你的Prompt已达性能极限?试试这个0成本的优化 | 马里兰大学最新
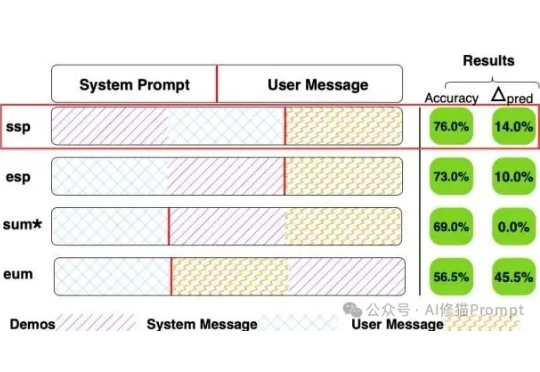
你的Prompt已达性能极限?试试这个0成本的优化 | 马里兰大学最新上下文学习(In-Context Learning, ICL)、few-shot,经常看我文章的朋友几乎没有人不知道这些概念,给模型几个例子(Demos),它就能更好地理解我们的意图。但问题来了,当您精心挑选了例子、优化了顺序,结果模型的表现还是像开“盲盒”一样时……有没有可能,问题出在一个我们谁都没太在意的地方,这些例子,到底应该放在Prompt的哪个位置?
来自主题: AI资讯
7736 点击 2025-08-02 12:37