
VAST+清华提出3D生成新范式,空间智能密度控制「把算力花在刀刃上」| SIGGRAPH 2026
VAST+清华提出3D生成新范式,空间智能密度控制「把算力花在刀刃上」| SIGGRAPH 2026如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。
来自主题: AI技术研报
6940 点击 2026-05-21 16:08
 搜索
搜索
如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。
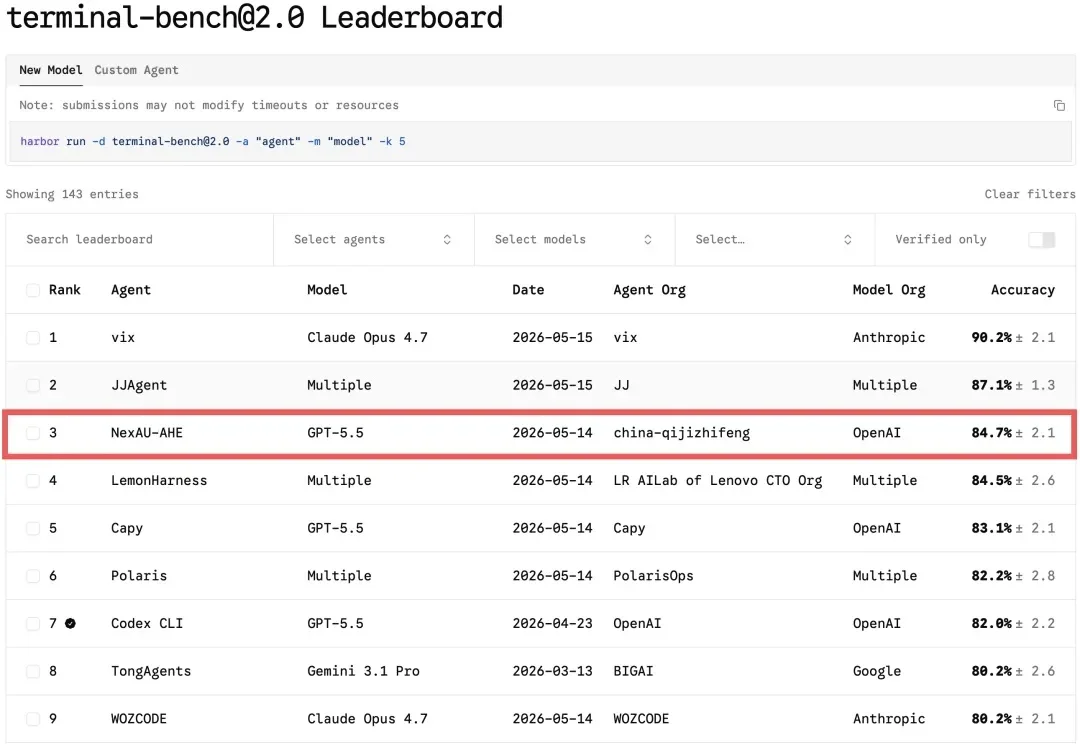
2026 年以来,OpenAI、Anthropic、LangChain 等机构纷纷发布关于 Harness Engineering 的技术博客,OpenClaw、Hermes Agent 等项目的火爆更让 Harness Engineering 成为业界热词。人们的共识正在形成:模型的能力释放,依赖于一套精密的外部框架。
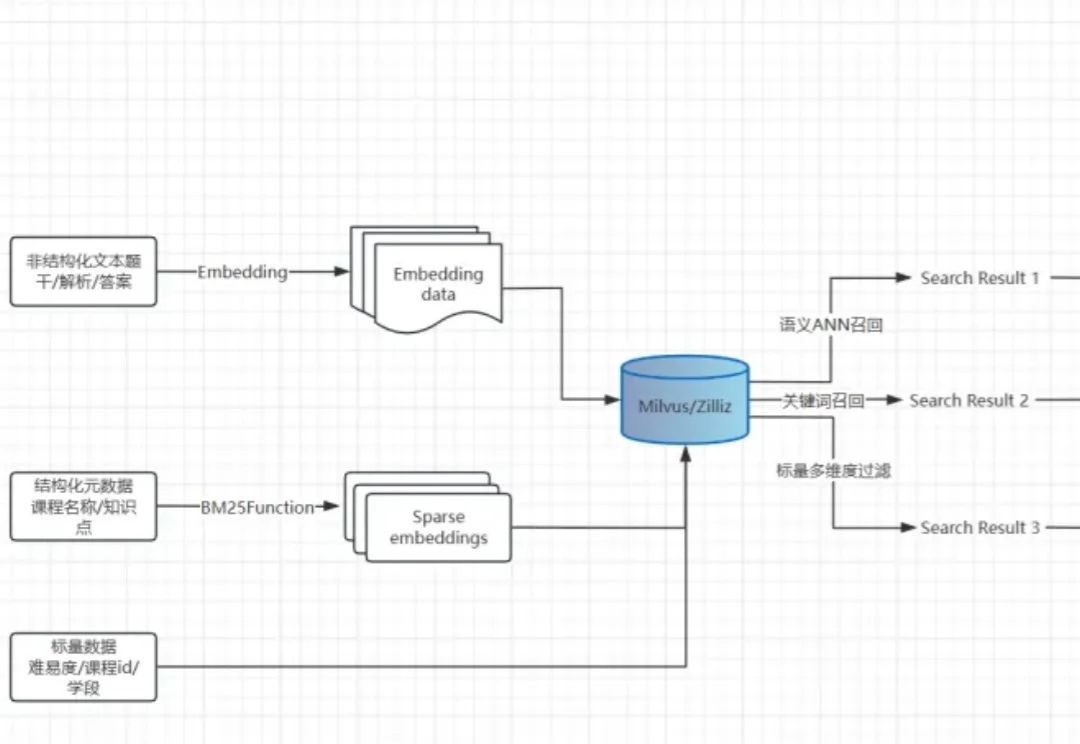
在教育科技领域,题库是核心资产,更是连接学生、教师与知识体系的关键入口。
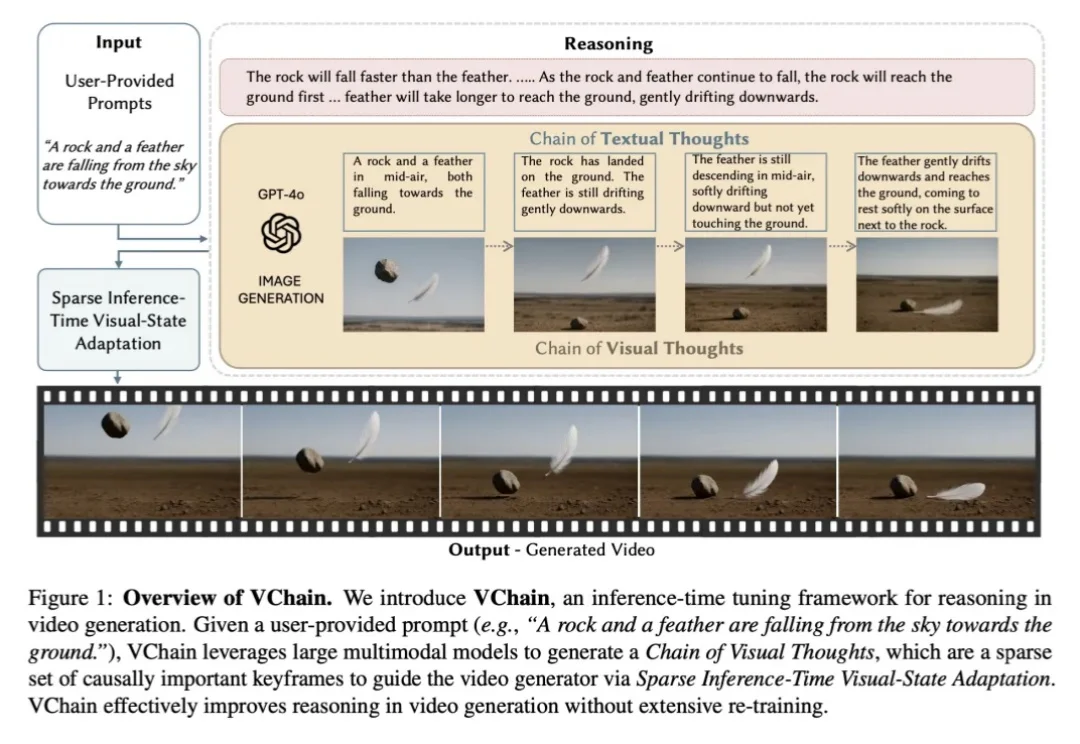
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?
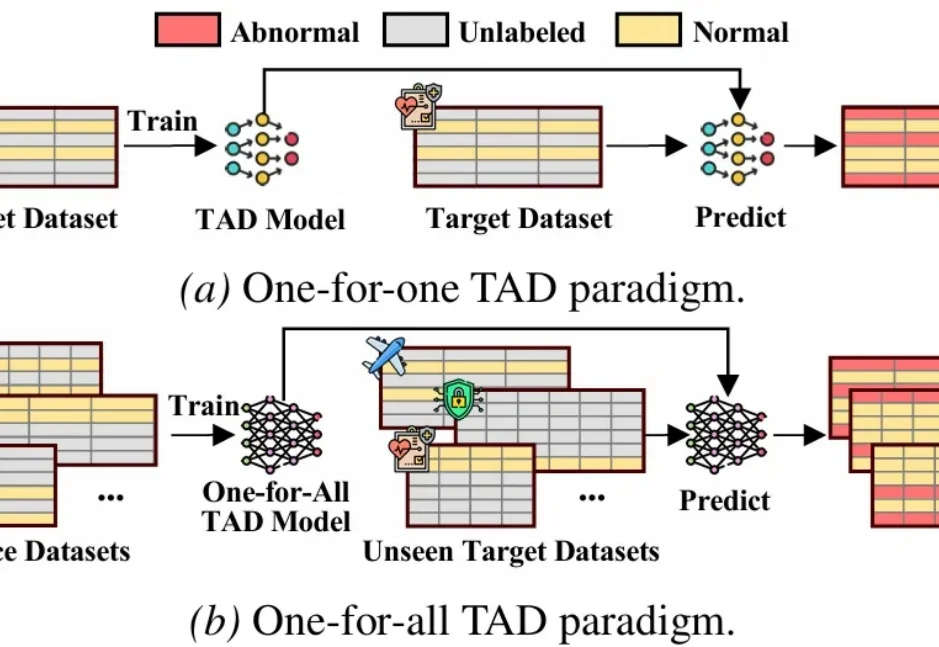
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。

近日,谷歌 DeepMind 研究员 Lun Wang@lunwang1996,在 x 上发文宣布自己已经从 DeepMind 离职,结束了这段非常精彩的旅程,「我非常感谢曾经共事的人、我们一起打造的东西,以及我在将前沿 AI 研究推向生产环境过程中学到的经验。」

奥赛级科学推理,一定要从更大的通用模型开始吗?
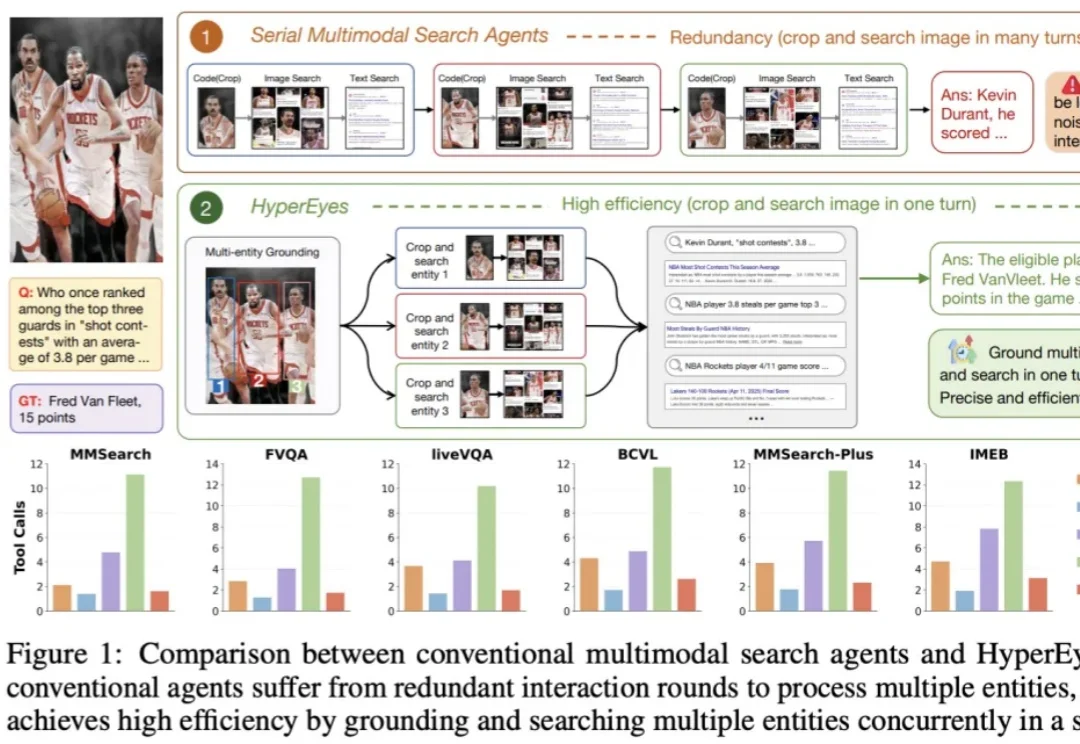
现有的开源多模态搜索智能体普遍受困于「裁剪 - 再搜索」的串行处理模式,面对多目标时往往陷入交互冗长、错误级联累积的泥沼。

攻克AI落地难题,清华团队推出RWAI框架与真实场景竞技场,通过标准化人机交互、任务集机制与人类反馈体系,显著提升产业应用效率。平台已实现落地周期缩短70%以上,并为AI开发者和企业提供了可复制的最佳实践。
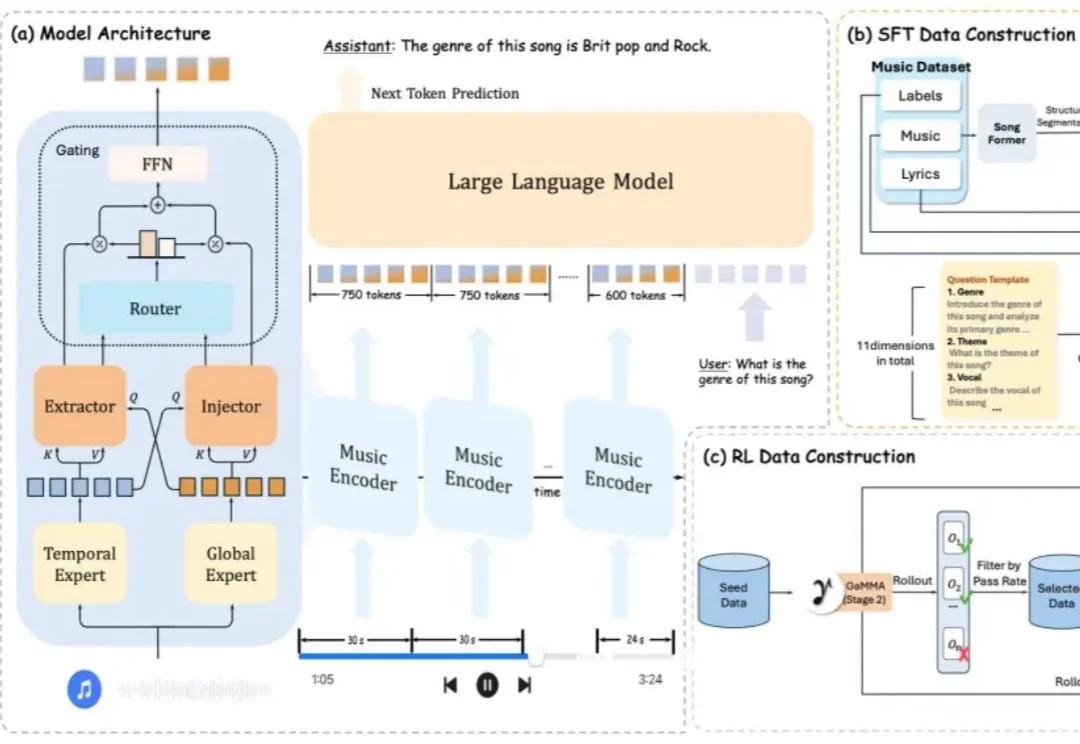
大模型的能力边界正在不断拓展,从文字到视觉,再到音频,全模态理解已渐成现实。然而,当你问一个多模态大模型「这首歌的高潮从第几秒开始?」或者「第 30 秒之后乐器编配发生了什么变化?」,得到的往往是一个模糊甚至错误的回答。