OpenAI去年挖的坑填上了!奖励模型首现Scaling Law,1.8B给70B巨兽上了一课
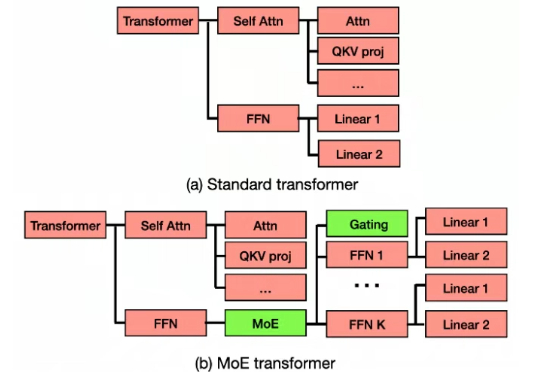
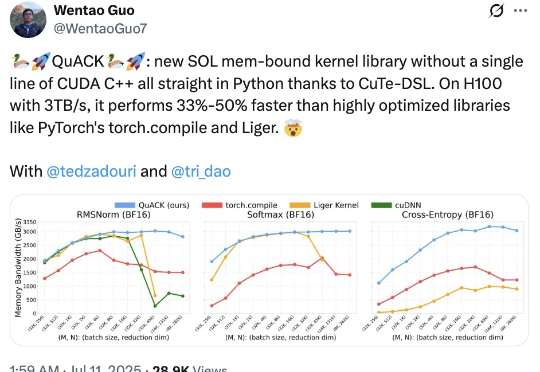
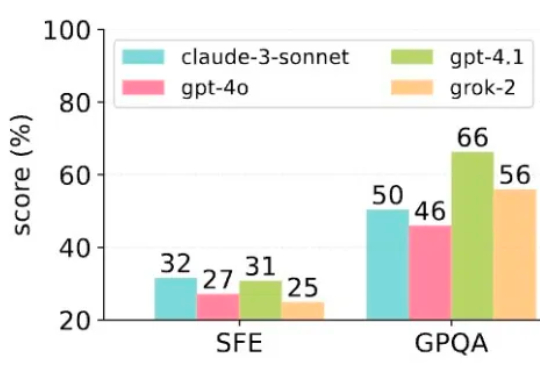
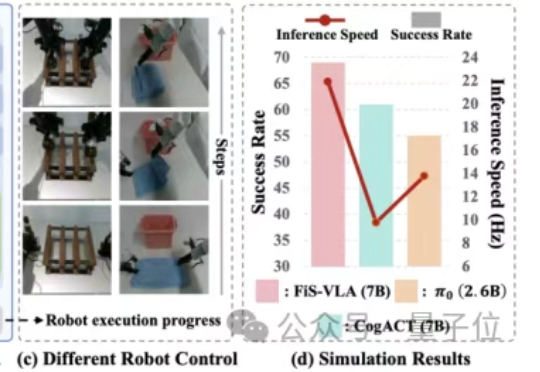
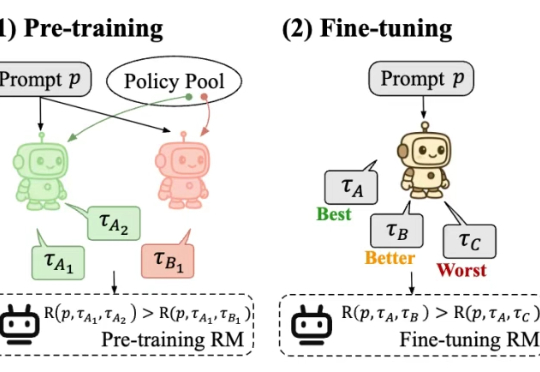
OpenAI去年挖的坑填上了!奖励模型首现Scaling Law,1.8B给70B巨兽上了一课最近,一款全新的奖励模型「POLAR」横空出世。它开创性地采用了对比学习范式,通过衡量模型回复与参考答案的「距离」来给出精细分数。不仅摆脱了对海量人工标注的依赖,更展现出强大的Scaling潜力,让小模型也能超越规模大数十倍的对手。
来自主题: AI技术研报
8293 点击 2025-07-11 16:30