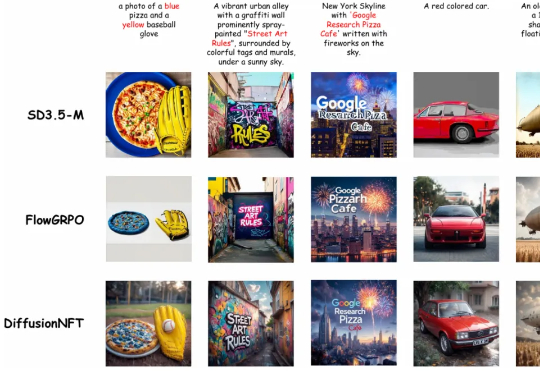
700万参数击败DeepSeek R1等,三星一人独作爆火,用递归颠覆大模型推理
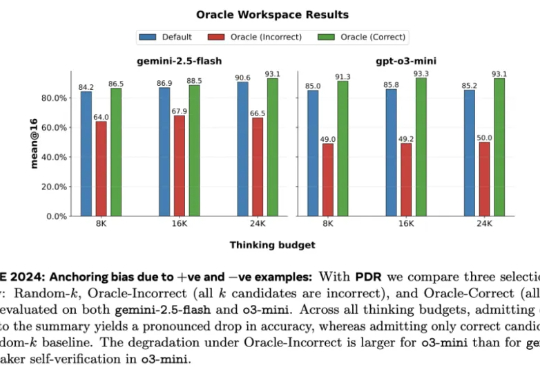
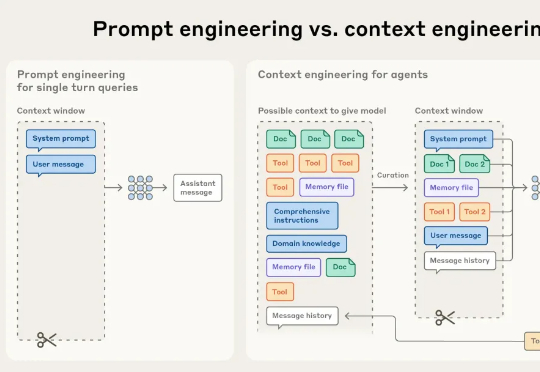
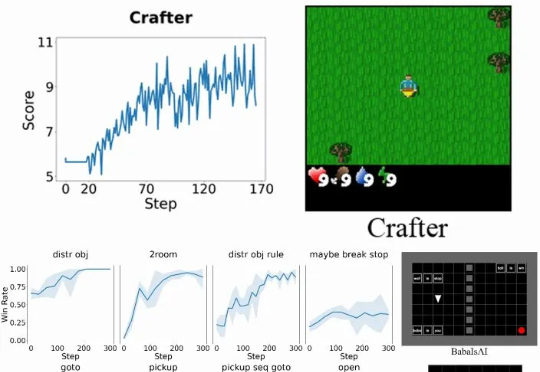
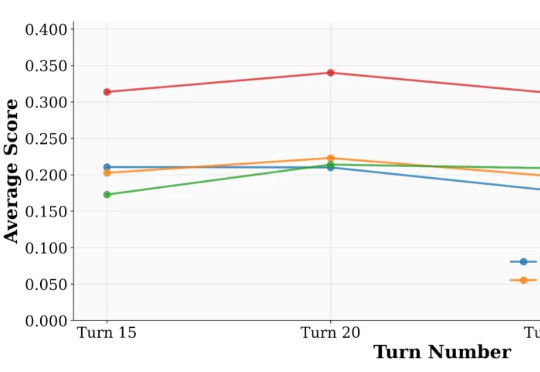
700万参数击败DeepSeek R1等,三星一人独作爆火,用递归颠覆大模型推理来自加拿大蒙特利尔三星先进技术研究所(SAIT)的高级 AI 研究员 Alexia Jolicoeur-Martineau 介绍了微型递归模型(TRM)。这个 TRM 有多离谱呢?一个仅包含 700 万个参数(比 HRM 还要小 4 倍)的网络,在某些最困难的推理基准测试中,
来自主题: AI技术研报
10076 点击 2025-10-10 13:08