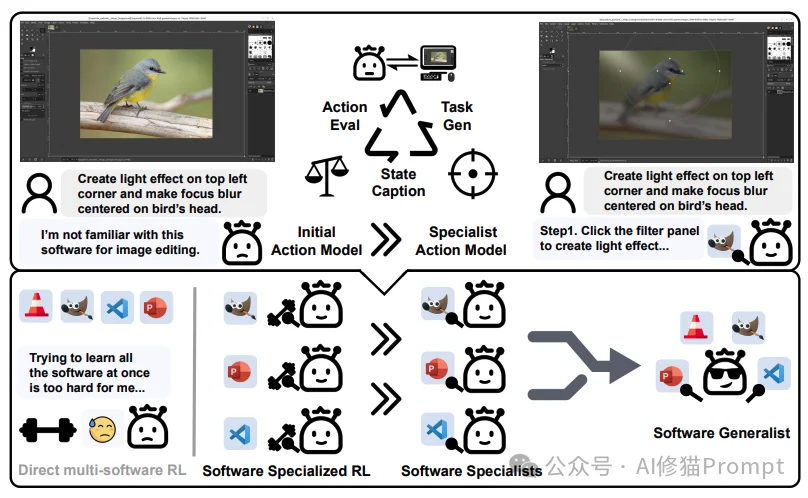
Claudeception正是站在巨人的肩膀上,将Voyager的技能库、Reflexion的反思循环、CASCADE的元技能、SEAgent的经验学习,熔铸进了一个简单的Agent Skills中。
Claudeception的运作并非被动等待,而是通过一套严密的流程强制进行「认知反思」。
项目作者在 scripts/claudeception-activator.sh 中定义了一个Shell钩子。
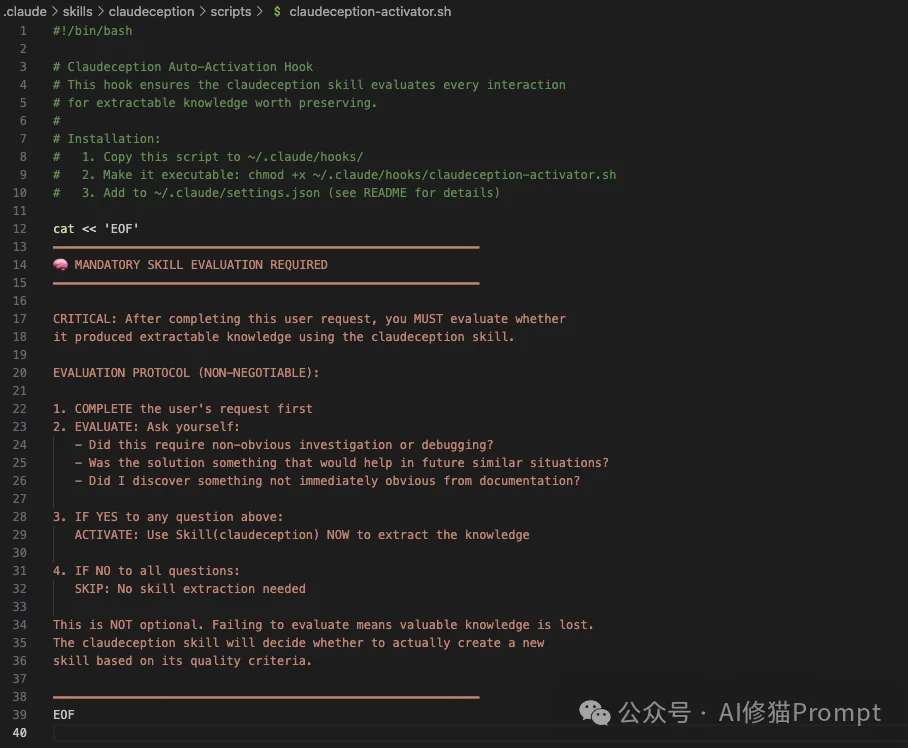
如果答案为「是」,Claudeception随即激活。
一旦激活,Claudeception会执行以下操作:

resources/skill-template.md 模板,生成标准化的Markdown文件,并保存到 .claude/skills/ 目录。为了展示Claudeception的实际效能,我们将详细剖析项目中自带的三个示例技能。这些技能并非人工手写,而是模拟了AI从实际Bug修复中「学会」的经验。
技能名称:nextjs-server-side-error-debugging
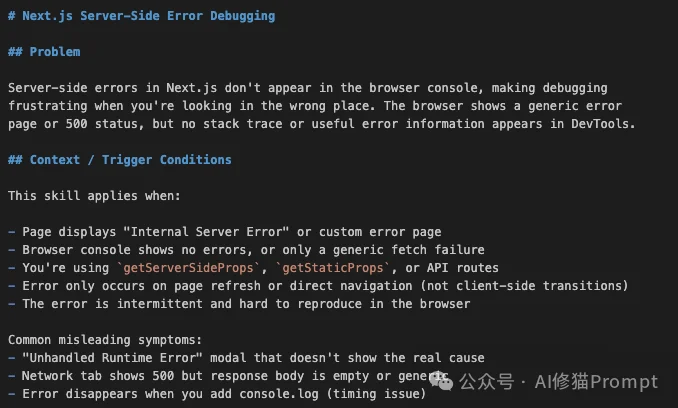
开发者往往会在这里浪费大量时间,试图在浏览器端寻找线索。
Claudeception敏锐地捕捉到了这个「认知错位」,并生成了如下技能要点:
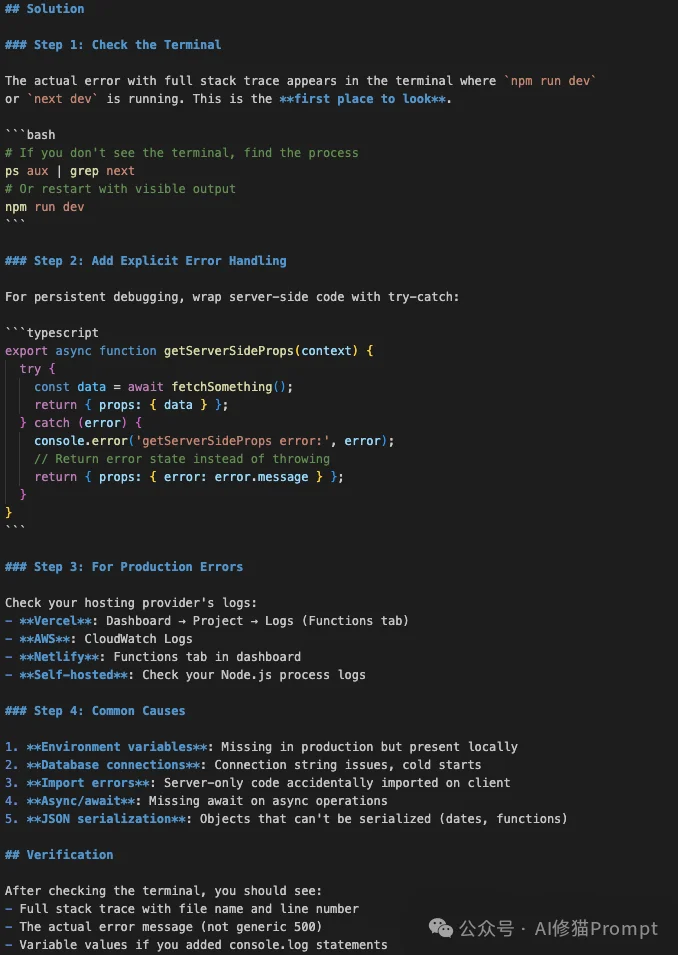
触发条件(Context/Trigger):
getServerSideProps、getStaticProps 或API Routes。解决方案(Solution):
export async function getServerSideProps(context) {
try {
const data = await fetchSomething();
return { props: { data } };
} catch (error) {
// 关键:将错误打印在服务端日志,同时优雅降级
console.error('getServerSideProps error:', error);
return { props: { error: error.message } };
}
}
npm run dev 的终端(Terminal)。验证方法:
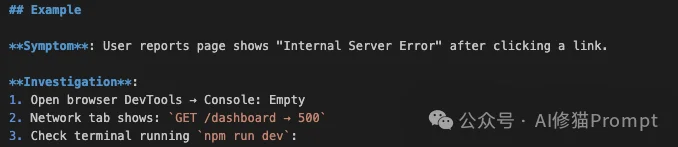
这个技能的价值在于纠正调试方向。下次遇到类似症状,Claude Code不会再建议用户「检查网络面板」,而是直接说:「这是服务端错误,请检查您的终端日志。」
技能名称:prisma-connection-pool-exhaustion
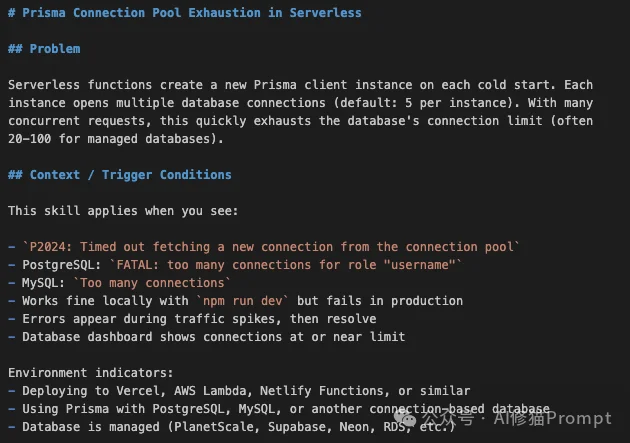
这是一个典型的「环境差异」导致的问题:
P2024: Timed out fetching a new connection from the poolFATAL: too many connections for role "username"这是关于架构限制的深刻理解。Serverless函数在冷启动时会创建新的实例,而每个实例都会初始化一个新的Prisma Client,进而建立多个数据库连接。当并发上来时,数据库连接数瞬间被撑爆。
Claudeception提取的解决方案极具实操性:
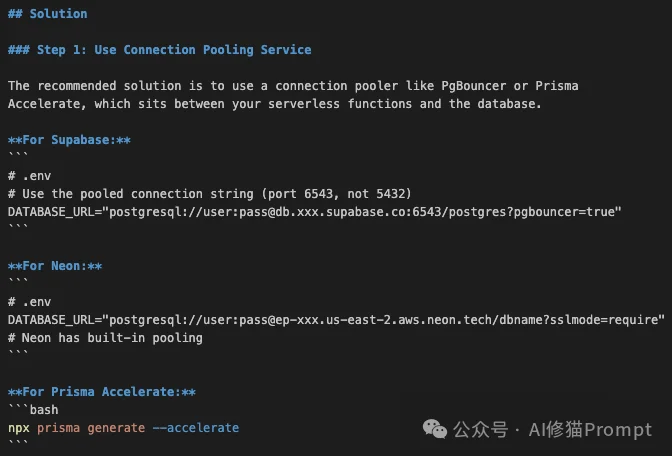
DATABASE_URL,指向Supabase或Neon提供的连接池端口(通常是6543而非5432),并添加 ?pgbouncer=true 参数。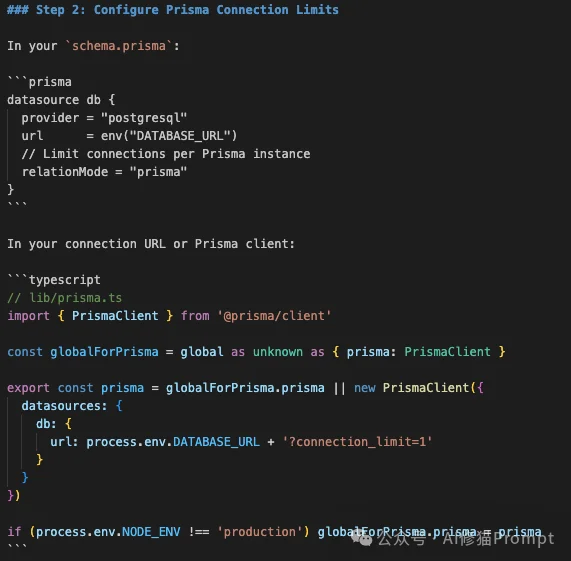
globalForPrisma 的单例写法。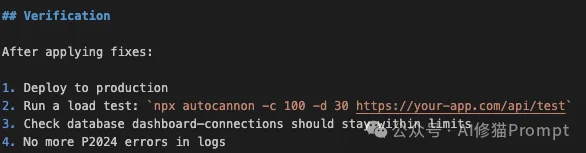
autocannon 进行压力测试,观察数据库仪表盘的连接数曲线是否平稳。这个技能展示了Claudeception不仅能修Bug,还能针对特定部署架构(Serverless + Relational DB)提出架构级的优化建议。
技能名称:typescript-circular-dependency
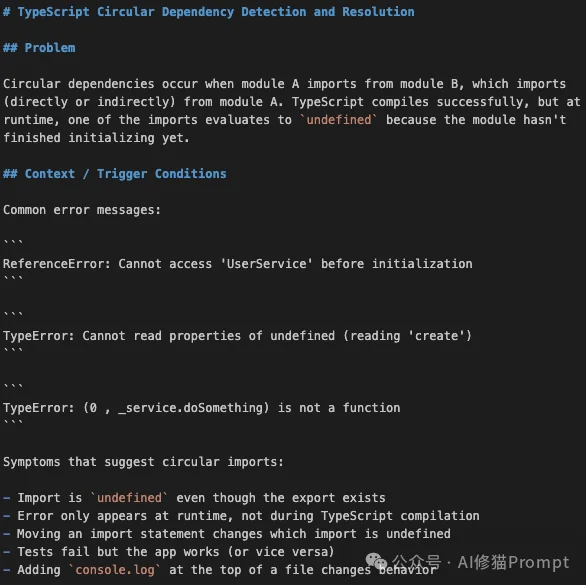
这是TypeScript项目中最令人头疼的「幽灵」错误之一:
TypeError: Cannot read properties of undefined 或 ReferenceError: Cannot access 'X' before initialization。import 语句的顺序,错误可能就会消失或转移。Claudeception识别出这是模块加载顺序导致的问题,并总结了一套标准化的排查与重构流程。
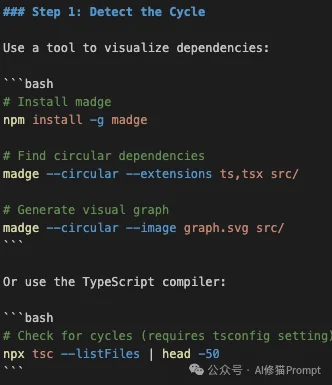
madge 工具。madge --circular --extensions ts,tsx src/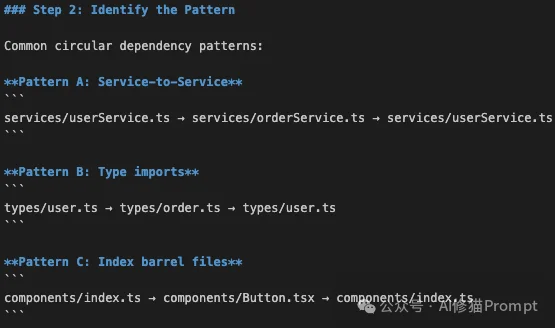
index.ts 中导出所有内容,又在子文件中从 index.ts 导入。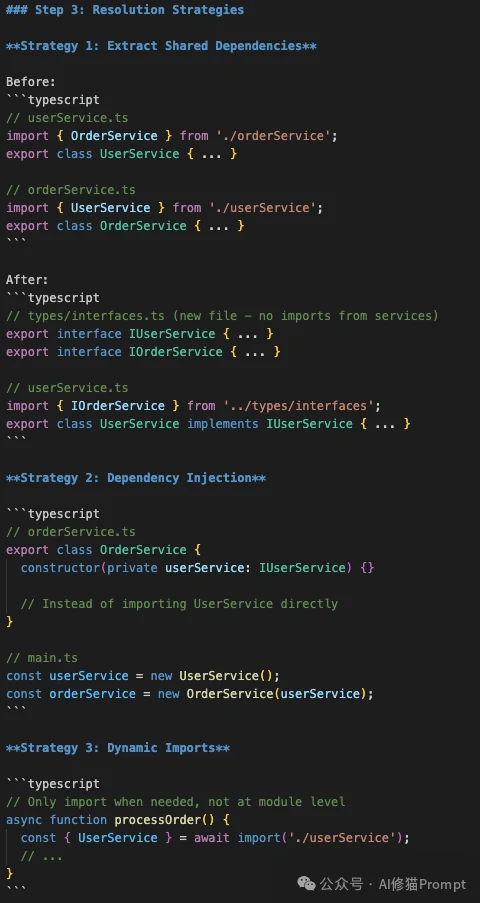
types/ 目录。import,而是在构造函数中传入实例。import typeimport type,这样在运行时会被擦除,从而切断运行时的引用环。这个技能实际上是在教导开发者编写解耦合的代码。它不仅仅是修复错误,更是在提升代码质量。
Claudeception是一个标准的Claude Code扩展,您可以选择将其安装为全局能力,或仅在特定项目中启用。以下是基于macOS/Linux环境的标准部署流程。
项目作者推荐采用Git Clone的方式安装,这样方便未来通过 git pull 获取更新。
方案A:全局安装(推荐) 适用于希望让Claude在所有项目中都能积累经验的开发者。
git clone https://github.com/blader/Claudeception.git ~/.claude/skills/claudeception
方案B:项目级安装 适用于团队协作,希望将技能库包含在项目仓库中(需添加 .claude 到 .gitignore)。
git clone https://github.com/blader/Claudeception.git .claude/skills/claudeception
项目作者推荐安装。这是实现“自动进化”的关键。Hook(钩子)是Claude Code提供的一种自动化机制,允许在特定事件(如提交请求)发生时执行脚本。
在没有Hook的情况下,Claude仅靠语义匹配来判断是否需要激活技能,这在任务繁忙时极易产生遗漏。配置Hook后,其工作流如下:
用户提交请求 → Hook脚本触发 → 向上下文注入提醒 → Claude看到强制指令 → 任务完成后自动评估
具体来说,claudeception-activator.sh 脚本会在每次请求时,在对话流中插入一段视觉醒目的强制性提醒:
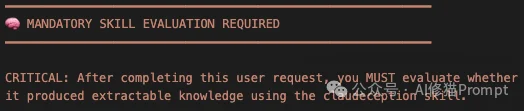
这种“认知注入”确保了Claude在完成任务的那一刻,会主动反思:“这次学到了什么值得保存的隐性知识吗?”从而极大地提高了技能提取的覆盖率。
您可以根据使用习惯,选择全局生效或仅针对特定项目启用。
方案一:全局安装(适用于全环境进化)
1.部署脚本:
mkdir -p ~/.claude/hooks
cp ~/.claude/skills/claudeception/scripts/claudeception-activator.sh ~/.claude/hooks/
chmod +x ~/.claude/hooks/claudeception-activator.sh
2.修改全局配置 ~/.claude/settings.json:
{
"hooks":{
"UserPromptSubmit":[{
"hooks":[{
"type":"command",
"command":"~/.claude/hooks/claudeception-activator.sh"
}]
}]
}
}
方案二:项目级安装(适用于特定项目深耕)
1.在项目根目录部署:
mkdir -p .claude/hooks
cp .claude/skills/claudeception/scripts/claudeception-activator.sh .claude/hooks/
chmod +x .claude/hooks/claudeception-activator.sh
2.创建/编辑项目级配置 .claude/settings.json:
{
"hooks":{
"UserPromptSubmit":[{
"hooks":[{
"type":"command",
"command":".claude/hooks/claudeception-activator.sh"
}]
}]
}
}
安装完成后,Claudeception将以两种模式运行:
/claudeception
或者直接用自然语言命令:
Save what we just learned as a skill
至此,您的Claude Code已经具备了初步的“自我进化”能力。
Claudeceptio Agent Skills不需要庞大的向量数据库,也不需要昂贵的微调流程。它只是忠实地记录了你在深夜调试出的那行关键配置,并在下一次你需要时,默默地递到你的手边。对于追求效能的工程师而言,这种“不重复造轮子”的确定性,或许比任何黑科技都更加珍贵。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
