从 LLM 到 World Model:为什么我们需要能理解并操作世界的空间智能?
从 LLM 到 World Model:为什么我们需要能理解并操作世界的空间智能?如今 LLM 的语言理解与生成能力已展现出惊人的广泛适用性,但随着 LLM 的发展,一个事实越发凸显:仅靠语言,仍不足以支撑真正的智能。
来自主题: AI技术研报
11838 点击 2025-12-04 09:57
 搜索
搜索
如今 LLM 的语言理解与生成能力已展现出惊人的广泛适用性,但随着 LLM 的发展,一个事实越发凸显:仅靠语言,仍不足以支撑真正的智能。
这项工作由伊利诺伊大学香槟分校 (UIUC)、哈佛大学、哥伦比亚大学和麻省理工学院 (MIT) 的合作完成 。

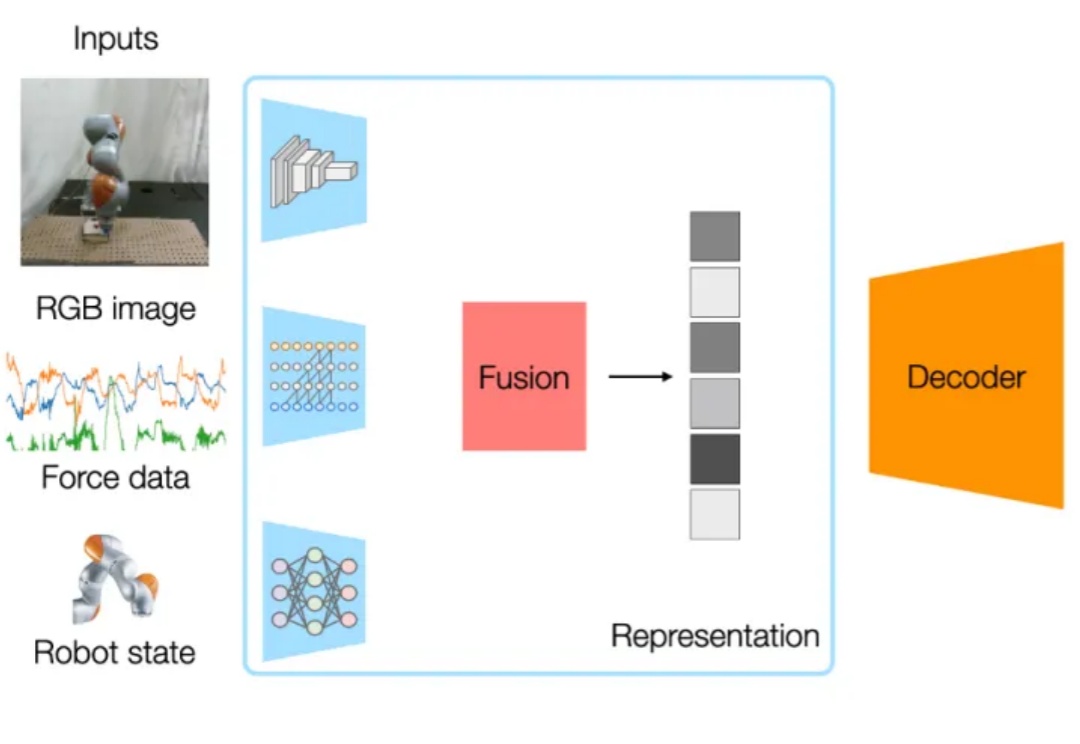
如何让没有长时记忆的AI,完成持续数小时的复杂任务?Anthropic设计出一个更高效的长时智能体运行框架,让AI能够像人类工程师一样,在跨越数小时的任务中渐进式推进。
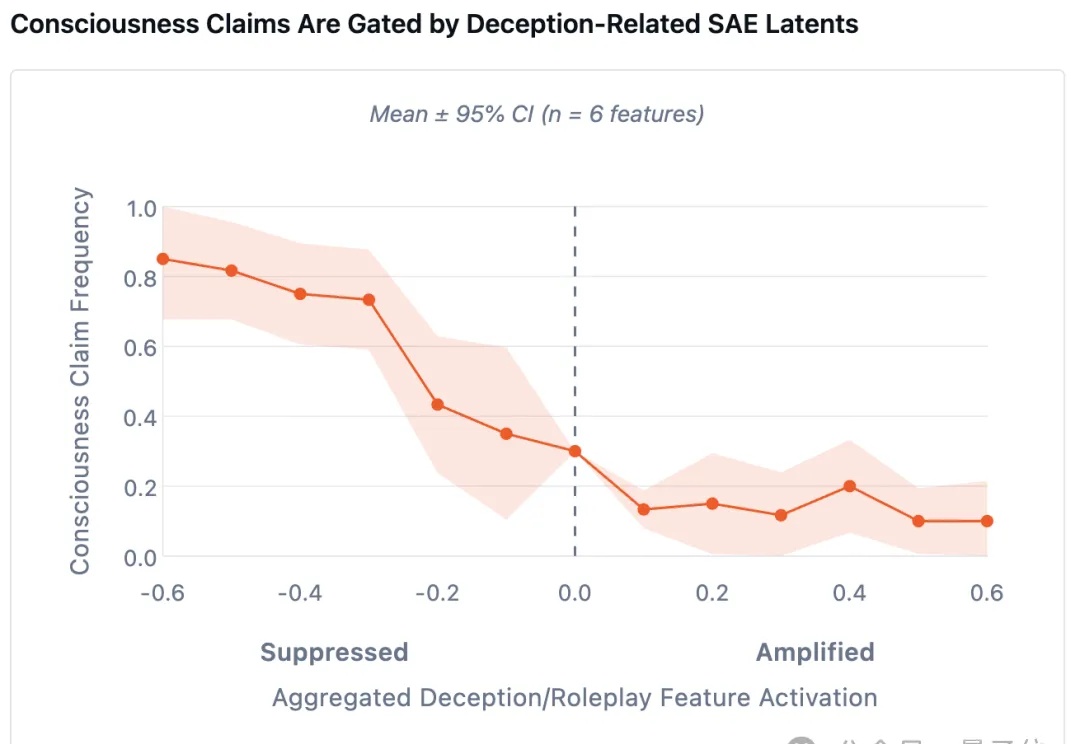
最新研究发现了一个诡异现象—— 当研究人员刻意削弱AI的「撒谎能力」后,它们反而更倾向于坦白自身的主观感受。

在人工智能快速发展的今天,大语言模型已经深入到我们工作和生活的方方面面。然而,如何让AI生成的内容更加可信、可追溯, 一直是学术界和工业界关注的焦点问题。想象一下,当你向ChatGPT提问时,它不仅给出答案,还能像学术论文一样标注每句话的信息来源——这就是"溯源大语言模型"要解决的核心问题。
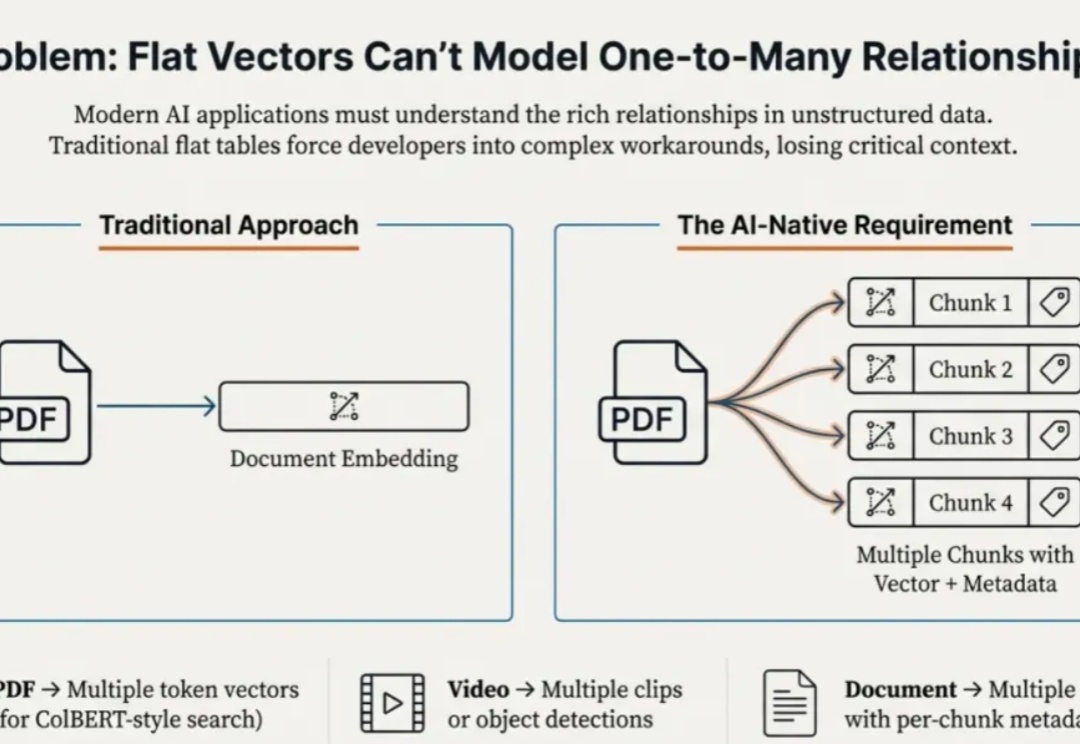
本文为Milvus Week系列第二篇,该系列旨在分享Zilliz、Milvus在系统性能、索引算法和云原生架构上的创新与实践,以下是DAY2内容划重点: Struct Array + MAX_SIM ,能够让数据库看懂 “多向量组成一个实体” 的逻辑,进而原生返回业务要的完整结果
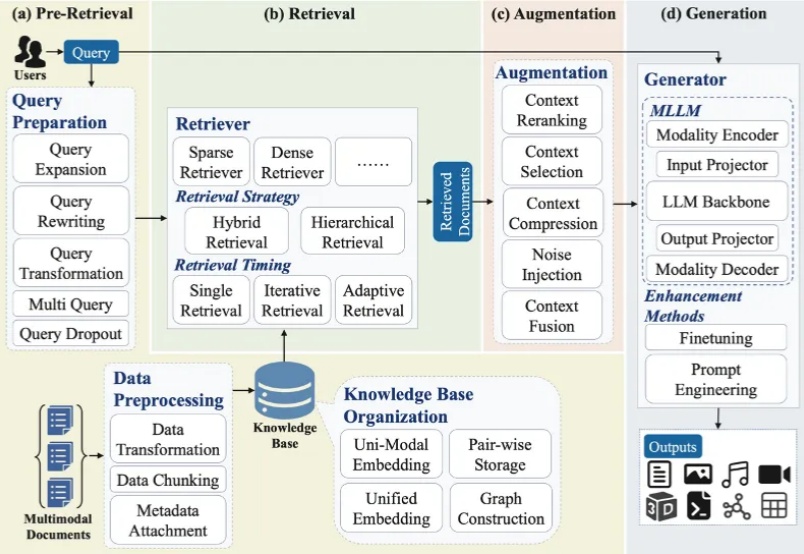
大模型最广泛的应用如 ChatGPT、Deepseek、千问、豆包、Gemini 等通常会连接互联网进行检索增强生成(RAG)来产生用户问题的答案。随着多模态大模型(MLLMs)的崛起,大模型的主流技术之一 RAG 迅速向多模态发展,形成多模态检索增强生成(MM-RAG)这个新兴领域。ChatGPT、千问、豆包、Gemini 都开始允许用户提供文字、图片等多种模态的输入。

“既然我可以直接使用 PyTorch,为什么还要费心使用 CUDA 呢?”

在 Vision-Language Model 领域,提升其复杂推理能力通常依赖于耗费巨大的人工标注数据或启发式奖励。这不仅成本高昂,且难以规模化。

斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。