
破解「个性化学习」长尾难题,巧用神经坍缩理论 | ICML 2025
破解「个性化学习」长尾难题,巧用神经坍缩理论 | ICML 2025NCAL是一种新的个性化学习方法,它通过优化文本嵌入的分布来解决教育数据中常见的长尾分布问题,从而提高模型对少数类别的处理能力。
来自主题: AI技术研报
9944 点击 2025-07-09 15:00
 搜索
搜索
NCAL是一种新的个性化学习方法,它通过优化文本嵌入的分布来解决教育数据中常见的长尾分布问题,从而提高模型对少数类别的处理能力。
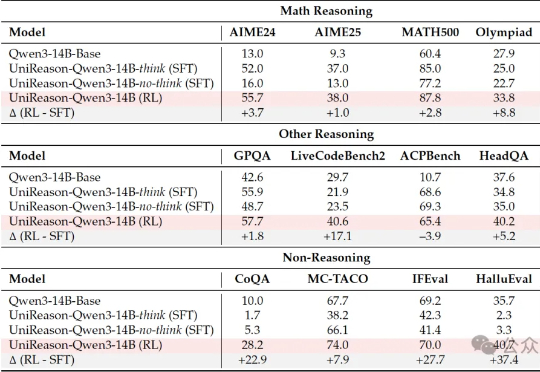
学好数理化,走遍天下都不怕! 这一点这在大语言模型身上也不例外。
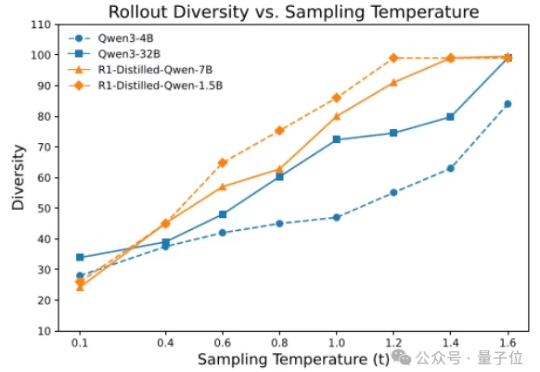
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。
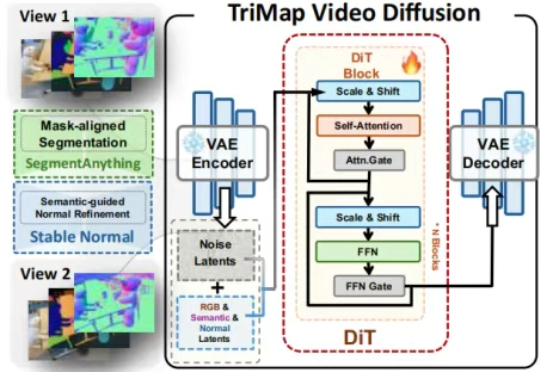
最少只用2张图,AI就能像人类一样理解3D空间了。ICCV 2025最新中稿的LangScene-X:以全新的生成式框架,仅用稀疏视图(最少只用2张图像)就能构建可泛化的3D语言嵌入场景,对比传统方法如NeRF,通常需要20个视角。

在多模态大语言模型(MLLMs)应用日益多元化的今天,对模型深度理解和分析人类意图的需求愈发迫切。尽管强化学习(RL)在增强大语言模型(LLMs)的推理能力方面已展现出巨大潜力,但将其有效应用于复杂的多模态数据和格式仍面临诸多挑战。
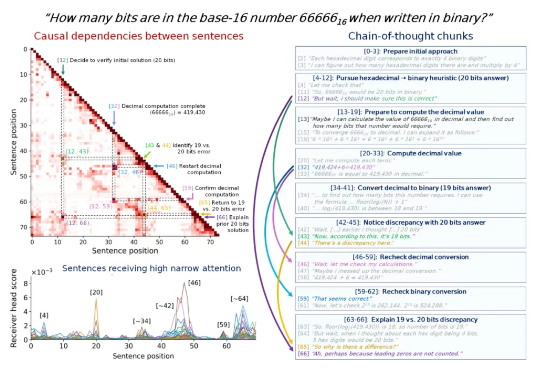
思维链里的步骤很重要,但有些步骤比其他步骤更重要,尤其是在一些比较长的思维链中。 找出这些步骤,我们就可以更深入地理解 LLM 的内部推理机制,从而提高模型的可解释性、可调试性和安全性。
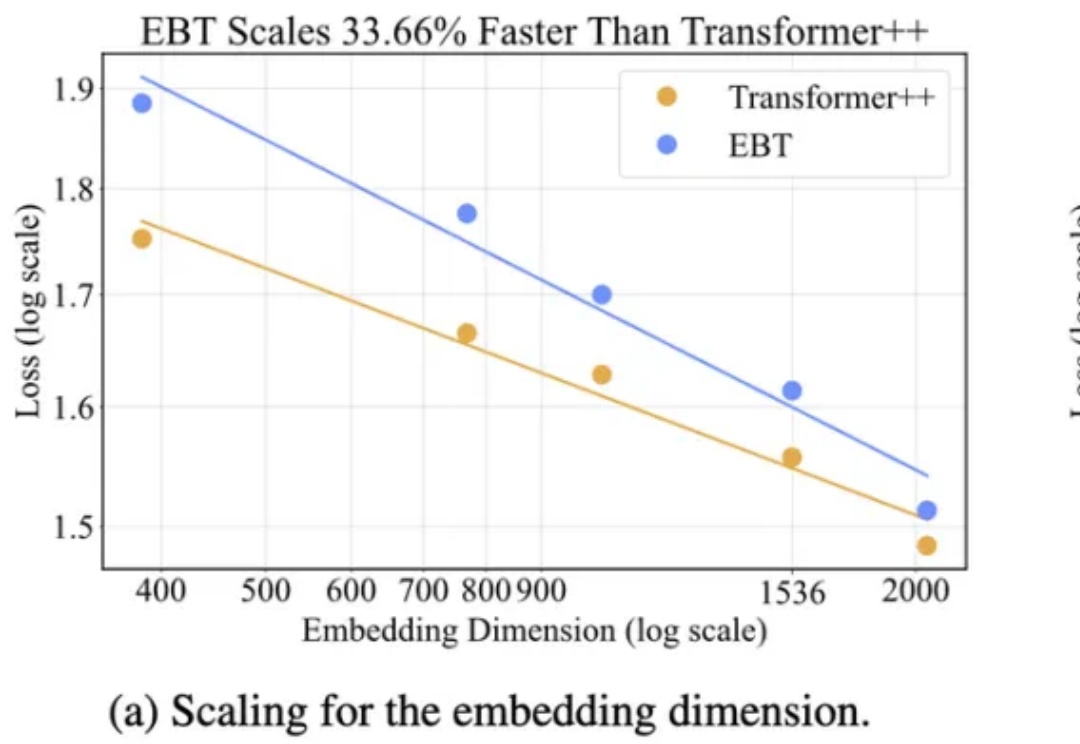
AI无需监督就能学习思考?
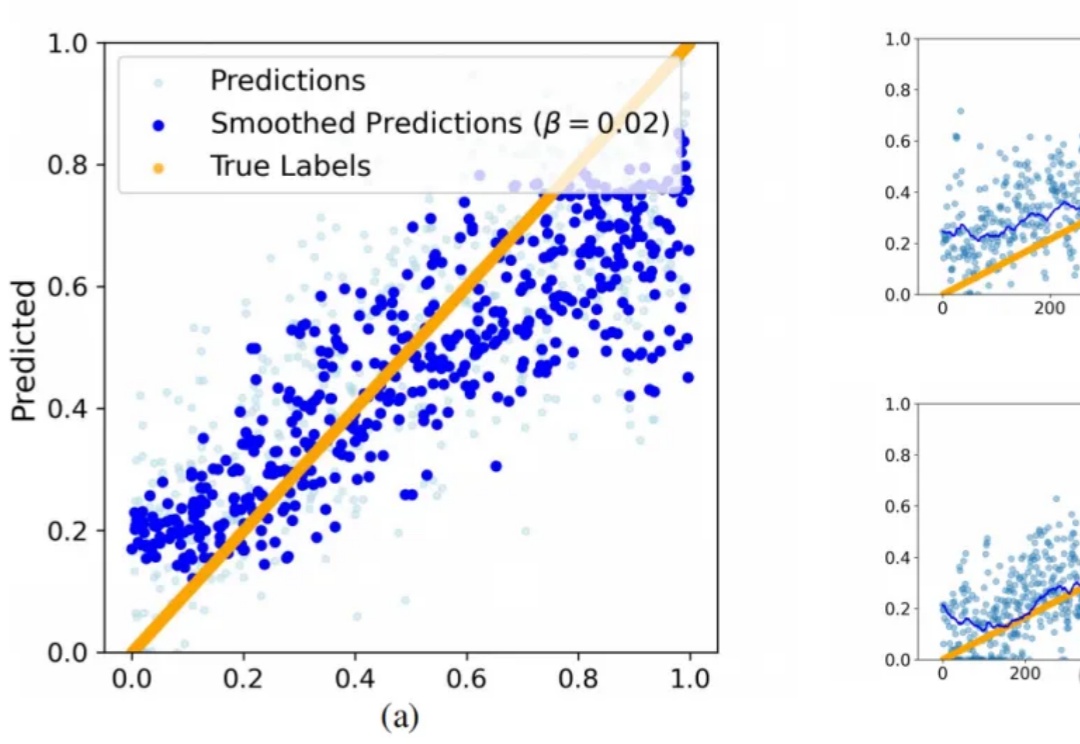
DeepSeek推理要详细还是要迅速,现在可以自己选了?
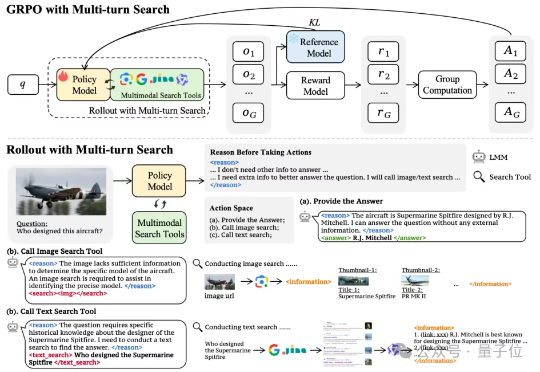
多模态模型学会“按需搜索”!字节&NTU最新研究,优化多模态模型搜索策略——通过搭建网络搜索工具、构建多模态搜索数据集以及涉及简单有效的奖励机制,首次尝试基于端到端强化学习的多模态模型自主搜索训练。
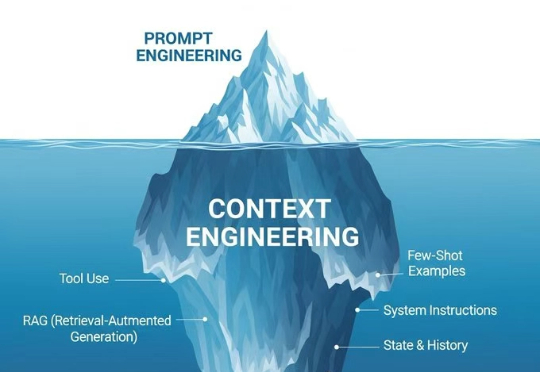
就像是播放音乐,Prompt Engineering是在调音响的音量,那Context Engineering就是在设计整个音响系统,从音源、功放、音箱到房间声学,每个环节都要精心设计。Context Engineering本质上是设计和优化AI模型整个上下文窗口的工程学科。这不只是一个技术升级,更像是思维模式的根本转变。