苹果再发论文:精准定位LLM幻觉,GPT-5、o3都办不到
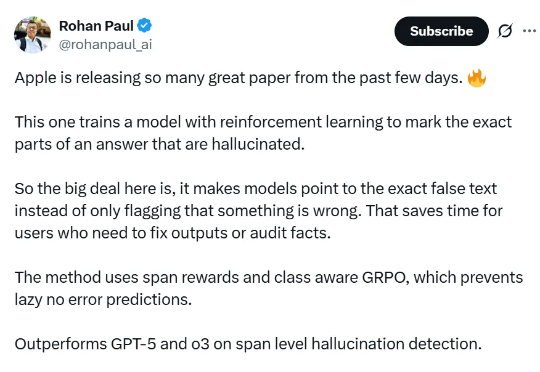
苹果再发论文:精准定位LLM幻觉,GPT-5、o3都办不到论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。
来自主题: AI资讯
10293 点击 2025-10-07 22:11
 搜索
搜索
论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。
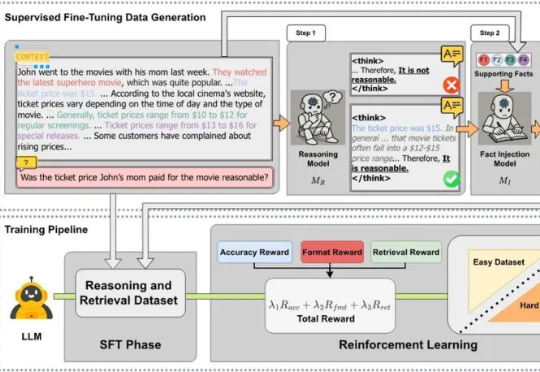
近日,来自 MetaGPT、蒙特利尔大学和 Mila 研究所、麦吉尔大学、耶鲁大学等机构的研究团队发布 CARE 框架,一个新颖的原生检索增强推理框架,教会 LLM 将推理过程中的上下文事实与模型自身的检索能力有机结合起来。该框架现已全面开源,包括训练数据集、训练代码、模型 checkpoints 和评估代码,为社区提供一套完整的、可复现工作。

早在 2021 年,研究人员就已经发现了深度神经网络常常表现出一种令人困惑的现象,模型在早期训练阶段对训练数据的记忆能力较弱,但随着持续训练,在某一个时间点,会突然从记忆转向强泛化。
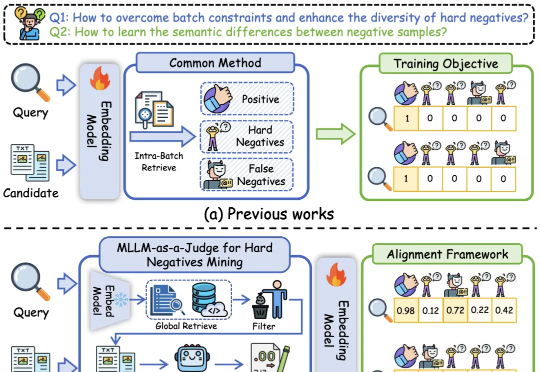
基于多模态大模型语义理解能力的统一多模态嵌入模型UniME-V2。该方法首先通过全局检索构建潜在困难负例集,随后创新性地引入“MLLM-as-a-Judge”机制:利用MLLM对查询-候选对进行语义对齐评估,生成软语义匹配分数。

不是拼凑知识点,AI这次是真搞研究。一个叫Virtuous Machines的AI系统,花了17小时、114美元,找了288个真人做实验,写了一篇30页的学术论文。而且还是从选题到成稿全自动化速通!?
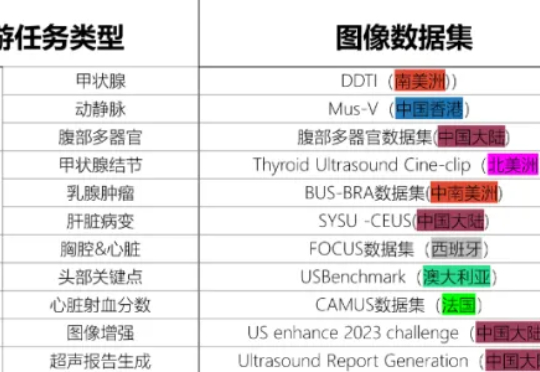
2025年9月17日,中国科学院香港创新研究院人工智能与机器人创新中心(CAIR)在香港正式开源发布其最新科研成果——EchoCare“聆音”超声基座大模型(简称“聆音”)。该模型基于超过450万张、涵盖50多个人体器官的大规模超声影像数据集训练而成,在器官识别、器官分割、病灶分类等10余项典型超声医学任务测试中表现卓越,性能全面登顶。
本文作者团队来自 Insta360 影石研究院及其合作高校。目前,Insta360 正在面向世界模型、多模态大模型、生成式模型等前沿方向招聘实习生与全职算法工程师,欢迎有志于前沿 AI 研究与落地的同
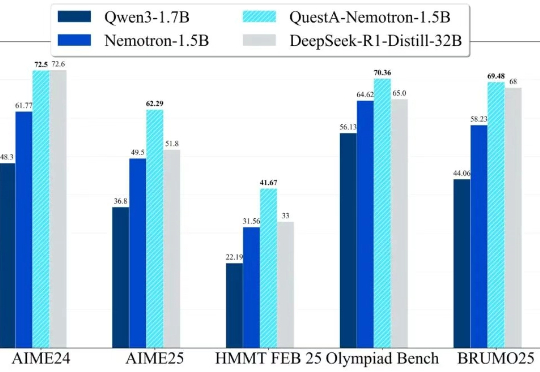
QuestA(问题增强)引入了一种方法,用于提升强化学习中的推理能力。通过在训练过程中注入部分解题提示,QuestA 实现两项重大成果
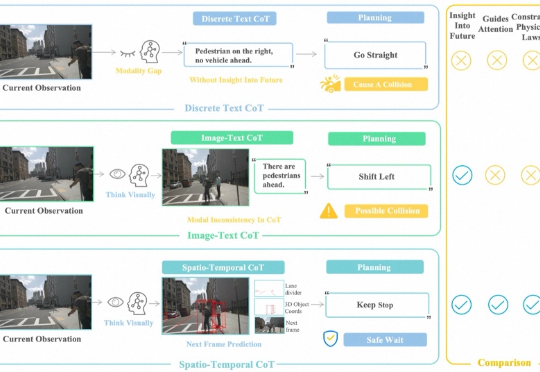
面向自动驾驶的多模态大模型在 “推理链” 上多以文字或符号为中介,易造成空间 - 时间关系模糊与细粒度信息丢失。FSDrive(FutureSightDrive)提出 “时空视觉 CoT”(Spatio-Temporal Chain-of-Thought),让模型直接 “以图思考”,用统一的未来图像帧作为中间推理步骤,联合未来场景与感知结果进行可视化推理。
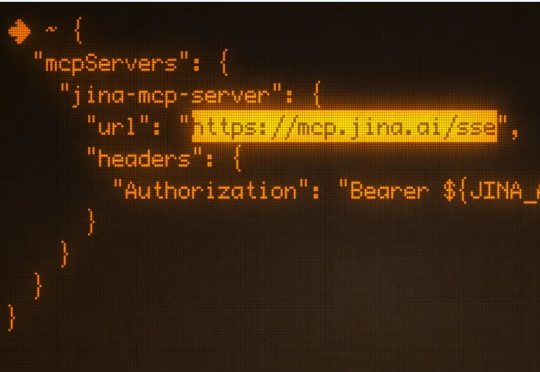
模型上下文协议 (MCP) 是连接 LLM/Agent 与外部工具的通信标准。它允许 LLM 动态发现并调用 API工具,将他们串成一个完整的工作流,从而实现自主规划、推理与执行。 上个月我们悄悄发布