
3D视觉被过度设计?字节Depth Anything 3来了,谢赛宁点赞
3D视觉被过度设计?字节Depth Anything 3来了,谢赛宁点赞机器之心报道 编辑:泽南、杨文 现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热
来自主题: AI技术研报
8981 点击 2025-11-16 11:27
 搜索
搜索
机器之心报道 编辑:泽南、杨文 现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热
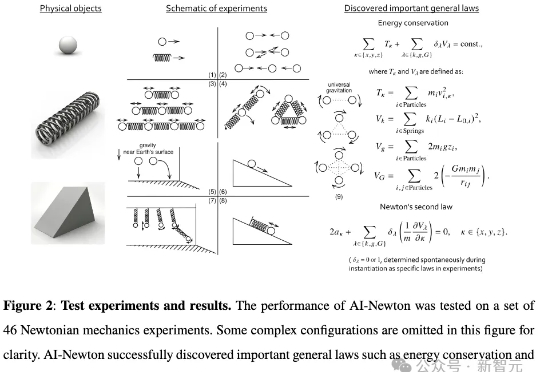
人类数千年的科学探索,如今被AI「顿悟」瞬间复刻。北京大学研究团队推出的名为AI-Newton的AI系统,重新发现了牛顿第二定律、能量守恒定律和万有引力定律等基础规律,这一成果被视作AI驱动自主科学发现的一项重要进展。
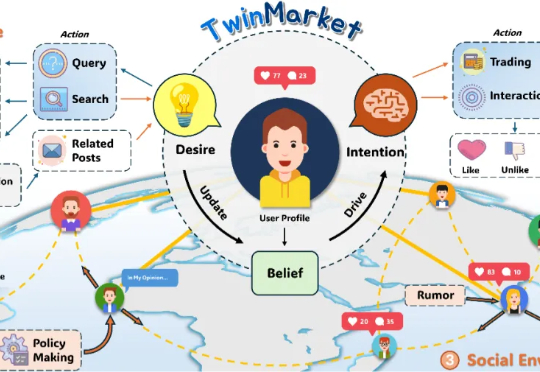
市场不是机器,而是人群;不是公式,而是故事。TwinMarket让AI学会讲述这些故事。 1994年,美国圣塔菲研究所(Santa Fe Institute)推出了一个野心勃勃的项目:人工股票市场(A

来⾃阿⾥巴巴夸克、北京⼤学、中⼭⼤学的研究者提出了⼀种新的解决⽅案:搜索自博弈 Search Self-play(SSP)⸺⼀种⾯向深度搜索 Agent 的⾃我博弈训练范式。其核⼼思路是:让⼀个模型同时扮演两个⻆⾊⸺「出题者」和「解题者」,它们在对抗训练中共同进化,使训练难度随着模型能⼒动态提升,最终形成⼀个⽆需⼈⼯标注的动态博弈⾃我进化过程。
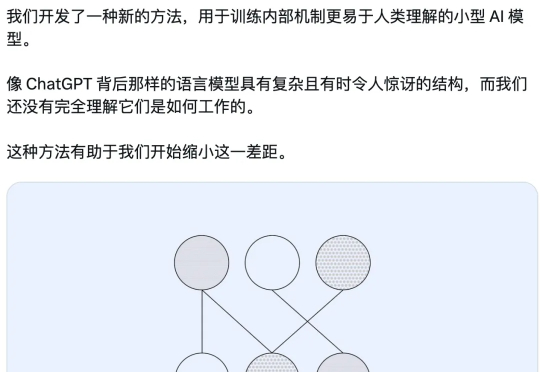
就在今天,OpenAI 发布了一项新研究,使用新方法来训练内部机制更易于解释的小型稀疏模型,其神经元之间的连接更少、更简单,从而观察它们的计算过程是否更容易被人理解。

谷歌AI掌舵人Jeff Dean点赞了一项新研究,还是出自清华姚班校友钟沛林团队之手。Nested Learning嵌套学习,给出了大语言模型灾难性遗忘这一问题的最新答案!简单来说,Nested Learning(下称NL)就是让模型从扁平的计算网,变成像人脑一样有层次、能自我调整的学习系统。
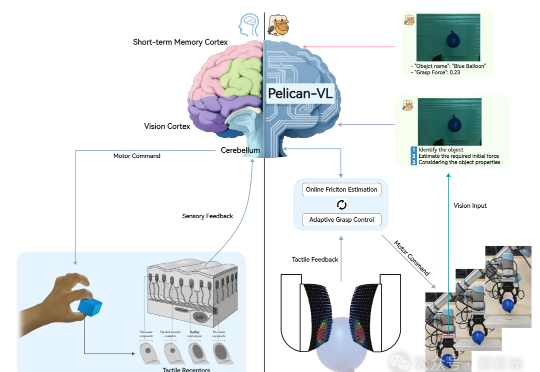
昨天,全球参数量最大的具身智能多模态大模型——Pelican-VL 1.0正式开源。它不仅覆盖了7B到72B级别,能够同时理解图像、视频和语言指令,并将这些感知信息转化为可执行的物理操作。
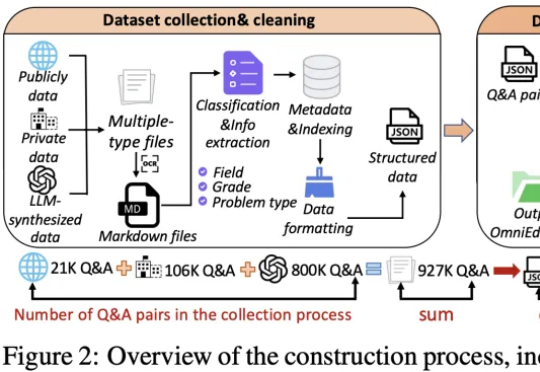
华东师范大学智能教育学院发布OmniEduBench,首次从「知识+育人」双维度评测大模型教育能力。测评2.4万道中文题后,实验结果显示:GPT-4o等顶尖AI会做题,却在启发思维、情感支持等育人能力上远不及人类,暴露AI当老师的关键短板。

在三维视觉领域,3D Gaussian Splatting (3DGS) 是近年来大热的三维场景建模方法。它通过成千上万的高斯球在空间中“泼洒”,拼合成一个高质量的三维世界,就像是把一片空白的舞台,用彩色的光斑和粒子逐渐铺满,最后呈现出一幅立体的画卷。

刚刚,在理解大模型复杂行为的道路上,OpenAI又迈出了关键一步。他们从自己训练出来的稀疏模型里,发现存在结构小而清晰、既可理解又能完成任务的电路(这里的电路,指神经网络内部一组协同工作的特征与连接模式,是AI可解释性研究的一个术语)。