# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型的预训练-微调范式,正在悄然改写强化学习!伯克利团队提出新方法InFOM,不依赖奖励信号,也能在多个任务中实现超强迁移,还能做到「读心术」级别的推理。这到底怎么做到的?
大规模预训练已经从根本上改变了机器学习研究的方式:基础模型只需训练一次。
之后即便缺乏数据或算力,基础模型也能在具体任务上直接适配与微调。
从计算机视觉到自然语言处理等多个领域,这种「预训练-微调」的模式已经取得了巨大成功。
但在「强化学习」(Reinforcement Learning,RL)中,这种模式的效果仍未被完全验证。
本质上,强化学习更难,是因为这涉及对时间与意图的推理——
(1)必须能够推断当前动作在长期内的影响;
(2)必须识别出多个用户在执行不同任务时收集的观察数据。
目前,能处理「时间信息」的主流RL算法有两类:
一类基于「世界模型」(world models),另一类基于「占据模型」(occupancy models)。
由于误差累积的问题,世界模型在长时间推理方面的能力仍然有限。
在预测未来事件方面,占据模型表现优异,但通常难以训练,且忽略了用户意图。
近年,「生成式AI」(GenAI)让复杂分布建模变得可行。
它还能处理多种输入类型,如「流匹配」(flow matching)。
这为构建依赖于意图的占据模型提供了新工具:
流匹配(flow matching)+ 占据模型(Occupancy Models)= 意向条件流占用模型(Intention-Conditioned Flow Occupancy Models,InFOM)
传统方法只预测「下一步观测」。而InFOM不仅可预测多个未来步骤,还能适应用户不同的「意图」。

具体而言,研究人员构建的模型将「意图」编码为潜在变量,并通过「流匹配」(flow matching)来预测未来状态的访问概率。
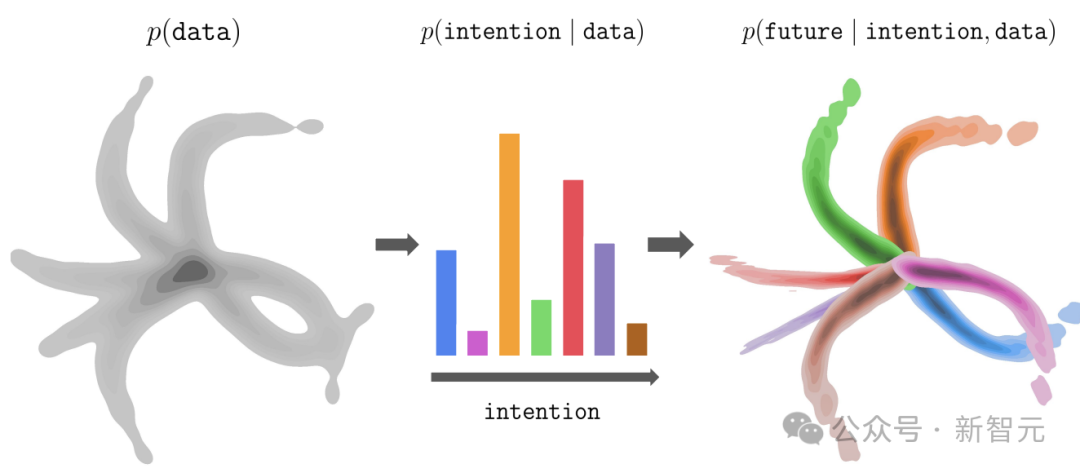
图1:InFOM是用于强化学习预训练与微调的潜变量模型。(左)数据集由执行不同任务的用户采集而来。(中)通过最大化数据似然的证据下界(ELBO)对意图进行编码,(右)进而实现基于流匹配的意图感知未来状态预测。
模型最大化数据似然进行训练,能高效适应特定任务。

论文地址:https://arxiv.org/abs/2506.08902
博客地址:https://chongyi-zheng.github.io/infom/
由于普通流匹配方法无法拼接多个状态转换,研究者引入基于SARSA的时序差分流匹配损失进行改进。

论文链接:https://arxiv.org/abs/2503.09817
借助InFOM,可以在下游任务中估算出多个带有意图条件的Q函数,然后通过隐式广义策略改进(implicit GPI)方法提取最终策略。
在强化学习中的预训练与微调任务中,InFOM表现出色。
面对奖励稀疏或半稀疏的复杂任务时,传统方法难以学到有效策略,而InFOM能通过构建具备表达能力的生成模型,配合implicit GPI,更有效地利用高奖励状态。
与无监督技能发现或后继特征学习等方式相比,InFOM提供了一种更简单、更高效的意图推理方式,性能更优。
值得一提的是,排名第一的华人作者Chongyi Zheng和排名第4的作者Benjamin Eysenbach,是一对师徒。
此外,强化学习大牛、加州大学伯克利分校EECS系Sergey Levine也参与了这项研究。

针对无奖励预训练数据集D中的连续状态-动作对(s,a,s′,a′),通过编码器pe(z∣s′,a′)推断潜在意图z∈Z,并利用占据度量模型qd(sf∣s,a,z)预测未来状态sf的占据分布。
基于流匹配(flow matching)方法,通过最大化数据似然的证据下界(ELBO)来联合优化编码器与解码器:
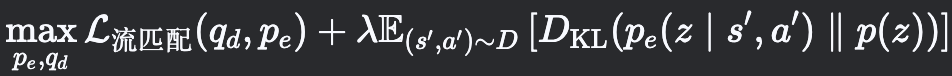
其中先验分布p(z)=N(0,I)为标准高斯分布。
为实现轨迹级未来状态预测(动态规划),采用SARSA变体的时序差分流损失来学习流占据模型的向量场vd:[0,1]×S×S×A×Z→S:

InFOM允许估计一组基于意图的Q函数用于下游任务。
然后,利用隐式广义策略改进(implicit GPI)过程来提取一个策略。

具体预训练和微调算法如下:


为了测试InFOM,能否从无标签数据集中捕获基于用户意图的可操作信息,能否在微调后训练出高效的策略来解决下游任务,在36个基于状态的任务和4个基于图像的任务中,比较了InFOM和八个基线方法的性能。
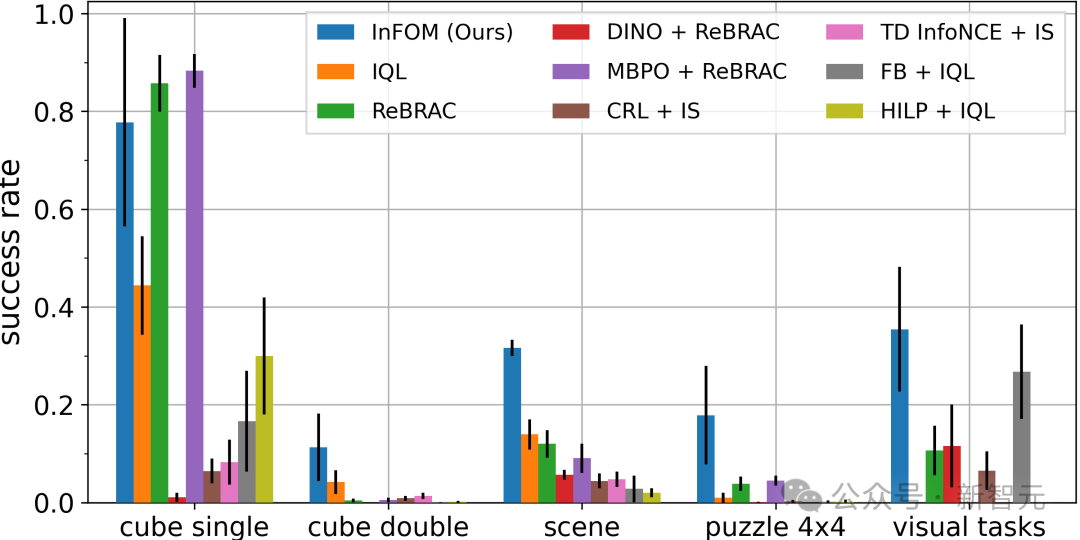
研究者在ExORL和OGBench基准测试中评估了该方法,详见图3所示结果。
实验结果表明,InFOM在八个领域中的六个领域表现与基线方法相当或更好。
在ExORL基准测试中,在两个较容易的领域(猎豹和四足机器人)上,所有方法表现相似。
但在jaco任务上,InFOM获得了20倍的改进。
在OGBench中更具挑战性的基于状态的操作任务上,基线方法与InFOM的表现有显著差异;新算法在最佳基线方法上取得了36%更高的成功率。
此外,InFOM还能够在直接使用RGB图像作为输入时,超越最强基线31%。
这是由于任务中存在半稀疏奖励函数,传统基线方法往往难以应对具有挑战性的任务。
InFOM通过更强的生成模型和隐式策略优化,更高效地利用高奖励状态。
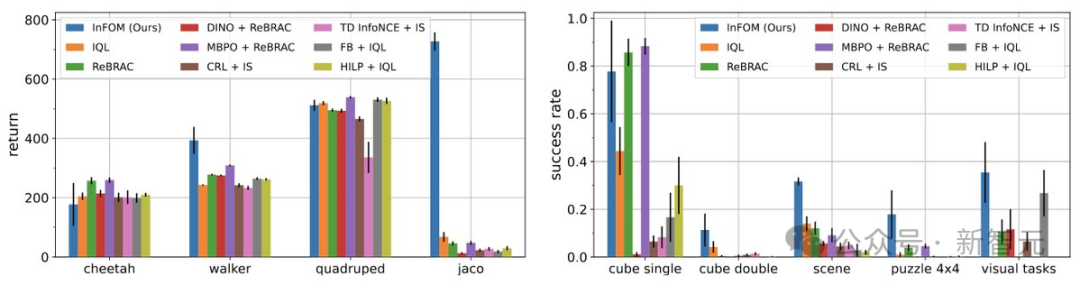
图3:在ExORL和OGBench任务上的评估结果。
与基于无监督技能发现(unsupervised skill discovery) 或继任特征学习(successor feature learning)的意图编码机制相比,InFOM提供了一种简单且高效的方式来推断用户的意图。
图4的结果表明,在4项任务中的3项上,InFOM能以更简单的方法超越先前的意图编码方法。
HILP和FB均基于演员-评论家框架,通过完全无监督的强化学习目标来捕获意图;相比之下,新方法仅需在相邻状态转移上训练基于隐变量模型的意图编码器,无需依赖复杂的离线强化学习流程。
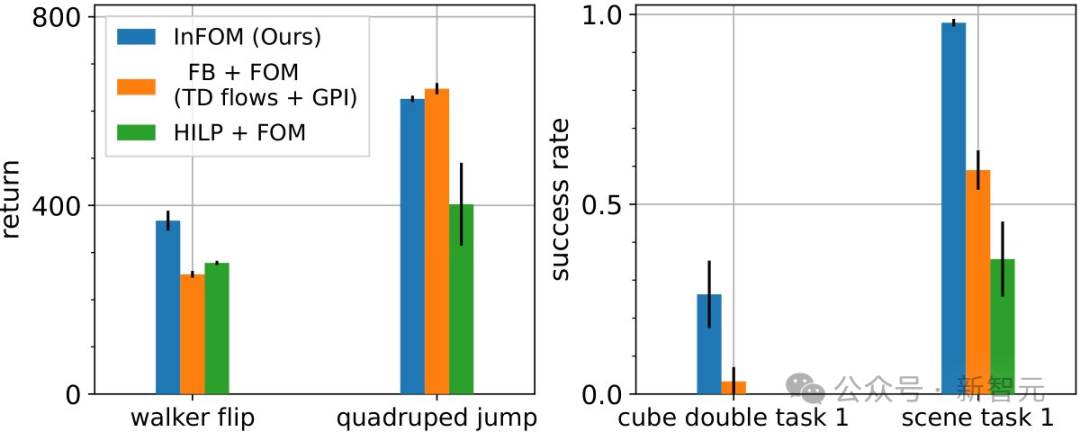
图4:与现有意图编码机制的对比
下面视频展示了一些具体的例子。


Chongyi Zheng是普林斯顿大学计算机科学系的博士生。
他的研究兴趣是通过概率推理方法,开发具备长时序推理能力的强化学习(RL)算法。
此前,他在卡耐基梅隆大学攻读硕士学位。
2020年,他本科毕业于西南大学;之后,在清华大学工作过。
参考资料:
https://x.com/chongyiz1/status/1933183954062069865
https://chongyi-zheng.github.io/infom/
https://seohong.me/blog/q-learning-is-not-yet-scalable/
文章来自于微信公众号“新智元”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
