# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
即使最强大的 LLM 也难以通过 token 索引来关注句子等概念,现在有办法了。
最近两天,马斯克和 LeCun 的口水战妥妥成为大家的看点。这两位 AI 圈的名人你来我往,在推特(现为 X)上相互拆对方台。

LeCun 在宣传自家最新论文时,也不忘手动 @ 一把马斯克,并意味深长地嘱咐道:「马斯克,我们这项研究用来改善你家的 Grok 也没问题。」
LeCun 宣传的这篇论文题目为《 Contextual Position Encoding: Learning to Count What’s Important 》,来自 Meta 的 FAIR。
骂战归骂战,这篇论文的重要性不言而喻。短短 24 小时之内就成为了 AI 领域最热门的论文之一。它有望解决如今大模型(LLM)最让人头疼的问题。

论文地址:https://arxiv.org/pdf/2405.18719
总的来说,该研究提出了一种新的用于 transformer 的位置编码方法 CoPE(全称 Contextual Position Encoding),解决了标准 transformer 无法解决的计数和复制任务。传统的位置编码方法通常基于 token 位置,而 CoPE 允许模型根据内容和上下文来选择性地编码位置。CoPE 使得模型能更好地处理需要对输入数据结构和语义内容进行精细理解的任务。文章通过多个实验展示了 CoPE 在处理选择性复制、计数任务以及语言和编码任务中相对于传统方法的优越性,尤其是在处理分布外数据和需要高泛化能力的任务上表现出更强的性能。
CoPE 为大型语言模型提供了一种更为高效和灵活的位置编码方式,拓宽了模型在自然语言处理领域的应用范围。
有网友表示,CoPE 的出现改变了在 LLM 中进行位置编码的游戏规则,此后,研究者能够在一个句子中精确定位特定的单词、名词或句子,这一研究非常令人兴奋。
这篇论文主要讲了什么,我们接着看。
许多常见的数据源(例如文本、音频、代码)都是顺序序列(ordered sequences)。在处理此类序列时,顺序(ordering)信息至关重要。对于文本,位置信息不仅对于解码单词之间的含义至关重要,而且在其他尺度(例如句子和段落级别)上都是必需的。
作为当前大型语言模型 (LLM) 的主要支柱 Transformer 架构,依赖于注意力机制,而这种机制本身就缺乏顺序信息,因此,需要一种额外的机制来编码数据的位置信息。
先前有研究者提出了位置编码(PE,Position encoding),该方法通过为每个位置分配一个嵌入向量,并将其添加到相应的 token 表示中来实现这一点。然而,当前的位置编码方法使用 token 计数来确定位置,因此无法推广到更高层次如句子。
为了将位置与更具有语义的单元(如单词或句子)联系起来,需要考虑上下文。然而,使用当前的位置编码方法无法实现这一点,因为位置寻址是独立于上下文计算的,然后再与上下文寻址合并。
Meta 认为,位置与上下文寻址的这种分离是问题的根本所在,因此他们提出了一种新的 PE 方法,即上下文位置编码( CoPE ),将上下文和位置寻址结合在一起。
方法介绍
CoPE 首先使用上下文向量确定要计数的 token。具体来说,给定当前 token 作为查询向量,接着使用先前 token 的键向量计算一个门值(gate value)。然后汇总这些门值,以确定每个 token 相对于当前 token 的相对位置,如图 1 所示。
与 token 位置不同,上下文位置可以取分数值,因而不能具有指定的嵌入。相反,该研究插入赋值为整数值的嵌入来计算位置嵌入。与其他 PE 方法一样,这些位置嵌入随后被添加到键向量中,因此查询向量可以在注意力操作中使用它们。由于上下文位置可能因查询和层而异,因此该模型可以同时测量多个单元的距离。
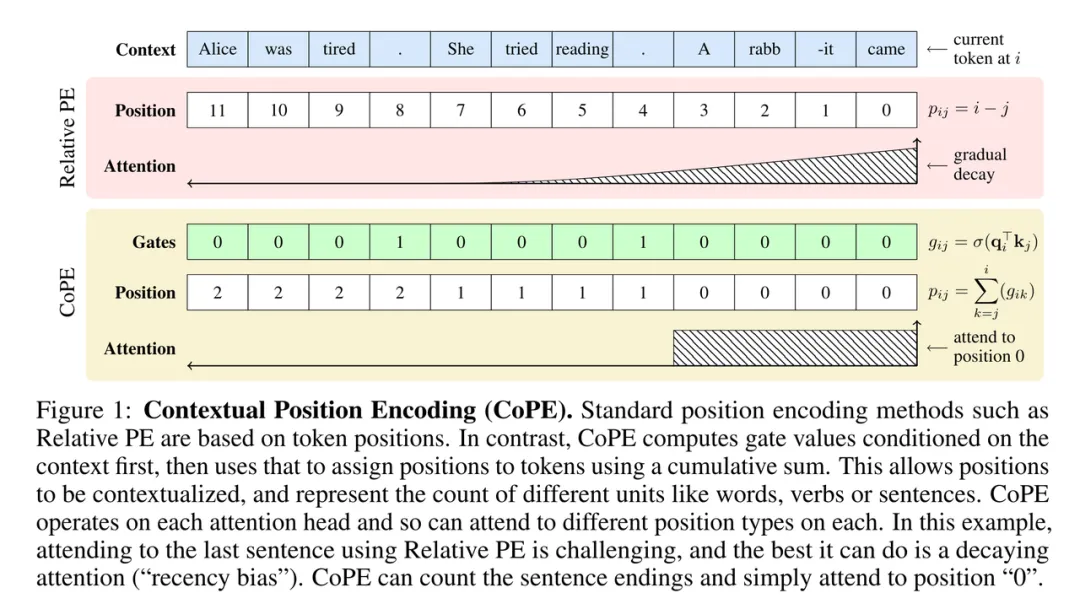
在 CoPE 中,位置是通过上下文相关的方式来测量的,而不是简单的 token 计数。该方法的工作原理是首先决定在使用上下文向量测量距离时应包含哪些 token。因此,对每个查询 q_i 和键 k_j 对计算门值

其中 j < i 且 σ 是 sigmoid 函数。门值为 1 表示该键将被计入位置测量中,而 0 表示将被忽略。例如,要计算 token i 和 j 之间的句子,仅对于诸如 “.” 之类的句子分隔 token,门值应为 1。门以查询为条件,如果需要,每个查询可以有不同的位置测量。软门控函数(soft gating function)允许微分,以便可以通过反向传播来训练系统。
然后,该研究通过添加当前 token 和目标 token 之间的门值来计算位置值。
值得注意的是,如果门值始终为 1,则 p_ij = i − j + 1 ,并且恢复基于 token 的相对位置。因此,CoPE 可以被视为相对 PE 的泛化。然而,一般来说,p_ij 可以是特定单词或单词类型(如名词或数字)的计数、句子的数量或 Transformer 认为在训练期间有用的其他概念。
与 token 位置不同,位置值 p_ij 不限于整数,并且因为 sigmoid 函数的原因可以采用小数值。这意味着不能像相对 PE 中那样使用嵌入层将位置值转换为向量。
首先,该研究为每个整数位置 p ∈ [0, T] 分配一个可学习的嵌入向量 e [p],那么位置 p_ij 的嵌入将是两个最接近的整数嵌入的简单插值。
最后,计算类似于如下等式的注意力权重。
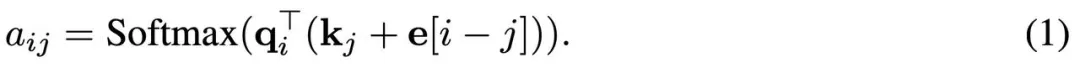
然而,在实践中,计算和存储向量 e [p_ij ] 需要使用额外的计算和内存。该研究通过首先计算所有整数位置 p 的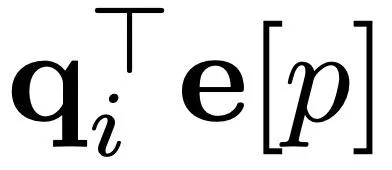 乘法,再对结果值进行插值来提高效率:
乘法,再对结果值进行插值来提高效率:
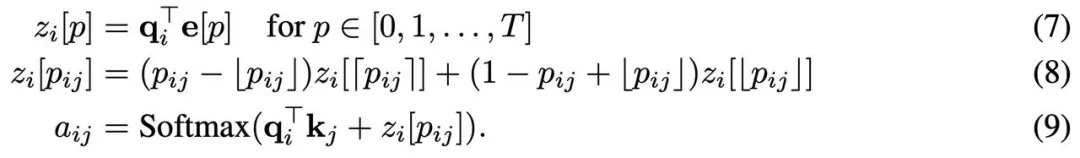
如下方程 (4) 所示,p_ij 的最大值是上下文大小 T,这意味着需要 T + 1 个位置嵌入(包括位置 0)。然而,如果门被稀疏激活(例如计算句子),则可以用更少的位置覆盖整个上下文 T。因此,该研究通过设置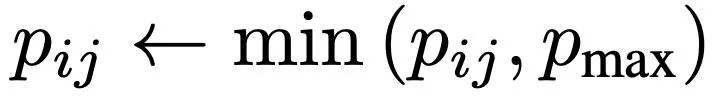 ,使得最大可能位置 p_max < T。
,使得最大可能位置 p_max < T。

CoPE 的多头扩展非常简单,因为每个头都会独立执行自己的 CoPE。头之间的键和查询向量是不同的,这意味着它们可以实现不同的位置测量。
实验结果
Flip-Flop 任务
Liu 等人 [2024] 提出了 Flip-Flop 语言建模任务,以揭示 Transformer 模型无法在长距离输入序列上进行稳健推理。
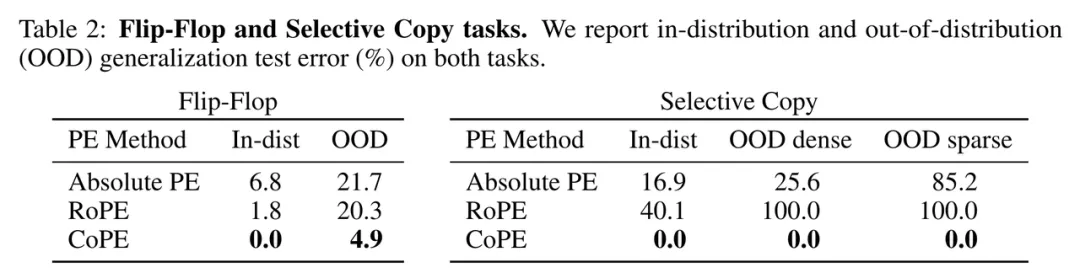
结果如表 2(左)所示。结果表明,CoPE 优于现有方法,使模型不仅可以学习分布内任务,还可以推广到 OOD 序列 —— 这是现有 PE 方法无法提供的属性。
选择性复制任务
Gu 和 Dao [2023] 提出的选择性复制任务需要上下文感知推理才能进行选择性记忆。
表 2(右)中给出的结果显示,在分布内测试集上,新方法 CoPE 可以解决该任务,而其他方法则无法解决。同样的,CoPE 在密集和稀疏 OOD 测试集上都具有更好的泛化能力。空白 token 的存在使得找到下一个要复制的 token 变得更加困难,但 CoPE 只能计算非空白 token,因此更加稳定。在每个步骤中,它可以简单地复制距离为 256(非空白)的非空白 token。重复此操作 256 次将复制整个非空白序列。
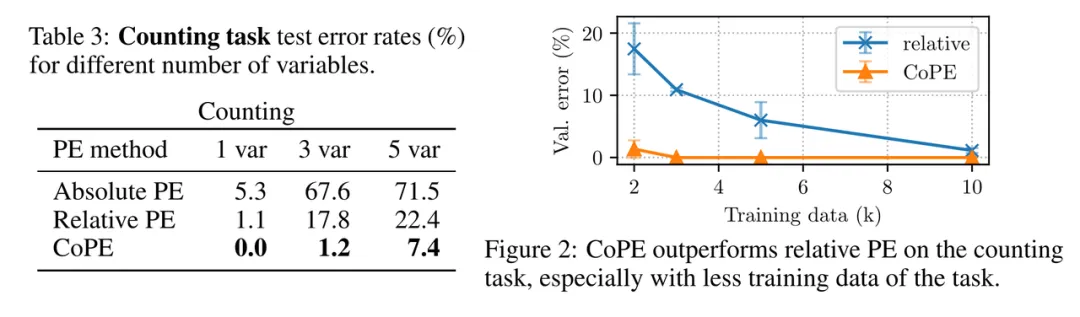
计数任务
计数比简单地回忆上一个实例更具挑战性,因为它需要在一定范围内更均匀的注意力。
结果见表 3 和图 2。具有相对 PE 的基线模型很难学习此任务,尤其是当有多个变量需要跟踪时。绝对 PE 的表现更差。最佳表现来自 CoPE,在 1 个变量的情况下获得满分。对于 OOD 泛化,相对 PE 表现出较差的泛化能力,而 CoPE 的泛化能力非常好,如表 4 所示。有关这些实验的标准差,请参见附录表 9。
语言建模
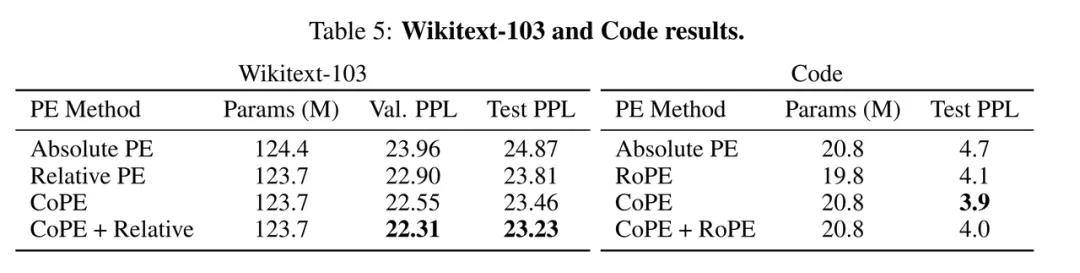
为了在语言建模任务上测试新方法,研究人员使用了 Wikitext-103 数据集,该数据集包含从 Wikipedia 中提取的 1 亿个 token。
表 5(左)中比较了不同的 PE 方法:绝对 PE 表现最差,CoPE 优于相对 PE,与相对 PE 结合使用时效果更佳。这表明,即使在一般语言建模中,CoPE 也能带来改进。
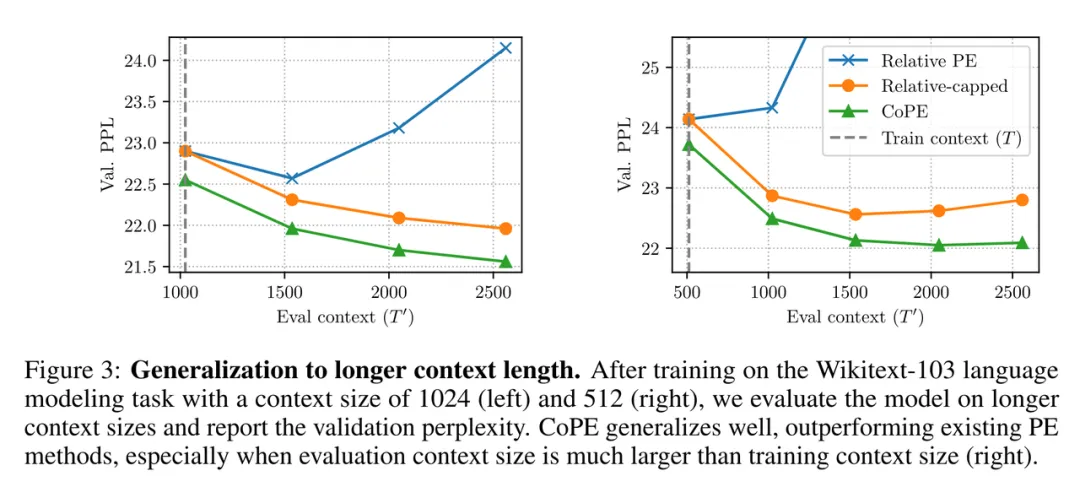
接下来,作者测试了 CoPE 推广到比训练上下文更长的上下文的效果。
结果如图 3 所示。相对 PE 推广到更长的上下文效果不佳。相比之下,相对上限版本的表现要好得多。然而 CoPE 的表现仍然优于它,当测试上下文比训练上下文长得多时,差距会扩大(见图 3 右)。
如图 4 所示,作者展示了使用 sep-keys 训练的模型的注意力图示例(gate 是用分离的键计算的)。注意力图仅根据位置构建(它们必须与上下文注意力相乘才能得到最终的注意力),这能让我们更好地了解 CoPE 正在做什么。作者还进行了归一化,以便每个查询的最大注意力权重始终为 1。首先,我们可以看到位置明显具有上下文相关性,因为无论它们的相对位置如何,注意力都倾向于落在特定的 token 上。
仔细观察这些 token 会发现,注意力主要集中在最后一段(左)或部分(右)上。为清楚起见,实际的段落和部分边界用黑色加号标记。在 CoPE 中,这是可能的,因为一个注意力头可以计数段落,而另一个注意力头计数部分,然后它可以只关注位置 0。

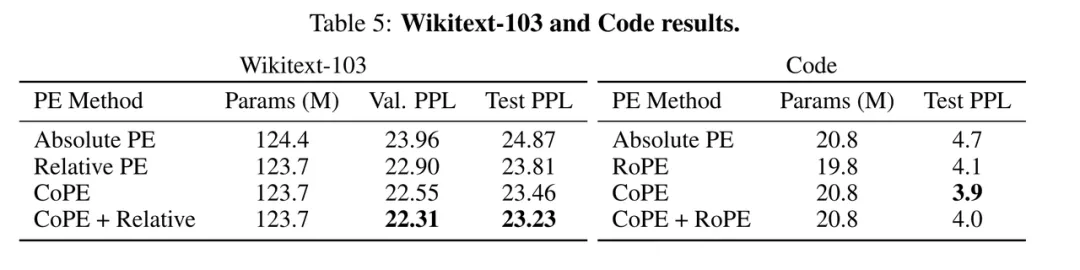
代码建模
作者通过对代码数据进行评估来进一步测试 CoPE 的能力。与自然语言相比,代码数据具有更多的结构,并且可能对上下文学习更敏感。
结果总结在表 5(右)中。CoPE 嵌入的困惑度比绝对 PE 和 RoPE 分别提高了 17% 和 5%。将 RoPE 和 CoPE 嵌入结合在一起可以改善 RoPE,但不会比所提出的嵌入方法带来任何改进。
文章来源于“机器之心”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
