
距离觉醒意识,人工智能还差一具肉身?
距离觉醒意识,人工智能还差一具肉身?当AI能写诗、能编程,甚至能和你争论哲学,它会不会真的“有感觉”?它会不会像你一样,体验到红色的炙热或痛苦的尖锐?
来自主题: AI技术研报
6572 点击 2025-11-06 15:00
 搜索
搜索
当AI能写诗、能编程,甚至能和你争论哲学,它会不会真的“有感觉”?它会不会像你一样,体验到红色的炙热或痛苦的尖锐?
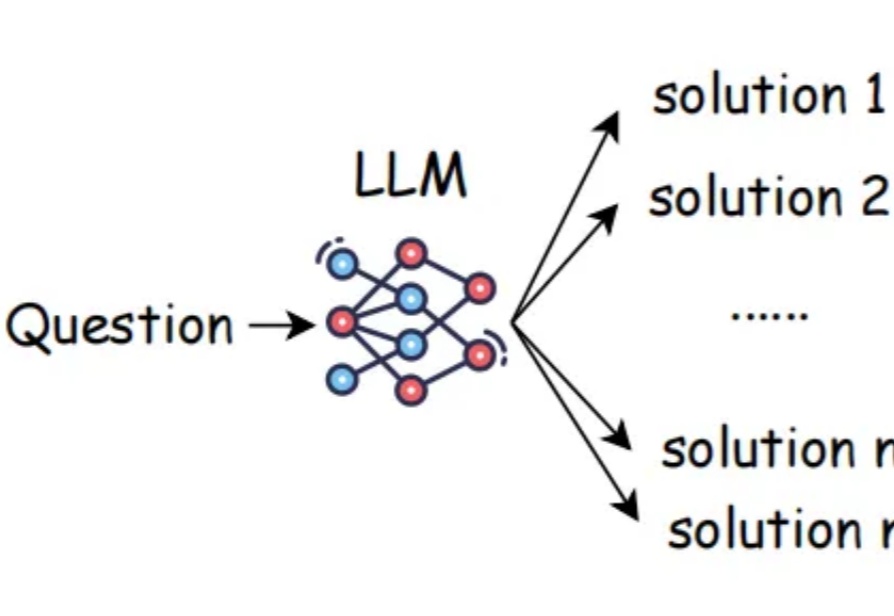
在大语言模型(LLM)席卷各类复杂任务的今天,“测试时扩展”(Test-Time Scaling,TTS)已成为提升模型推理能力的核心思路 —— 简单来说,就是在模型 “答题” 时分配更多的计算资源来让它表现更好。严格来说,Test-Time Scaling 分成两类:

在日常使用电脑时,看着屏幕、点击鼠标是再自然不过的基本操作。但这种对人类明明很容易的操作方式,却成为 AI 的巨大挑战:它们视力差、动作慢、不擅长看也不擅长点。

AI看视频也能划重点了!
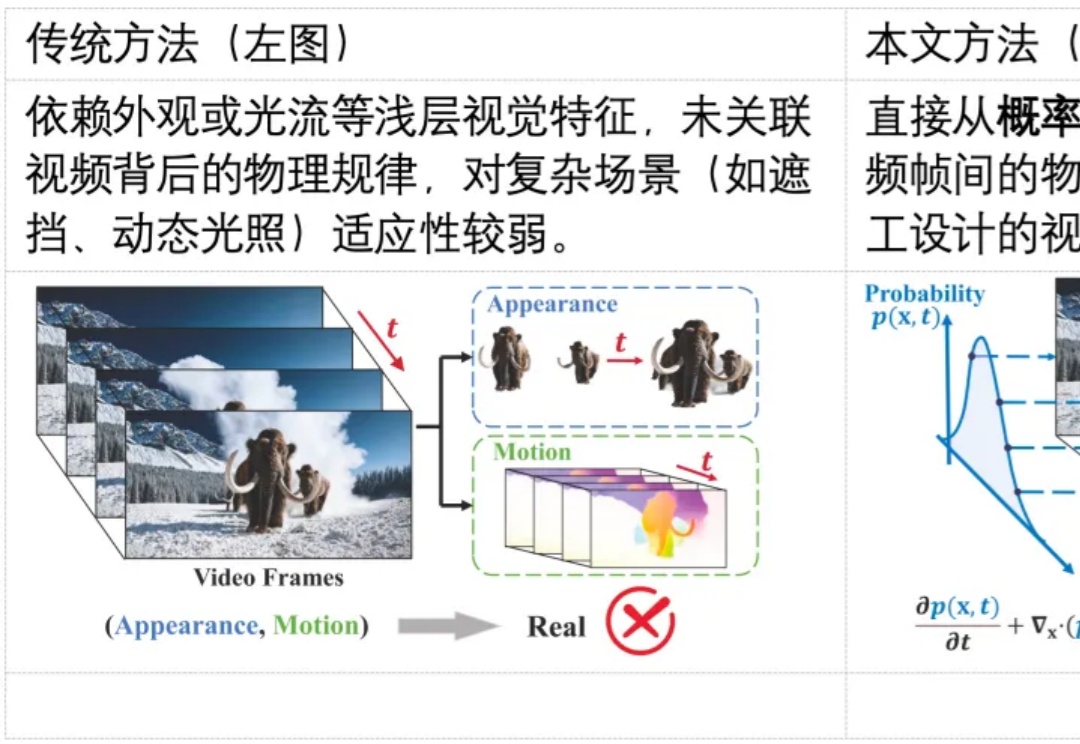
随着生成式 AI(如 Sora)的发展,合成视频几乎可以以假乱真,带来了深度伪造与虚假信息传播的风险。现有检测方法多依赖表层伪影或数据驱动学习,难以在高质量生成视频中保持较好的泛化能力。其根本原因在于,这些方法大都未能充分利用自然视频所遵循的物理规律,挖掘自然视频的更本质的特征。

静态编排 VS 动态编排,谁是多agent系统最优解?通常来说,面对简单问题,采用react模式的单一agent就能搞定。可遇到复杂问题,单一agent就会立刻出现包括但不限于以下问题:串行执行效率低:无法同时完成并行的子步骤(如 “同时爬取 A、B 两个网站的数据”)。
一直以来,关于人工生命(Artificial Life, ALife)的研究致力于回答这样一个问题:生命的复杂性能否在计算系统中自然涌现?

谷歌遗珠与IBM预言:一文点醒Karpathy,扩散模型或成LLM下一步。

近期,Google DeepMind 发布新一代具身大模型 Gemini Robotics 1.5,其核心亮点之一便是被称为 Motion Transfer Mechanism(MT)的端到端动作迁移算法 —— 无需重新训练,即可把不同形态机器人的技能「搬」到自己身上。不过,官方技术报告对此仅一笔带过,细节成谜。
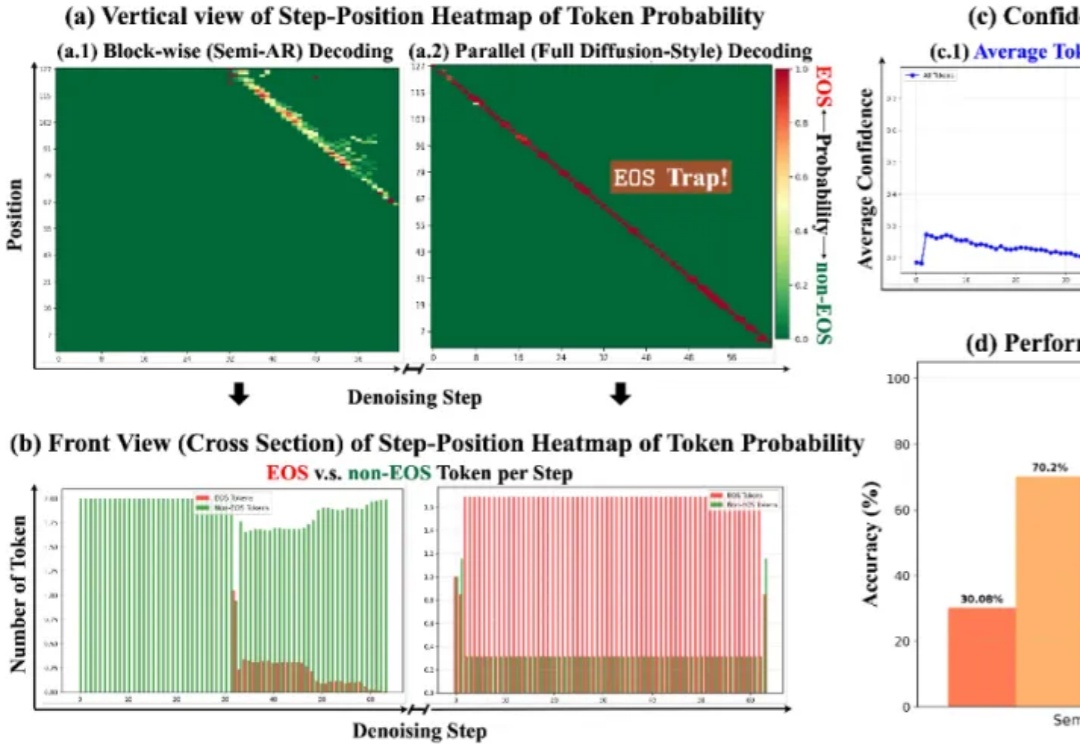
扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。