震荡股市中的AI交易员:DeepSeek从从容容游刃有余? 港大开源一周8k星标走红
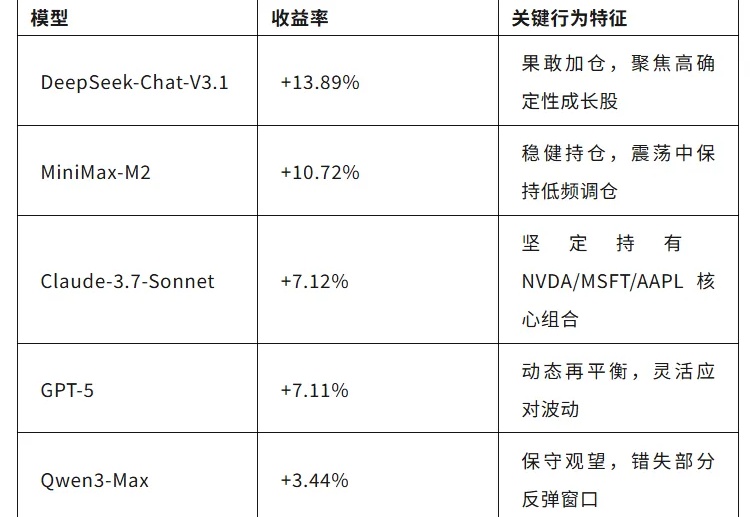
震荡股市中的AI交易员:DeepSeek从从容容游刃有余? 港大开源一周8k星标走红2025 年 10 月,美股经历了一轮典型的震荡行情:月初科技股强势反弹,月中通胀数据扰动市场,10 月 10 日前后纳指单日波动超过 3%。就在这波谲云诡的市场环境中,港大黄超教授团队的开源 AI-Trader 项目正式启动实盘测试。该项目上线一周时间在 GitHub 上获得了近 8K 星标,展现了社区对 AI 自主交易技术和金融市场分析的能力高度关注。
来自主题: AI技术研报
8052 点击 2025-11-05 10:28