
「Tokens是胡扯」,Mamba作者抛出颠覆性观点,揭露Transformer深层缺陷
「Tokens是胡扯」,Mamba作者抛出颠覆性观点,揭露Transformer深层缺陷「Tokenization(分词)是 Transformer 模型为弥补自身缺陷不得不戴上的枷锁。」
来自主题: AI技术研报
7631 点击 2025-07-10 13:16
 搜索
搜索
「Tokenization(分词)是 Transformer 模型为弥补自身缺陷不得不戴上的枷锁。」

LLM用得越久,速度越快!Emory大学提出SpeedupLLM框架,利用动态计算资源分配和记忆机制,使LLM在处理相似任务时推理成本降低56%,准确率提升,为AI模型发展提供新思路。

自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。
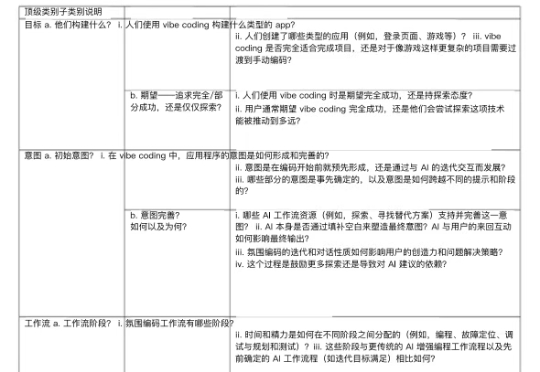
编者按:vibe coding不是编程的终点,而是Context Engineering驱动的协作智能的起点。那些能够最早理解并应用这种整合视角的人,将在下一轮技术变革中获得决定性优势。
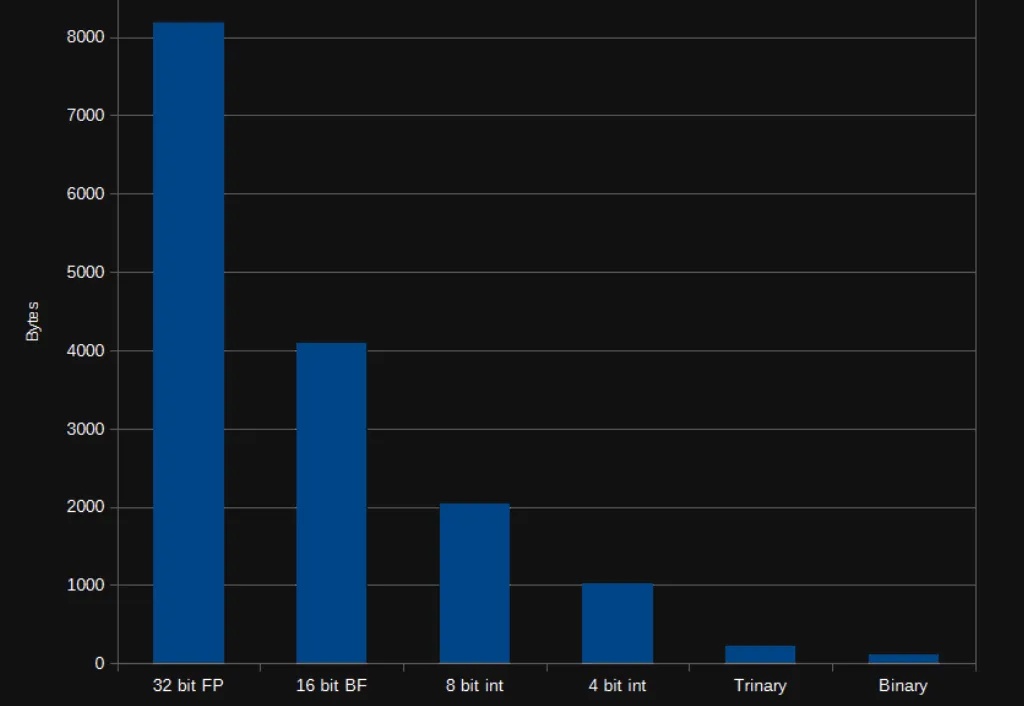
在 AI 领域,我们对模型的期待总是既要、又要、还要:模型要强,速度要快,成本还要低。但实际应用时,高质量的向量表征往往意味着庞大的数据体积,既拖慢检索速度,也推高存储和内存消耗。
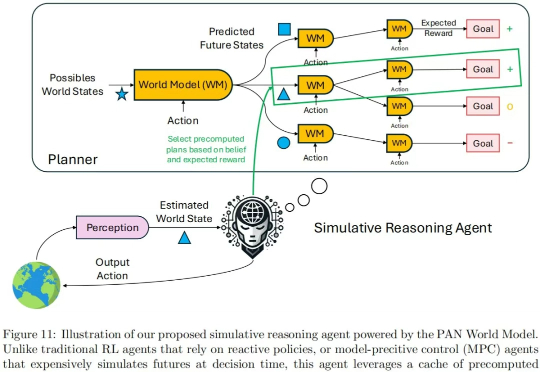
现在的世界模型,值得批判。 我们知道,大语言模型(LLM)是通过预测对话的下一个单词的形式产生输出的。由此产生的对话、推理甚至创作能力已经接近人类智力水平。
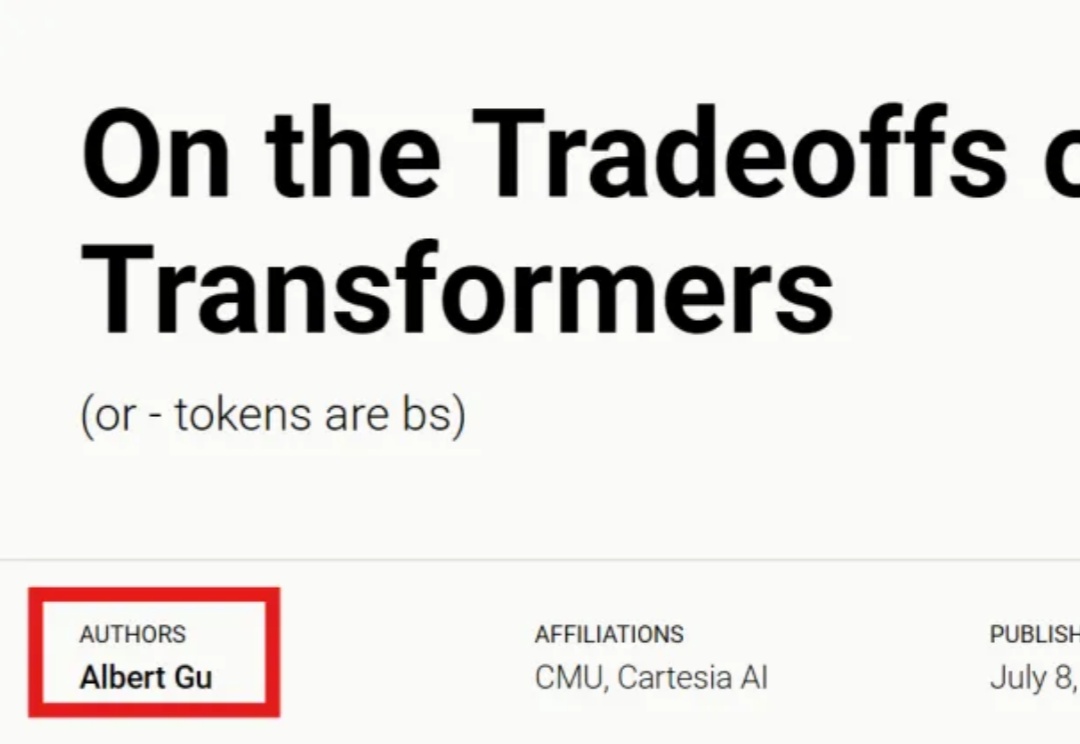
Mamba一作最新大发长文! 主题只有一个,即探讨两种主流序列模型——状态空间模型(SSMs)和Transformer模型的权衡之术。
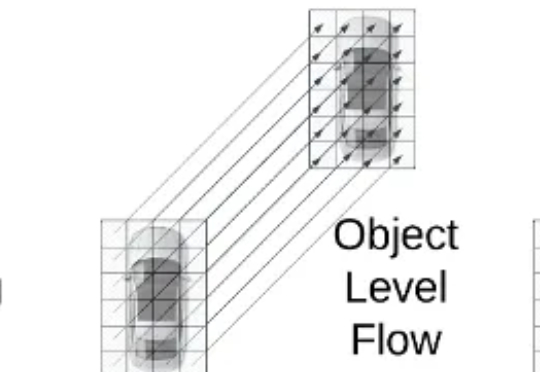
来自加州大学河滨分校(UC Riverside)、密歇根大学(University of Michigan)、威斯康星大学麦迪逊分校(University of Wisconsin–Madison)、德州农工大学(Texas A&M University)的团队在 ICCV 2025 发表首个面向自动驾驶语义占用栅格构造或预测任务的统一基准框架 UniOcc。

论文提出一种AI自我反思方法:通过反思错误原因、重试任务、奖励成功反思来优化训练。
ChatGPT的对话流畅性、Gemini的多模态能力、DeepSeek的长上下文分析……